H2O
Misc
Resources
- Docs
- Function Reference
- Algorithms
- Awesome H2O - Curated list of resources
Packages
- {h2otools} - Provides additional functions for model performance evaluation that are not implemented in h2o
Also see
- {forester} (Paper) - AutoML solution using tree models (From DrWhy.AI people)
- Models for binary, multiclass classification, and regression tasks conducted on tabular data, as well as partial support for survival analysis task
- Decision Trees from {partykit}, RF from {ranger}, XGBoost, LightGBM, and CatBoost
- Survival RF from {randomForestSRC}
- Tunes using random search or Bayesian Optimization
- Metrics
- Classificaition: AUROC, Balanced Accuracy, F1, confusion matrix stats
- Regression: MSE, RMSE, MAE, R2
- Survival: Brier Score, C-Index
- Supports custom metrics
- Automatically conducts data preprocessing and preparation stages
- Imputation with MICE or KNN
- Provides meaningful, and well-explained report, which describes the outcomes of trained models, enriched by the elements of interpretability
- Uses DALEX
- Report contains basic information about the dataset, a data check report, a ranked list of the best ten (by default) models, and visualizations concerning model quality
- Feature selection options: Boruta, Mutual Information, Monte Carlo Feature Selection
- Models for binary, multiclass classification, and regression tasks conducted on tabular data, as well as partial support for survival analysis task
- {forester} (Paper) - AutoML solution using tree models (From DrWhy.AI people)
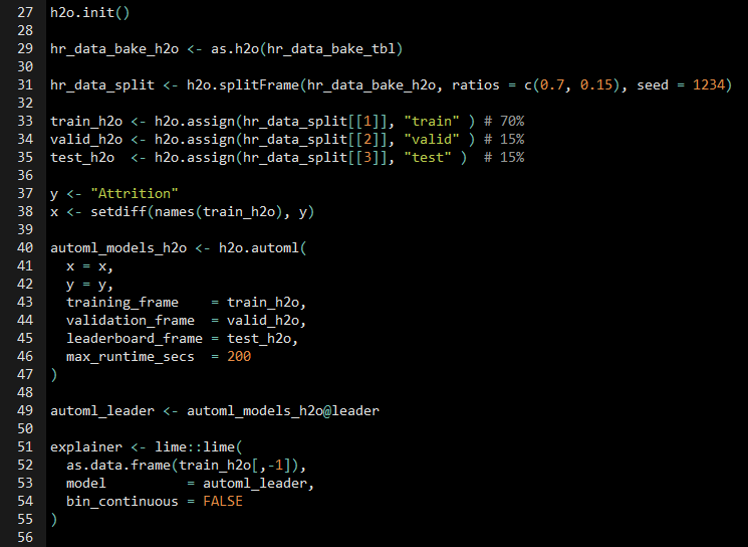
AutoML
The amount of ram needed on local machine equals four to five times the size of your data (usually) but really depends on max number of models to be trained.
Diagnostic metrics used in classification models are AUC, log loss, and mean per class error
Seems to use generic variable importance (mean decrease gini)
I think a glm was used to ensemble its models
In the binary classification example, the top models were “extremely randomized trees”, xgboost, and gbm.
Ensemble model reproducibility requires arguments: set seed and exclude_model = “DNN” (deep neural network)
Example: CV with LIME Explainer