{piggyback} - For storing files as GitHub release assets, which is a convenient way for large/binary data files to piggyback onto public and private GitHub repositories.
Focuses on providing a complete solution with sensible defaults, while still giving the knowledgeable user precise control over all the step
Designed to be transparent, so you can inspect outputs at intermediate steps
{rdocdump} - Dump source code, documentation and vignettes of R packages into a single file. Supports installed packages, tar.gz archives, and package source directories
The output is a single plain text file or a ‘character’, which is useful to ingest complete package documentation into a large language model (‘LLM’) or pass it further to other tools, such as {ragnar} to create a Retrieval-Augmented Generation (RAG) workflow.
{RAGFlowChainR} - Brings Retrieval-Augmented Generation (RAG) capabilities to R, inspired by LangChain. It enables intelligent retrieval of documents from a local vector store (DuckDB), enhanced with optional web search, and seamless integration with Large Language Models (LLMs).
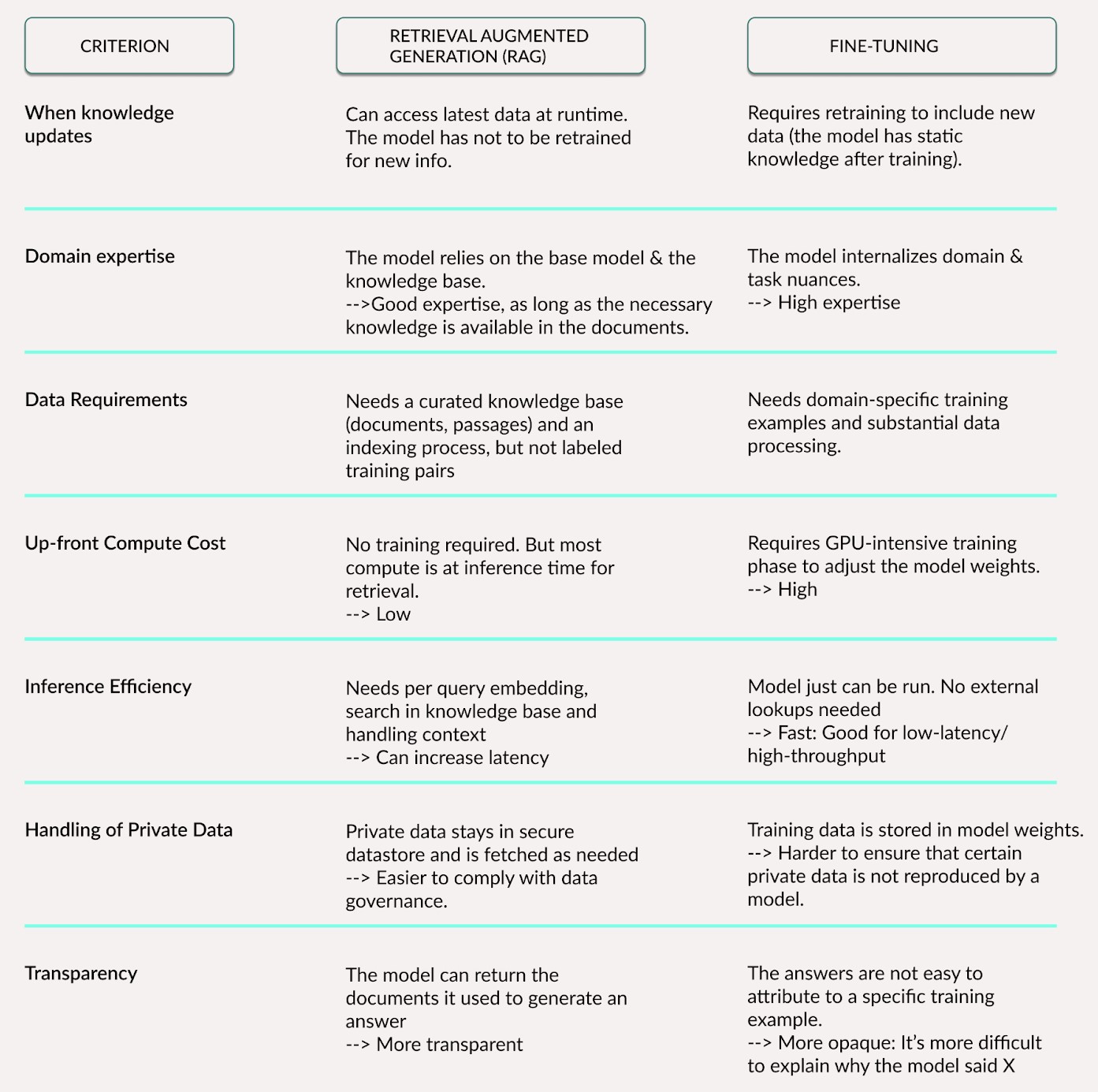
Source Citation: Access to sources enhances the transparency of the responses
Reduces Hallucinations
Good for domain-specific data
Large context windows in LLMs are super useful, but they are not a substitute for a good RAG solution.
When you compare the complexity, latency, and cost of passing a massive context window versus retrieving only the most relevant snippets, a well-engineered RAG system remains necessary
Cons
Latency: Response times can be problematic for real-time applications
An external knowledge base is required
It’s a huge infrastructure project.
The moment you start stressing your system with real evolving data in production, the weaknesses in your pipeline will begin to surface.
Questions
ROI: How much time will this actually save in concrete workflows, and not just based on abstract metrics presented in slides?
As with all data projects, it shouldn’t be attempted unless it will return business value (e.g. time saved, efficiency gained, or costs reduced).
Business Question: RAG systems mostly fail because of a business problem it’s supposed to solve hasn’t been concisely defined
Help HR respond to policy questions without endless back-and-forth
Give developers instant, accurate access to internal documentation while they’re coding
A narrowly scoped onboarding assistant for the first 30 days of a new hire
Architectures
Most business problems are best solved with a Basic RAG or a Two-Step RAG architecture
Types
Monolithic (Basic) RAG: Start here. If your users’ queries are straightforward and repetitive (“What is the vacation policy?”), a simple RAG pipeline that retrieves and generates is all you need.
Two-Step Query Rewriting: Use this when the user’s input might be indirect or ambiguous. The first LLM step rewrites the user’s ambiguous input into a cleaner, better search query for the VectorDB.
Agentic RAG: Only consider this when the use case requires complex reasoning, workflow execution, or tool use (e.g., “Find the policy, summarize it, and then draft an email to HR asking for clarification”).
Data Quality
If your source data isn’t meticulously prepared, your entire system will struggle. (garbage in, garbage out)
Pooling raw data directly into their vector database (VectorDB) quickly becomes a sandbox where the only retrieval mechanism is an application based on cosine similarity. While it might pass your quick internal tests, it will almost certainly fail under real-world pressure.
Data preparation needs its own pipeline with tests and versioning steps. This means cleaning and preprocessing your input corpus. No amount of clever chunking or fancy architecture can fix fundamentally bad data.
Updating Vector DBs
A computationally intensive operation, very time-consuming, and can easily lead to a situation of downtime or inconsistencies if not treated with care. But not to be skipped!
Every time you update a single document, you don’t simply change a couple of fields but may well have to re-chunk the whole document, generate new large vectors, and then wholly replace or delete the old ones.
Embedding versioning, or keeping track of which documents are associated with which run for generating a vector, is a good practice.
When do you have to re-embed the corpus?
The best approach is to have your system automatically re-embed, but not based on some empirical basis (e.g. a specific number of changes to the data).
Example: HR System
Re-embed after a major version release of internal rules
Re-embed if the domain itself changes significantly (for example, in case of some major regulatory shift)
When you send embeddings to a vector DB, it doesn’t just “store” them. It builds an index that speeds up similarity searches. That indexing work is where a lot of the magic comes from, and also where a lot of the cost lives.
In a long-lived, large-scale knowledge base, this trade-off makes perfect sense: you pay an indexing cost once (or incrementally as data changes), and then spread that cost over millions of queries.
Vector DB
Best for large-scale, persistent knowledge bases
Key-Value Store
Best use for dynamic or time-sensitive use cases
When the data is ephemeral, the user will ask only a few questions, and we want to answer them as fast as possible
Every time we receive a request, we generate fresh embeddings for short-lived data that we’ll likely query only a few hundred times.
Example: A user uploads a few text files, maybe some reports or meeting notes. The user asks a handful of questions over the next few minutes, then leaves. At that point, both the files and their embeddings are useless and can be safely discarded.
Example: Answer insurance-related questions about businesses
Input a business name and address
Retrieve real-time data about that specific business, including its online presence, registrations, and other public records. This data becomes our context
LLMs and algorithms to answer questions based on it.
Process
Receive a request
Create and store the embeddings in a database (e.g. Redis)
Run a quick similarity search in the application code with almost no indexing delay.
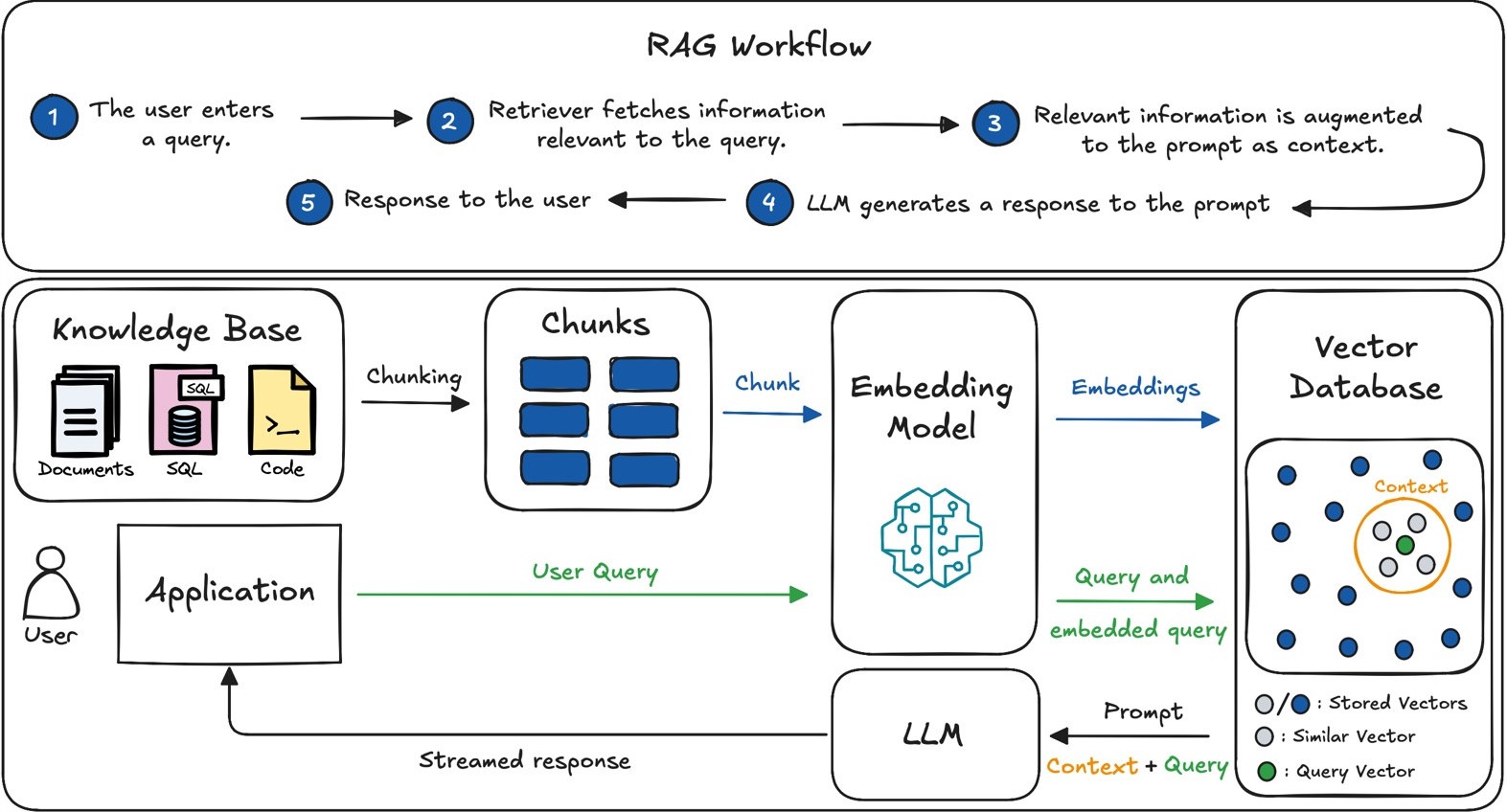
Chunking
Breaking down a source document, perhaps a PDF or internal document, into smaller chunks before encoding it into vector form and storing it within a database
The essence of chunking is to pick out the single most relevant bit of information that will answer the user’s question and transmit only that bit to the LLM
LLMs have a limited number of tokens
Too large of a chunk overload an agent with too much irrelevant information.
Too small, you risk giving the LLM too little context.
Avoid naive strategies
Without smart rules, chunks become fragments rather than entire concepts. The result is pieces that slowly drift apart and become unreliable
Includes token limits, character counts, or rough paragraphs
Semantic Chunking breaks up text into meaningful pieces, not just random sizes.
The goal is to make sure that every chunk represents a single complete idea
Methods
Recursive Splitting: Break text based on structural delimiters (e.g., sections, headers, then paragraphs, then sentences).
Sentence Transformers: This uses a lightweight and compact model to identify all important transitions based on semantic rules in order to segment the text at those points.
See LangChain’s advanced recursive modules and research articles on topic segmentation.
Retrieval
Often benefits from hybrid search (supported by both Qdrant and LlamaIndex), although it may not be enough.
Semantic search can connect things that answer the question without using the exact wording,
Sparse methods can identify exact keywords. But sparse methods like BM25 are token-based by default, so plain BM25 won’t match substrings.
If you also want to search for substrings (part of product IDs, that kind of thing), you need to add a search layer that supports partial matches as well.
Evaluation
Usually starts during development, you will need it at every stage of the AI product lifecycle
The best evaluations include metrics for each part of the system separately (i.e. how you chunk and store your documents, to embeddings, retrieval, prompt format, and the LLM version)
Include business metrics to assess how the entire system performs end to end.