General
Misc
- Packages
- {evoFE} - Automates feature engineering using evolutionary algorithms inspired by genetic programming. Starting from raw input features, the package evolves candidate transformation recipes through selection, crossover, and mutation, evaluating fitness via cross-validation or train/validation splits with gradient-boosted tree models (‘LightGBM’ or ‘XGBoost’).
- Built-in transformers include arithmetic, logarithmic, and power operations, interaction terms, target encoding, quantile and log-based binning, principal component analysis, truncated singular value decomposition, Uniform Manifold Approximation and Projection (UMAP) dimensionality reduction, and minimum spanning tree (MST) graph-based clustering.
- {evoFE} - Automates feature engineering using evolutionary algorithms inspired by genetic programming. Starting from raw input features, the package evolves candidate transformation recipes through selection, crossover, and mutation, evaluating fitness via cross-validation or train/validation splits with gradient-boosted tree models (‘LightGBM’ or ‘XGBoost’).
- Resources
- Tree-based Models
- From Uber, “Tree-based models are performing piecewise linear functional approximation, which is not good at capturing complex, non-linear interaction effects.”
- With regression models, you have to be careful about encoding categoricals as ordinal (i.e. integers) which means one-hot encoding is better.
- For example, the raw numerical encoding (0-24) of the “hour” feature prevents the linear model from recognizing that an increase of hour in the morning from 6 to 8 should have a strong positive impact on the number of bike rentals while a increase of similar magnitude in the evening from 18 to 20 should have a strong negative impact on the predicted number of bike rentals.
- Models with large numbers (100s) of features increases the opportunity for feature drift
- Zero-Inflated Predictors/Features
- For ML, transformations probably not necessary
- For regression
- log(x + 0.05)
- larger effect on skew than sqrt
- arcsinh(x) (see Continuous >> Transformations >> Logging)
- approximates a log but handles 0s
- sqrt maybe Yeo-Johnson (?)
- log(x + 0.05)
- >60% of values = 0, consider binning or binary
Continuous
Binning
- Also see
- EDA, General >> Packages >> Hmisc::describe
- Info gives a measure of how much information is lost by binning.
- Clustering, General
- EDA, General >> Packages >> Hmisc::describe
- Packages
- {binr} - Implementation of algorithms for cutting numerical values exhibiting a potentially highly skewed distribution into evenly distributed groups (bins)
- {cutpointr} - Uses CV and bootstrap in determining and validating optimal cutpoints in binary classification
- {optbinningR} - Optimal Binning Methods for Predictive Modeling and Analytics
- {smbinning} (article) - Requiress binary response. Optimal Binning for Scoring Modeling
- {santoku} - Functions create intervals in many ways, using quantiles of the data, standard deviations, fixed-width intervals, equal-sized groups, or pretty intervals for use in graphs
- Benefits
- Reduces Noise
- Continuous variables tend to store information with minute fluctuations that provide no added value for the machine learning task of interest
- Makes the feature more intuitive
- Is there an important threshold value?
- 1 value \(\rightarrow\) split into a binary
- multiple values \(\rightarrow\) multinomial
- Is there an important threshold value?
- Minimizes outlier influence
- Can help normalize heavily skewed data
- Reduces Noise
- Dichotomizing is bad (paper + discussion, post, list of papers)
- Typical arguments for splitting (even when there’s no underlying reason to do so) include: simplifies the statistical analysis and leads to easy interpretation and presentation of results
- Example: splitting at the median — leads to a comparison of groups of individuals with high or low values of the measurement, leading in the simplest case to a t test or χ2 test and an estimate of the difference between the groups (with its confidence interval) on another variable.
- Using multiple categories (to create an “ordinal” variable) is generally preferable , and using four or five groups the loss of information can be quite small
- Issues:
- Information is lost, so the statistical power to detect a relation between the variable and patient outcome is reduced.
- Dichotomising a variable at the median reduces power by the same amount as would discarding a third of the data
- May increase the risk of a positive result being a false positive
- May seriously underestimate the extent of variation in outcome between groups, such as the risk of some event, and considerable variability may be subsumed within each group.
- Individuals close to but on opposite sides of the cutpoint are characterised as being very different rather than very similar.
- Conceals any non-linearity in the relation between the variable and outcome
- Using a stat like median for a cutpoint means studies will have different cutpoints, therefore results cannot easily be compared, seriously hampering meta-analysis of observational studies
- An “optimal” cutpoint (usually that giving the minimum P value) runs a high risk of a spuriously significant result. Effect will be overestimated and the CI too narrow
- Adjusting for the effect of a confounding variable, dichotomisation will run the risk that a substantial part of the confounding remains
- Information is lost, so the statistical power to detect a relation between the variable and patient outcome is reduced.
- Typical arguments for splitting (even when there’s no underlying reason to do so) include: simplifies the statistical analysis and leads to easy interpretation and presentation of results
- Harrell
- Think most of these issues are related to inference models like types of logistic regression
- A better approach that maximizes power and that only assumes a smooth relationship is to use a restricted cubic spline (regression spline; piecewise cubic polynomial) function for predictors that are not known to predict linearly. Use of flexible parametric approaches such as this allows standard inference techniques (P -values, confidence limits) to be used (See Feature Engineering, Splines)
- Issues with binning continuous variables
- If cutpoints are chosen by trial and error in a way that utilizes the response, even informally, ordinary P -values will be too small and confidence intervals will not have the claimed coverage probabilities.
- The correct Monte-Carlo simulations must take into account both multiple tests and uncertainty in the choice of cutpoints.
- Using the “minimum p-value approach” often results in multiple cutpoints so ¯\_(ツ)_/¯ plus multiple testing p-value adjustments need to be used.
- This approach involves testing multiple cutpoints and choosing one that minimizes the p-value below a threshold.
- Optimal cutpoints often change from sample to sample
- The optimal cutpoint for a predictor would necessarily be a function of the continuous values of all the other predictors
- You’re losing variation (information) which causes a loss of power and precision
- Assumes that the relationship between the predictor and the response is flat within each interval
- this assumption is far less reasonable than a linearity assumption in most cases
- Percentiles
- Usually estimated from the data at hand, are estimated with sampling error, and do not relate to percentiles of the same variable in a population
- Value of binned variable potentially takes on a different relationship with the outcome
- e.g. Body Mass Index has a smooth relationship with every outcome studied, and relates to outcome according to anatomy and physiology. Binning may change that relationship to being how many subjects have a similar BMI.
- Many bins usually required to make it worth it. Therefore, many dummy variables will end up being created resulting in a loss of power and precision. (i.e. more bins = more variables = more dof used)
- Poor predictive performance with Cox regression models
- If cutpoints are chosen by trial and error in a way that utilizes the response, even informally, ordinary P -values will be too small and confidence intervals will not have the claimed coverage probabilities.
- Bivand suggests that a skewed continuous variable (or maybe just a skewed bounded continuous variable like potentially a proportion) might be binned and transformed into an ordered factor.
“… a house variable, which is the proportion of garbage pick-up points that are residential, rather than business. Only one district — City of London — has a low proportion, and a number of others, mostly tourist destinations, have proportions under 0.9; consequently, the variable might better be represented as an ordered factor.”
fhouse <- cut(eng324$house, c(0.0, 0.25, 0.90, 1)) table(fhouse) ## fhouse ## (0,0.25] (0.25,0.9] (0.9,1] ## 1 23 300Also see Regression, Linear >> Contrasts >>
contr.poly. Bivand actually usescontr.diffin his model
- They might help with prediction using ML or DL models though
- “Instead of directly using marketplace health as a continuous feature, we decided to use a form of target-encoding by splitting up the metric into buckets and taking the average historical delivery duration within that bucket as the new feature. With this approach, we directly helped the model learn that very supply-constrained market conditions are correlated with very high delivery times — rather than relying on the model to learn those patterns from the relatively sparse data available.”
- Improving ETA Prediction Accuracy for Long Tail Events
- Helps to “represent features in a way that makes it easy for the model to learn sparse patterns.”
- This article was about modeling tail events, so maybe this is most useful for features that have an association with the tail values in the outcome variable
- XGBoost seems to like numerics much more than dummies
- Trees may prefer larger cardinalities. So if you do bin, you’d probably want quite a few bins
- Never really seen a binned age variable do well, so guessing more than 10 at least. Though maybe Age just wasn’t important enough.
- Naive Bayes likes binned variables (source)
- “Instead of directly using marketplace health as a continuous feature, we decided to use a form of target-encoding by splitting up the metric into buckets and taking the average historical delivery duration within that bucket as the new feature. With this approach, we directly helped the model learn that very supply-constrained market conditions are correlated with very high delivery times — rather than relying on the model to learn those patterns from the relatively sparse data available.”
- Types
- Notes from Discretization, Explained: A Visual Guide with Code Examples for Beginners
- Equal-Width
Divides the range of a variable into a specified number of intervals, all with the same width
Works well for data with a roughly uniform distribution and when the minimum and maximum values are meaningful.
Example
df['UVIndexBinned'] = pd.cut(df['UVIndex'], bins=4, labels=['Low', 'Moderate', 'High', 'Very High'])
- Equal-Frequency
Creates bins that contain approximately the same number of observations.
Useful for skewed data or when you want to make sure a balanced representation across categories.
Example
df['HumidityBinned'] = pd.qcut(df['Humidity'], q=3, labels=['Low', 'Medium', 'High'])
- Knowledge-based
Based on inherent cut points determined by domain knowledge.
Example
df['RainfallAmountBinned'] = pd.cut(df['RainfallAmount'], bins=[-np.inf, 2, 4, 12, np.inf], labels=['No Rain', 'Drizzle', 'Rain', 'Heavy Rain'])
- Logarithmic
Creates bins that grow exponentially in size. It applies a log transformation first then performs equal-width binning.
Useful for data that spans several orders of magnitude or follows a power law distribution.
Example
df['WindSpeedBinned'] = pd.cut(np.log1p(df['WindSpeed']), bins=3, labels=['Light', 'Moderate', 'Strong'])
- Standard Deviation
Creates bins based on the number of standard deviations away from the mean.
Useful when working with normally distributed data or when you want to bin data based on how far values deviate from the central tendency. Not be suitable for highly skewed distributions
The number of standard deviations used to determine the bin size can be tuned.
Some implementations might use unequal bin widths, with narrower bins near the mean and wider bins in the tails.
Example
mean_temp, std_dev = df['Temperature'].mean(), df['Temperature'].std() bin_edges = [ float('-inf'), # Ensure all values are captured mean_temp - 2.5 * std_dev, mean_temp - 1.5 * std_dev, mean_temp - 0.5 * std_dev, mean_temp + 0.5 * std_dev, mean_temp + 1.5 * std_dev, mean_temp + 2.5 * std_dev, float('inf') # Ensure all values are captured ] df['TemperatureBinned'] = pd.cut(df['Temperature'], bins=bin_edges, labels=['Very Low', 'Low', 'Below Avg', 'Average','Above Avg', 'High', 'Very High'])
- K-means
Uses the K-Means clustering algorithm to create bins
Works well with data that has one peak or several peaks
Example
kmeans = KMeans(n_clusters=3, random_state=42).fit(df[['Crowdedness']]) df['CrowdednessBinned'] = pd.Categorical.from_codes(kmeans.labels_, categories=['Low', 'Medium', 'High'])
- Bin and Embed
- Steps
- Find bin ranges
- If sufficient data, calculate quantiles of the numeric vector to find the bin ranges
sklearn.preprocessing.KBinsDiscretizerhas a few different methods- Use some other method to find the number/ranges of bins (see R packages)
- Use the indices of the bins (i.e. leftmost bin is 1, 2nd leftmost bin is 2) to discretize each value of the numeric
- Might need to be one-hot coded
- Create an embedding of the discretized vector and use the embedding as features.
- Find bin ranges
- Steps
- Examples
Binary
- Whether a user spent more than $50 or didn’t
- If user had activity on the weekend or not
Multinomial or Discrete
- Timestamp to morning/afternoon/ night,
- Order values into buckets of $10–20, $20–30, $30+
- Height, age
- It’s standard practice of grouping the data at ages 95 and older into a single age “95+” in order to avoid the erratic behavior of old age data.
Example:
step_discretizedata(ames, package = "modeldata") recipe(~ Lot_Frontage + Lot_Area, data = ames) |> step_discretize(all_numeric_predictors(), num_breaks = 5) |> prep() |> bake(new_data = NULL) #> # A tibble: 2,930 × 2 #> Lot_Frontage Lot_Area #> <fct> <fct> #> 1 bin5 bin5 #> 2 bin4 bin4 #> 3 bin5 bin5 #> 4 bin5 bin4 #> 5 bin4 bin5 #> 6 bin4 bin3 #> 7 bin2 bin1 #> 8 bin2 bin1 #> 9 bin2 bin1 #> 10 bin2 bin2 #> # ℹ 2,920 more rows
Transformations
Misc
- Also see:
- Packages
- {osktnorm} - A Moment-Targeting Normality Transformation Based on Tukey g-h Distribution
- Designed to minimize both asymmetry (skewness) and excess peakedness (kurtosis) in non-normal data by mapping it to a standard normal distribution
- {osktnorm} - A Moment-Targeting Normality Transformation Based on Tukey g-h Distribution
- Centering
- No matter how a variable is centered (e.g. around the mean, median, or other number), its linear regression coefficient will not change - only the intercept will change.
- Guide for choosing a scaling method for classification modeling
- Notes from The Mystery of Feature Scaling is Finally Solved (narrator: it wasn’t)
- Only used a SVM model for experimentation so who knows if this carries over to other classifiers
- tldr
- Got time and compute resources? –> Ensemble different standardization methods using averaging
- No time and limited compute resources –> standardization
- Models that are distribution independent or distance sensitive (e.g. SVM, kNN, ANNs) should use standardization
- Models that are distribution dependent (e.g. regularized linear regression, regularized logistic regression, or linear discriminant analysis) weren’t tested
- No evidence that data-centric rules (e.g. normal or non-normal distributed variables, outliers present)
- Feature scaling that is aligned with the data or model can be responsible for overfitting
- Ensembling by averaging (instead of using a model to ensemble) different standarization methods
- Experiment used robust scaler (see below) and z-score standardization
- When they added a 3rd method it created more biased results
- Requires predictions to be probabilities
- For ML models, this takes longer because an extra CV has to be run
- Experiment used robust scaler (see below) and z-score standardization
- Notes from The Mystery of Feature Scaling is Finally Solved (narrator: it wasn’t)
Standardization
The standard method transforms feature to have mean = 0, and standard deviation = 1
- Not robust to outliers
- Feature will be skewed
- Doesn’t transform the feature into a bell-shaped density
- Not robust to outliers
Using the median to center and the MAD to scale makes the transformation robust to outliers
Scaling by 2 sd/MAD instead of 1 sd/MAD can be useful to obtain model coefficients of continuous parameters comparable to coefficients related to binary predictors, when applied to the predictors (not the outcome)
Notes from
Reasons to standardize
- Most ML/DL models require it
- Many elements used in the objective function of a learning algorithm (such as the RBF kernel of Support Vector Machines or the l1 and l2 regularizers of linear models) assume that all features are centered around zero and have variance in the same order. If a feature has a variance that is orders of magnitude larger than others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
- Most Clustering methods require it
- PCA can only be interpreted as the singular value decomposition of a data matrix when the columns have centered
- Interpreting the intercept as the mean of the outcome when all predictors are held at their means
- Predictors with large values (country populations) can have really small regression coefficients. Standardization makes the coefficients have a more managable scale.
- Some types of models are more numerically stable with the predictors have been standardized
- Easier to set priors in Bayesian modeling
- Centering fixes collinearity issues when creating powers and interaction terms
- Collinearity between the created terms and the main effects
- Most ML/DL models require it
Other Reasons why you might want to:
- Creating a composite score
- When you’re trying to sum or average variables that are on different scales, perhaps to create a composite score of some kind. Without scaling, it may be the case that one variable has a larger impact on the sum due purely to its scale, which may be undesirable.
- Other Examples:
- Research into children’s behavioral disorders - researchers might get ratings from both parents & teachers, & then want to combine them into a single measure of maladjustment.
- Study on the activity level at a nursing home w/ self-ratings by residents & the number of signatures on sign-up sheets for activities
- To simplify calculations and notation.
- A sample covariance matrix of values that has been centered by their sample means is simply X′X (correlation matrix)
- If a univariate random variable, X, has been mean centered, then var(X)=E(X2) and the variance can be estimated from a sample by looking at the sample mean of the squares of the observed values.
- Creating a composite score
Reasons NOT to standardize
- We don’t want to standardize when the value of 0 is meaningful.
-
Requires {bestNormalize} and has
bestNormalizefor use outside of {tidymodels}Chooses the best standardization method using repeated cross-validation to estimate the Pearson’s P statistic divided by its degrees of freedom (from {nortest}) which indicates closness to the Gaussian distribution.
Package features the method, Ordered Quantile normalization (
orderNorm, or ORQ). ORQ transforms the data based off of a rank mapping to the normal distribution.Also includes: Lambert W\(\times\)F, Box Cox, Yeo-Johnson, arcsinh, exponential, log, square root, and has a method to add your own.
Example
library(bestNormalize) data(ames, package = "modeldata") recipe(Sale_Price ~ Lot_Frontage + Lot_Area, data = ames) |> step_best_normalize(all_numeric_predictors()) |> prep() |> bake(new_data = NULL) #> # A tibble: 2,930 × 3 #> Lot_Frontage Lot_Area Sale_Price #> <dbl> <dbl> <int> #> 1 2.48 2.29 215000 #> 2 0.789 0.689 105000 #> 3 0.883 1.28 172000 #> 4 1.33 0.574 244000 #> 5 0.468 1.19 189900 #> 6 0.656 0.201 195500 #> 7 -0.702 -1.27 213500 #> 8 -0.669 -1.24 191500 #> 9 -0.735 -1.19 236500 #> 10 -0.170 -0.654 189000 #> # ℹ 2,920 more rows
scale(var or matrix)- Default args: center = T, scale = T
- Standardizes each column of a matrix separately
- FYI
scale(var) == scale(scale(var))
{datawizard::standardize} - Can center by median and scale by MAD (robust), can scale by 2sd (Gelman)
-
- Standardize by median and IQR instead of mean and sd
- (value − median) / IQR
- The resulting variable has a zero mean and median and a standard deviation of 1, although not skewed by outliers and the outliers are still present with the same relative relationships to other values.
step_normalizehas means, sd args, so it might be able to do this
- Standardize by median and IQR instead of mean and sd
Harrell recommends substituting the gini mean difference for the standard deviation
Gini’s mean difference - the mean absolute difference between any two distinct elements of a vector.
\[\frac{\sum_{i=1}^n \sum_{j=1}^n |y_i - y_j|}{n(n-1)}\]
Modified Z-Score
\[z_m = 0.6745 \frac{X - \mbox{Median}}{\mbox{MAD}}\]
- The 0.6745 factor makes the scale of the MAD comparable to that of the standard deviation in a normal distribution
Divide by Median then log2 transform (Source)
height_standardized <- log2(height/median(height))- The first step makes individuals of median height equal to 1.
- The second step pushes those individuals equal to 0 (
log2(1) = 0)
Rescaling/Normalization
Misc
- If the values of the feature get rescaled between 0 and 1, i.e. [0,1], then it’s called normalization
- Except in min/max, all values of the scaling variable should be > 0 since you can’t divide by 0
- {datawizard::rescale} - Scales variable to a specified range
Min/Max
Range: [0, 1]
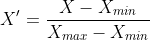
Make sure the min max value are NOT outliers. If they are outliers, then the range of your data will be more constricted that it needs to be.
- e.g. if values are in between 100 and 500 with an exceptional value of 25000, then 25000 is scaled as 1 and all the other values become very close to the lower bound of zero
Example: Age is the predictor and Happiness is the outcome. Imagine a very strong relationship between age and happiness, such that happiness is at its maximum at age 18 and its minimum at age 65. It’ll be easier if we rescale age so that the range from 18 to 65 is one unit. Now this new variable A ranges from 0 to 1, where 0 is age 18 and 1 is age 65. (from Statistical Rethinking section 6.3.1 pg 182)
d2 <- d[ d$age>17 , ] # only adults d2$A <- ( d2$age - 18 ) / ( 65 - 18 )
Range: [a, b]
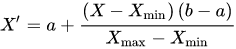
Also see notebook for code to transform more than 1 variable at a time.
By max
scaled_var = var/max(var)- Example: From Statistical Rethinking, pg 246
- “… zero ruggedness is meaningful. So instead terrain ruggedness is divided by the maximum value observed. This means it ends up scaled from totally flat (zero) to the maximum in the sample at 1 (Lesotho, a very rugged and beautiful place).”
- Example: From Statistical Rethinking, pg 258
- “I’ve scaled blooms by its maximum observed value, for three reasons. First, the large values on the raw scale will make optimization difficult. Second, it will be easier to assign a reasonable prior this way. Third, we don’t want to standardize blooms, because zero is a meaningful boundary we want to preserve.”
- blooms is bloom size. So there can’t be a negative but zero makes sense.
- blooms is 2 magnitudes larger than both its predictors.
- “I’ve scaled blooms by its maximum observed value, for three reasons. First, the large values on the raw scale will make optimization difficult. Second, it will be easier to assign a reasonable prior this way. Third, we don’t want to standardize blooms, because zero is a meaningful boundary we want to preserve.”
- Example: From Statistical Rethinking, pg 246
By mean
scaled_var = var/mean(var)- Example: From Statistical Rethinking, pg 246
- “log GDP is divided by the average value. So it is rescaled as a proportion of the international average. 1 means average, 0.8 means 80% of the average, and 1.1 means 10% more than average.”
- Example: From Statistical Rethinking, pg 246
Logging
Useful for skewed variables
If there’s zero-inflation:
log(x + 1)- To backtransform:
exp(logged_predictor) - 1
- To backtransform:
- arcsinh(x): approximates a log (at large values of x) but handles 0s:
- Backtransform:
log(x + sqrt(1+x^2))
- Backtransform:
- * Don’t use these for outcome variables *
- See Regression, Other >> Zero-Inflated/Truncated >> Continuous for details and alternatives
- The scale of the outcome matters. The thread links to a discussion of a paper on log transforms.
- Proposals in the paper are in Section 4.1. One of the recommendations is log(E[Y(0)] + Y) where (I think) E[Y(0)] is the average value of Y when Treatment = 0 but I’m not sure. Need to read the paper.
- See Regression, Other >> Zero-Inflated/Truncated >> Continuous for details and alternatives
Remember to back-transform predictions if you transformed the target variable
# log 10 transformed target variable preds_intervals <- predict( workflows::pull_workflow_fit(lm_wf), workflows::pull_workflow_prepped_recipe(lm_wf) %>% bake(ames_holdout), type = "pred_int", level = 0.90 ) %>% mutate(across(contains(".pred"), ~10^.x))Backtransforming Options
- There’s a backtransformation bias when exponentiating a logged variable which comes from Jenson’s inequality because exponentiation is a convex function:
\(\mathbb{E}[\exp(X)] \ne \exp(\mathbb{E}[X])\) - Median \(\rightarrow\) Use the exponential function:
exp(prediction)- Use when you want the “typical” value of the outcome variable
- You don’t want extreme values/spike/rare events to influence the prediction
- Aggregation over an area or time period
- Exposure Mapping: The median is robust to hotspots, so it gives a cleaner representation of “usual exposure.”
- Smoothing: The median provides a more stable surfaces that reflects underlying gradients rather than spikes
- Use when you want the “typical” value of the outcome variable
- Mean \(\rightarrow\) Use the Gaussian bias correction or Global or Local (Duan) Smearing provide unbiasted estimates of the mean
Instantaneous estimates at a certain time and/or place.
Use Cases
- Regulatory Compliance: Typically based on expected concentration over time, not typical conditions, e.g. annual mean PM10 ≤ threshold
- Risk: You want extreme events to be included in the risk calculation
- e.g. health risk of a substance depends on total dose, not typical level
- e.g. exceedance risk, the probability a value exceeds a threshold amount (alert systems)
Gaussian Bias Correction
- Parametric: Assumes the residuals you get from your logged outcome model are Normal
- The Mean Error should be relatively (log scale) close to zero:
mean(residual)
- The Mean Error should be relatively (log scale) close to zero:
predicted = exp(predicted_log + (pred_var / 2))where pred_var is the prediction variance.- Obtaining pred_var depends on the model
gstat::krigeST(computeVar = TRUE)predict(lm_mod, newdata, se.fit = TRUE)
- Parametric: Assumes the residuals you get from your logged outcome model are Normal
Clobal (Duan) Smearing
\[\begin{align} &\hat Y = \exp(\hat \mu) \cdot \text{SF} \\ &\text{where} \;\; \text{SF} = \frac{1}{n} \sum_{i = 1}^n \exp(e_i) \end{align}\]
Nonparametric
Terms
- \(\hat Y\) is the prediction on the original scale
- \(\hat \mu\) is the prediction on the log scale
- \(\text{SF}\) is the smearing factor
- \(e_i\) is the residual (across all test folds) on the log scale
The calculated smearing factor would be used on predictions of new data as well
Example:
cv_krige_log <- tib_res_cv_krige_fin |> summarize( predicted = mean(predicted, na.rm = TRUE), observed = first(observed), .by = c(station_id, date) # stratifying vars ) |> mutate( residual_log = observed - predicted ) smear_factor_global <- cv_krige_log |> summarize( smear = mean(exp(residual_log), na.rm = TRUE) ) |> pull(smear) cv_krige_bc <- cv_krige_log |> mutate(pred_smear_global = exp(predicted) * smear_factor_global)- Based on Geospatial, Spatio-Temporal >> Kriging >> Examples >> Example 2
Local Smearing
Same as global but you calculate different smearing factors for different groups
Example: Smearing by Season
cv_krige_log <- tib_res_cv_krige_fin |> summarize( predicted = mean(predicted, na.rm = TRUE), pred_var = mean(pred_var, na.rm = TRUE), observed = first(observed), .by = c(station_id, date) ) |> mutate( residual_log = observed - predicted ) cv_krige_log <- cv_krige_log |> mutate( month = lubridate::month(date), season = case_when( month %in% c(12, 1, 2) ~ "DJF", month %in% c(3, 4, 5) ~ "MAM", month %in% c(6, 7, 8) ~ "JJA", month %in% c(9, 10, 11) ~ "SON" ) |> factor(levels = c("DJF", "MAM", "JJA", "SON")) ) seasonal_smear <- cv_krige_log |> summarize( smear_season = mean(exp(residual_log), na.rm = TRUE), .by = season ) cv_krige_bt <- cv_krige_log |> left_join(seasonal_smear, by = "season") |> mutate(pred_smear_global = exp(predicted) * smear_season)- Based on Geospatial, Spatio-Temporal >> Kriging >> Examples >> Example 2
Test how types affect your performance and bias
Example:
Code
tib_sf_pm10_ids <- sf_pm10 |> sf::st_drop_geometry() |> mutate(row_id = row_number()) |> select(row_id, station_id, date) # calculate log residuals from test folds cv_krige_log <- tib_res_cv_krige_fin |> summarize( predicted = mean(predicted, na.rm = TRUE), pred_var = mean(pred_var, na.rm = TRUE), observed = first(observed), .by = c(station_id, date) # stratification vars ) |> mutate( residual_log = observed - predicted, model = "krigeST" ) cv_cat_log <- purrr::map(1:15, \(i) { pred <- cv_cat_pm10$resample_result(3)$predictions()[[i]] tibble( fold = i, row_id = pred$row_ids, observed = pred$truth, predicted = pred$response ) }) |> purrr::list_rbind() |> left_join(tib_sf_pm10_ids, by = "row_id") |> # averages predictions by location and data across all test folds and repeats summarize( predicted = mean(predicted, na.rm = TRUE), observed = first(observed), .by = c(station_id, date) ) |> mutate( residual_log = observed - predicted, model = "Catboost" ) cv_log <- cv_krige_log |> bind_rows(cv_cat_log) |> mutate( month = lubridate::month(date), season = case_when( month %in% c(12, 1, 2) ~ "DJF", month %in% c(3, 4, 5) ~ "MAM", month %in% c(6, 7, 8) ~ "JJA", month %in% c(9, 10, 11) ~ "SON" ) |> factor(levels = c("DJF", "MAM", "JJA", "SON")) )# global smear factor smear_factor_global <- cv_log |> summarize( smear_global = mean(exp(residual_log), na.rm = TRUE), .by = model ) # seasonal smear factor smear_factor_seasonal <- cv_log |> summarize( smear_season = mean(exp(residual_log), na.rm = TRUE), .by = c(season, model) ) # backtransform cv_bt <- cv_log |> left_join(smear_factor_global, by = "model") |> left_join(smear_factor_seasonal, by = c("model", "season")) |> mutate( # observed on original scale observed_orig = exp(observed), # backtransform to median pred_median = exp(predicted), # gaussian lognormal correction pred_gaussian = exp(predicted + (pred_var / 2)), # global smearing pred_smear_global = exp(predicted) * smear_global, # seasonal (local) smearing pred_smear_seasonal = exp(predicted) * smear_season ) |> select(-pred_var) # residual processing for metrics cv_eval <- cv_bt |> select( model, station_id, date, observed_orig, starts_with("pred_") ) |> tidyr::pivot_longer( cols = starts_with("pred_"), names_to = "method", values_to = "prediction" ) |> mutate( residual = observed_orig - prediction, residual_abs = abs(residual), residual_log = log(observed_orig) - log(prediction) ) # evaluate metrics_tbl <- cv_eval |> summarize( # original scale ME = mean(residual, na.rm = TRUE), MAE = mean(residual_abs, na.rm = TRUE), RMSE = sqrt(mean(residual^2, na.rm = TRUE)), # log scale (after backtransformation) ME_log = mean(residual_log, na.rm = TRUE), RMSLE = sqrt(mean(residual_log^2, na.rm = TRUE)), .by = c(method, model) ) |> arrange(RMSE) |> relocate(model, everything()) metrics_tbl #> # A tibble: 8 × 7 #> model method ME MAE RMSE ME_log RMSLE #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 krigeST pred_smear_global -0.449 5.58 8.22 -0.113 0.505 #> 2 krigeST pred_median 1.14 5.41 8.22 -0.0125 0.493 #> 3 krigeST pred_smear_seasonal -0.459 5.58 8.23 -0.112 0.507 #> 4 krigeST pred_gaussian -2.89 6.42 8.92 -0.249 0.552 #> 5 Catboost pred_smear_global -0.358 6.52 9.40 -0.145 0.570 #> 6 Catboost pred_smear_seasonal -0.365 6.52 9.40 -0.144 0.571 #> 7 Catboost pred_median 2.28 6.28 9.63 0.0290 0.552 #> 8 Catboost pred_gaussian NaN NaN NaN NaN NaN- Based on Geospatial, Spatio-Temporal >> Kriging >> Examples >> Example 2
- For kriging
- pred_median should win on MAE since that is median-based and it does.
- Also outperforms pred_smear_seasonal and pred_gaussian on RMSE even though those are mean-based
- pred_smear_global outperforms pred_median on ME (bias) since it’s closer to zero and ties it for RMSE (predictive performance).
- pred_gaussian really sucks. Normal assumption must fail hard.
- pred_median should win on MAE since that is median-based and it does.
- For Catboost
- pred_smear_global has the lowest ME and lowest RMSE
- No performance (RMSE) benefit for using pred_smear_seasonal and it has a worse bias (ME)
- pred_smear_global is the best choice for both models for this use case (daily pollution interpolation)
- The log metrics (ME_log, RMSLE) aren’t particularly useful, as they won’t change your choice of model during CV, but I think it’s interesting to see how the backtransforming methods affect the CV scores.
- Note that logging the backtransformed variable doesn’t produce a bias since log is a concave function.
- There’s a backtransformation bias when exponentiating a logged variable which comes from Jenson’s inequality because exponentiation is a convex function:
Combos
- Log + scale by mean
- Example From Statistical Rethinking Ch8 pg 246
- “Raw magnitudes of GDP aren’t meaningful to humans. Since wealth generates wealth, it tends to be exponentially related to anything that increases it (earlier in chapter). This is like saying that the absolute distances in wealth grow increasingly large, as nations become wealthier. So when we work with logarithms instead, we can work on a more evenly spaced scale of magnitudes”
- “Log GDP is divided by the average value. So it is rescaled as a proportion of the international average. 1 means average, 0.8 means 80% of the average, and 1.1 means 10% more than average.”
- Example From Statistical Rethinking Ch8 pg 246
- Log + scale by mean
Discrete
- Quantitative variables that are countable with no in-between the values. (e.g. integer value variables)
- e.g. Age, Height (depending on your scale), Year of Birth, Counts of things
- Many variables can be either discrete or continuous depending on whether they are “exact” or have been rounded (i.e. their scale).
- Time since event, distance from location
- A zip code would not be a discrete variable since it is not quantitative (i.e. don’t represent amounts of anything). The values just represent geographical locations and could just as easily be names instead of numbers. There is no inherent meaning to arithmetic operations performed on them (e.g. zip_code1 - 5 has no obvious meaning)
- e.g. Age, Height (depending on your scale), Year of Birth, Counts of things
- Binning
- See Binning
- Range to Average
- So numerical range variables like Age can have greater predictive power in ML/DL algorithms by just using the average value of the range
- e.g. Age == 21 to 30 –> (21+30)/2 = 25.5
- Rates/Ratios
- See Domain Specific
- Min/Max Rescaling
Categoricals
Misc
- See Feature Engineering, Embeddings >> Engineering
- One-Hot Encode Issues:
- With high cardinality, the feature space explodes –>
- Less power
- Likely to encounter memory problems
- Using a sparse matrix is memory efficient which might make the one-hot encode feasible
- Sparse data sets don’t work well with highly efficient tree-based algorithms like Random Forest or Gradient Boosting.
- Model can’t determine similarity between categories (embedding does)
- Every kind of encoding and embedding outperforms it by a lot, especially in tree models
- With high cardinality, the feature space explodes –>
Combine/Lump/Collapse
- Collapse categories with similar characteristics to reduce dimensionality
- states to regions (midwest, northwest, etc.)
- Lump
Cat vars with levels with too few counts –> lump together into an “Other” category
step_other(cat_var, threshold = 0.01) # see- For details see Model Building, tidymodels >> Recipe
- Levels with too few data will have large uncertainties about the effect and the bloated std.devs can cause some models to throw errors
- Combine
- The feature reduction can help when data size is a concern
- Think this is equivalent to a cat-cat interaction. ML models usually algorithmically create interactions but I guess this way you get the interaction but with fewer features.
- Also might be useful to use the same considerations that you use to choose interactions to choose which cat variables to combine.
- Steps
- Combine var1 and var2 (e.g. “dog”, “minnesota”) to create a new feature called var3 (“dog_minnesota”).
- Remove individual features (var1 and var2) from the dataset.
- encode (one-hot, dummy, etc.) var 3
- The feature reduction can help when data size is a concern
Encode/Hashing
Cat vars with high numbers of levels need encoded
Can’t dummy var because it creates too many additional variables –> reduces power
“glmm encoding with 5-fold-CV, which ranked first place for all ML algorithms except SVM (where glmm w/o CV performed best). Performance often did not improve with glmm-10CV, suggesting that 5 folds might be a good regularization default in practice.” (source)
- It doesn’t look like a cv process is involved in the {embed} functions though
- GLMM w/10-fold CV came in second and GLMM w/o CV came in third in all algorithms except SVM
- Algos tested: SVM, RF, LASSO, KNN, GBM
Numeric:
as.numeric(as.factor(char_var))Target Encoding
Process
- Group all cases belonging to a unique value of the categorical variable.
- Compute a statistic of the target variable across the group cases.
- Assign the value of the statistic to the group.
-
- tl;dr; I don’t see a method that stands out as theoretically better or worse than the others. From the changelog, LOO was chosen as the default since “it provides more useful results in most cases.”
- Has parallelizable (and maybe distributable) options
target_encoding_labtakes a df and encodes all categoricals using all or some of the methods- Rank (
target_encoding_rank): Returns the rank of the group as a integer, starting with 1 as the rank of the group with the lower mean of the response variable- white_noise argument might be able to used.
- Mean (
target_encoding_mean): Replaces each value of the categorical variable with the mean of the response across the category the given value belongs to.- The argument, white_noise, limits potential overfitting. Must be a value between 0 and 1. The value added depends on the magnitude of the response. If response is within 0 and 1, a white_noise of 0.25 will add to every value of the encoded variable a random number selected from a normal distribution between -0.25 and 0.25
- LOO (
target_encoding_loo): Replaces each categorical value with the mean of the response variable across the other cases within the same group.- The argument, white_noise, limits potential overfitting.
-
pip install category_encoders import category_encoders as ce target_encoder = ce.TargetEncoder(cols=['cat_col_1', 'cat_col_2']) target_encoder.fit(X, y) X_transformed = target_encoder.transform(X_pre_encoded) Hierarchical Blending
Incorporates hierarchical information into target encoding to handle the low frequency problem of target encoding.
- Taking the mean of the target variable when \(X = X_i\) is an issue when the sample of target variable values is small.
Tries to improve target mean estimates for unseen or low frequency categorical levels by using information from more general groups (i.e. variables that represent levels higher in the group hierarchy.
Notes from
- Extending Target Encoding discusses the concepts
- Exploring Hierarchical Blending in Target Encoding experiments with the method and provides a link to the code
Blending is a smoothing method that helps with the overfitting of low frequency categories whereby the estimate of the target given \(X = X_i\) gets blended with the prior probability of the target (or the baseline).(I think this is supposed to be used in standard target encoding as well.)
\[S_i = P(Y|X = X_i) \cdot \lambda(N_i) + P(Y) \cdot (1 - \lambda(N_i))\]
- \(P(Y|X = X_i)\): The proportion of the event given \(X = X_i\)
- \(N_i\): The sample size given \(X = X_i\)
- \(P(Y)\): The overall proportion of the event
- \(\lambda\): A monotonically increasing function
- The larger the sample, the more the estimate is weighted toward the value of the target given \(X = X_i\); the smaller the sample, the more the estimate is weighted toward the overall baseline for the target.
For group of hierarchically related variables, instead of using the overall event rate, \(P(Y)\), the event rate for parent group is used.
Hierarchies can also be engineered. For example, a parent group for zip codes (five numbers) could be the first four numbers or the first three numbers.
Benefits
- Instead of aggregating which can result in loss of information for high frequency categories (i.e. large sample sizes), this method is more of hybrid approach. High frequency categories get the standard target encoding approach, while the low frequency categories get pulled toward a parent group
- With standard blending, skewed distributions where there’s a long tail of low frequency categories end up all being transformed to the overall event rate, but with this method, you end up with a much more distributed representation.
Catboost Encoder
pip install category_encoders import category_encoders as ce catboost_encoder = ce.CatBoostEncoder(cols=['cat_col_1', 'cat_col_2']) catboost_encoder.fit(X, y) X_transformed = catboost_encoder.transform(X_pre_encoded)Binary Encoding
- Benchmarks for decision trees:
- Numeric best (< 1000 categories)
- Binary best (> 1000 categories)
- Store N cardinalities using ceil(log(N+1)/log(2)) features
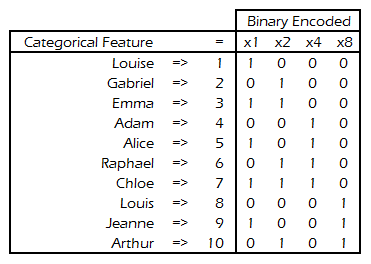
- Benchmarks for decision trees:
Hashing
- I’m not sure about this method. I’ve seen examples where hashes look very different when 1 small thing changes — but maybe it was the algorithm. Also seems like it would be poor security if things that looked similar had similar hashes.
- See Privacy for hashing packages
- Beyond security and fast look-ups, hashing is used for similarity search.
- e.g. Different pictures of the same thing should have similar hashes
- So, if these hashes are being binned, you’d want something a hashing algorithm thinks is similar to actually be similar in order for this to be most effective.
- zip codes, postal codes, lat + long would be good
- Not countries or counties since I’d think the hashing similarity would be related to how similar they are alphabetically or maybe phonetically
- Maybe something like latin species names since those have similar roots, etc. would work. (e.g. dogs are canis-whatever)
- Can’t be reversed to the original values
- Although since you have the original, it seems like you could see which cat levels are in a particular hash and maybe glean some latent variable
- Creates dummies for each cat but fewer of them.
- It is likely that multiple levels of the column will map to the same hashed columns (even with small data sets). Similarly, it is likely that some columns will have all zeros.
- A zero-variance filter (via
recipes::step_zv) is recommended for any recipe that uses hashed columns
- A zero-variance filter (via
- It is likely that multiple levels of the column will map to the same hashed columns (even with small data sets). Similarly, it is likely that some columns will have all zeros.
textrecipes::step_dummy_hash- Dimension Reduction. Create dummy variables, but instead of giving each level its own column, you run the level through a hashing function (MurmurHash3) to determine the column.num_terms: Tuning parameter tha controls the number of indices that the hashing function will map to. Since the hashing function can map two different tokens to the same index, will a higher value of num_terms result in a lower chance of collision.
Example
data(ames, package = "modeldata") recipe(Sale_Price ~ Neighborhood, data = ames) |> step_dummy_hash(Neighborhood, num_terms = 4) |> # Low for example prep() |> bake(new_data = NULL) #> # A tibble: 2,930 × 5 #> Sale_Price dummyhash_Neighborhood_1 dummyhash_Neighborhood_2 #> <int> <int> <int> #> 1 215000 0 -1 #> 2 105000 0 -1 #> 3 172000 0 -1 #> 4 244000 0 -1 #> 5 189900 0 0 #> 6 195500 0 0 #> 7 213500 0 0 #> 8 191500 0 0 #> 9 236500 0 0 #> 10 189000 0 0 #> # ℹ 2,920 more rows #> # ℹ 2 more variables: dummyhash_Neighborhood_3 <int>, #> # dummyhash_Neighborhood_4 <int>
Likelihood Encodings
Estimate the effect of each of the factor levels on the outcome and these estimates are used as the new encoding. The estimates are estimated by a generalized linear model. This step can be executed without pooling (via glm) or with partial pooling (stan_glm or lmer). Currently implemented for numeric and two-class outcomes.
{embed}
step_lencode_glm,step_lencode_bayes, andstep_lencode_mixed
Example: Likelihood (aka Effect) Encoding
museum_rec <- recipe(Accreditation ~ ., data = museum_train) %>% update_role(museum_id, new_role = "id") %>% step_lencode_glm(Subject_Matter, outcome = vars(Accreditation)) %>% step_dummy(all_nominal_predictors())“Subject_Matter” is the high cardinality cat var
step_lencode_glm fits a glm for each(?) level of the cat var uses its estimated effect as the encoded value
mixed linear model (
step_lencode_mixed) and bayesian model (step_lencode_bayes) are also available instead of a glmThese type of encodings use the average estimated effect as a value for any new levels that show-up in future data
tidy(grants_glm, number = 1) %>% dplyr::filter(level == "..new") %>% select(-id)View embedding values
prep(museum_rec) %>% tidy(number = 1)- Not sure if “number = 1” is the step in the recipe or what
Ordinal
Misc
If there are NAs or Unknowns, etc.,
- After coercing into a numeric/integer, you can convert Unknowns to NA and then impute the variable
All these encodings will produce the same results for a tree model, since tree-based models rely on variable ranks rather than exact values.
0 = “0 Children” 1 = “1 Child” 2 = “2 Children” 3 = “3 Children” 4 = “4 or more Children” 1 = “0 Children” 2 = “1 Child” 3 = “2 Children” 4 = “3 Children” 5 = “4 or more Children” -100 = “0 Children” -85 = “1 Child” 0 = “2 Children” 10 = “3 Children” 44 = “4 or more Children”
Via {tidymodels}
step_mutate(ordinal_factor_var = as_integer(ordinal_factor_var)) # think this uses as_numeric step_ordinalscore(ordinal_factor_var)Polynomial Contrasts
- See the section Kuhn’s book
Rainbow Method (article)
- MIsc
- Creates an artifical ordinal variable from a nominal variable (i.e. ordering colors according the rainbow, roy.g.biv)
- At worst, it maintains the signal of a one-hot encode, but with tree models, it results in less splits and therefore a simpler, more efficient, and less overfit model.
- Test psuedo ordinal method by constructing a simple bayesian model with response ~ 0 + ordinal. Then, you extract the posterior for each constructed ordinal level. Pass these posteriors through a constraint that labels draws for that level that are less (or not) than the draws of the previous level. Lastly calculate the proportion of those that were less than in order to get a probability that the predictor is ordered (article >> “The Model” section)
Code
grid <- data.frame( Layer = c("B", "C", "E", "G", "I"), error = 0 ) grid_with_mu <- tidybayes::add_linpred_rvars(grid, simple_mod, value = ".mu") is_stratified <- with(grid_with_mu, { .mu[Layer == "B"] > .mu[Layer == "C"] & .mu[Layer == "C"] > .mu[Layer == "E"] & .mu[Layer == "E"] > .mu[Layer == "G"] & .mu[Layer == "G"] > .mu[Layer == "I"] }) Pr(is_stratified) #> [1] 0.78725“Layer” is the ordinal variable being tested
add_linpred_rvarsextracts the mean response posteriors for each level of the variableResults strongly suggest that the levels of the variable (“Layer”) are ordered, with a 0.79 posterior probability.
- Methods:
- Domain Knowledge
- Variable Attribute (see examples)
- Others - Best to compute these on a hold out set, so as not cause data leakage
- Association with the target variable where the value of association is used to rank the categories
- Proportion of the event for a binary target variable where the value of the proportion is used to rank the categories
- If it’s possible, use domain knowledge according the project’s context to help choose the ranking of the categories.
- There are always multiple ways to rank the categories, so it may be worthwhile to try multiple versions of the artificial ordinal variable
- Not recommended to use more than log₂(K) versions, so as to not surpass the number of variables creating using One-hot (where k is the number of categories)
- Example: Vehicle Type
- Categories
- C: “Compact Car”
- F: “Full-size Car”
- L: “Luxury Car”
- M: “Mid-Size Car”
- P: “Pickup Truck”
- S: “Sports Car”
- U: “SUV”
- V: “Van”
- Potential attributes to order by: vehicle size, capacity, price category, average speed, fuel economy, costs of ownership, motor features, etc.
- Categories
- Example: Occupation
- Categories
- 1: “Professional/Technical”
- 2: “Administration/Managerial”
- 3: “Sales/Service”
- 4: “Clerical/White Collar”
- 5: “Craftsman/Blue Collar”
- 6: “Student”
- 7: “Homemaker”
- 8: “Retired”
- 9: “Farmer”
- A: “Military”
- B: “Religious”
- C: “Self Employed”
- D: “Other”
- Potential attributes to order by: average annual salary, by their prevalence in the geographic area of interest, or variables in a Census dataset or some other data source
- Categories
- MIsc
Weight of Evidence
embed::step_woe
Interactions
- Manually
- Numeric ⨯ Cat
- Dummy the cat, then multiply the numeric times each of the dummies.
- Numeric ⨯ Cat
Domain Specific
- Rates/Ratios
- Purchase per Customer
- Total Spent
- Example:
sum(total_per_invoice, na.rm = TRUE)
- Example:
- Average Spent
- Example:
mean(total_per_invoice, na.rm = TRUE)
- Example:
- Total Spent
- Let the effect of Cost vary by the person’s income
mutate(cost_income = cost_of_product/persons_income)- Intuition being that the more money you have the less effect cost will have on whether purchase something.
- Dividing the feature by income is equivalent to dividing the \(\beta\) by income.
- Purchase per Customer
- Pre-Treatment Baseline
- Example: From Modeling Treatment Effects and Nonlinearities in A/B Tests with GAMS
- outcome = log(profit), treatment = exposure to internation markets, group = store
- Baseline variable is log(profit) before experiment is conducted
- Should center this variable
- Example: From Modeling Treatment Effects and Nonlinearities in A/B Tests with GAMS