Ordinal
- Harrell’s RMS notes/chapters
- Harrell’s data methods post
- Both TDS articles
Misc
- Cumulative Link Models (CLMs)
- {bhsdtr2} (Paper) - Implements a new family of (Bayesian hierarchical) generalized linear models that can be used to model ordinal data.
- Can accommodate binary responses as well as ordered polytomous responses and an arbitrary number of nested or crossed random grouping factors.
- Equal-Variance (EV) and Unequal-Variance (UV) Normal SDT, Dual Process SDT (Yonelinas), EV meta-d’, parsimonious (UV and EV) SDT, and meta-d’ (only EV) models
- {brglm2}
- Estimation and inference from generalized linear models using various methods for bias reduction
- Can be used in models with Separation (See Diagnostics, GLM >> Separation)
- Able to fit proportional-odds models and non-proportional odds models
- Reduction of estimation bias is achieved by solving either:
- The mean-bias reducing adjusted score equations in Firth (1993) and Kosmidis & Firth (2009)
- The median-bias reducing adjusted score equations in Kenne et al (2017)
- The direct subtraction of an estimate of the bias of the maximum likelihood estimator from the maximum likelihood estimates as prescribed in Cordeiro and McCullagh (1991).
- {brms}
- Bayesian CLMs that include structured thresholds in addition to random-effects.
- {clmstan} - Cumulative Link Models with CmdStanR
- Supports logit, probit, cloglog, loglog, cauchit links, and flexible parametric links such as Generalized Extreme Value (GEV), Asymmetric Exponential Power (AEP), and Symmetric Power.
- {hmetad} - Implementation of Bayesian regressions over the meta-d’ model of psychological data from two alternative forced choice tasks with ordinal confidence ratings
- {MASS::polr}
- Standard CLMs for logistic or probit or (complementary) log-log or cauchit (corresponding to a Cauchy latent variable)
- {mvord}:
- An R Package for Fitting Multivariate Ordinal Regression Models
- {ordinal} (Vignette)
- OG; CLMs and CLMMs with location, scale and nominal effects (aka partial proportional odds), structured thresholds and flexible link functions
- Methods for marginal means, tests of functions of the coefficients, goodness-of-fit tests
- *Response variable should be an ordered factor class*
- Compatible with {marginaleffects}, {emmeans}, {ggeffects}
- Package owner doesn’t seem to be developing the package further except for keeping on CRAN. Still has plenty of functionality, but it can take extra effort to get certain metrics and external packages to work with certain models (e.g.
clmm,clmm2for mixed effects) - Check issues on its github for extra functionality since some users have added code there.
- {ordinalNet} (Vignette):
- Fits ordinal regression models with elastic net penalty. Supported model families include cumulative probability, stopping ratio, continuation ratio, and adjacent category
- {ordinalgmifs}
- Ordinal Regression for High-Dimensional Data
- {rms::lrm, orm}
- Standard CLMs for logistic or probit or log-log or complementary log-log or cauchit (corresponding to a Cauchy latent variable).
- {R2D2Ordinal} - Implements the pseudo-R2D2 prior for ordinal regression from the paper “Psuedo-R2D2 prior for high-dimensional ordinal regression”
- {StatRec} (Paper) - A Statistical Method for Multi-Item Rating and Recommendation Problems
- An easy to interpret and flexible statistical method than can model rating data across multiple items, whilst simultaneousely providing uncertainty quantifications surrounding the parameter estimates and predicted values and allowing for inference using small to moderate sample sizes by relying on a set of parametric assumptions.
- Allows for both linear and bilinear terms in the link function
- Assumes a binomial-type likelihood, and by augmenting the data with Pólya-Gamma random variables, it allows for efficient Bayesian inference for the logistic regression model
- {{statsmodels}}
- Probit, Logit, and Complementary Log-Log model
- {VGAM::vglm}
- Proportional odds model (cumulative logit model)
- Proportional hazards model (cumulative cloglog model)
- Continuation ratio model (sequential logit model)
- Stopping ratio model
- Adjacent categories model
- {bhsdtr2} (Paper) - Implements a new family of (Bayesian hierarchical) generalized linear models that can be used to model ordinal data.
- ML
- {partykit::ctree}
- Takes ordered factors as response vars and handles the rest (see vignette)
- {ordinalForest}
- Prediction and Variable Ranking with Ordinal Target Variables
- {partykit::ctree}
- Support
- {marginaleffects} - Supports {ordinal}
- {ordinalTables} - Fit Models to Two-Way Tables with Correlated Ordered Response Categories
- Not sure where to put this but it looks like it contains a lot of stuff for discrete analysis for ordinal variables (References for Agresti and that PSU course)
- Also see
- Notes from
- Analysis of ordinal data with cumulative link models — estimation with the R-package ordinal
- {ordinal} vignette, see below
- Ordinal regression in R: part 1
- Papers
- Modelling phenology using ordered categorical generalized additive models
- Uses {mgcv} for modeling and {sure} diagnostics
- Modelling phenology using ordered categorical generalized additive models
- Resources
- Chapter 23 (Kurz’s brms, tidyverse version), Doing Bayesian Analysis by Kruschke
- Ordinal regression models made easy: A tutorial on parameter interpretation, data simulation and power analysis (Also in R >> Documents >> Regression >> ordinal)
- In order to use a simple linear model on ordinal data, these assumptions must be true. (source)
- Equal spaced intervals between categories: Rarely justified empirically for subjective ratings and, when violated, means that a one-unit change on the predictor does not correspond to a constant change on the outcome scale, potentially distorting estimates of relationships.
- Normal Error Distribution: The normal error distribution is often incompatible with the discrete, bounded nature of ordinal responses, especially when data are skewed or exhibit floor/ceiling effects. This mismatch can lead to issues like heteroscedasticity (unequal error variance), potentially resulting in biased standard errors and impacting the validity of statistical tests.
- Negligible Ceiling and Floor Effects: This fails for data that often clusters at the extremes of the ordinal scale. Linear models struggle to accurately represent these clusters due to the inaccurate assumption of an unbounded latent variable. This can lead to underestimation of the true strength of relationships involving those scale extreme.
- No Latent Threshold Shifts: Different groups might use response categories differently – that is, they might have different internal thresholds for selecting, say, “Agree” versus “Strongly Agree” – even if their mean level on the underlying latent trait is identical. Linear models cannot easily account for such threshold differences and may consequently indicate spurious group differences that are artifacts of response style rather than substantive differences in the construct.
- Common practices among researchers that use linear models for ordinal data that resort in distorted interpretations.
- Composite scales are created by averaging ordinal items and then “normalizing” them (e.g., to a 0–100 range), with results often interpreted as percentage point changes
- They’ll report running both linear and ordinal models but focus interpretation on the linear results, citing “ease of interpretation” or noting only that coefficient signs and statistical significance align across models.
- Power and Sample Size Calculations for a Proportional Odds Model (Harrell)
- Paired data: Use robust cluster sandwich covariance adjustment to allow ordinal regression to work on paired data. (Harrell)
- Sample size: Both ordered logistic and ordered probit, using maximum likelihood estimates, require sufficient sample size. How big is big is a topic of some debate, but they almost always require more cases than OLS regression.
- Harrell summary and comparison of a PO model vs Logistic in the case of an ordinal outcome
.png)
- Formula is an ordinal outcome, Y, with binary treatment variable, Tx, and adjustment variables, X.
- Sometimes researchers tend to collapse an ordinal outcome into a binary outcome. Harrell is showing how using a logistic model is inefficient and lower power than a PO model
- Original is interactive with additional information (link)
- Includes: efficiency, infomation used, assumptions, special cases, estimands, misc
EDA
Misc
- Also see Surveys, Analysis >> Visualization
Crosstabs
Example: Aggregated Counts
ftable(xtabs(~ public + apply + pared, data = dat)) ## pared 0 1 ## public apply ## 0 unlikely 175 14 ## somewhat likely 98 26 ## very likely 20 10 ## 1 unlikely 25 6 ## somewhat likely 12 4 ## very likely 7 3apply is the response variable
Empty cells or small cells: If a cell has very few cases, the model may become unstable or it might not run at all.
Example: Observation Level (article)
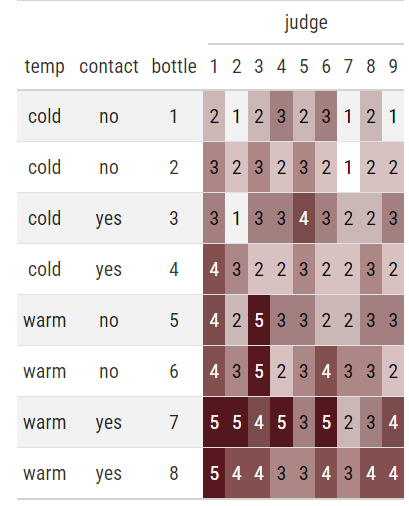
Code
wine %>% dplyr::transmute(temp, contact, bottle, judge, rating = as.numeric(rating)) %>% tidyr::pivot_wider(names_from = judge, values_from = rating) %>% gt::gt() %>% gt::tab_spanner(columns = `1`:`9`, label = "judge") %>% gt::data_color( columns = `1`:`9`, colors = scales::col_numeric( palette = c("white", wine_red), domain = c(1, 5) ) )- Data from Proportional Odds (PO) >> Example 1
- Most judges seem to rate warm bottles highest especially when contact = yes.
Example: Look for variation in a potential random effect
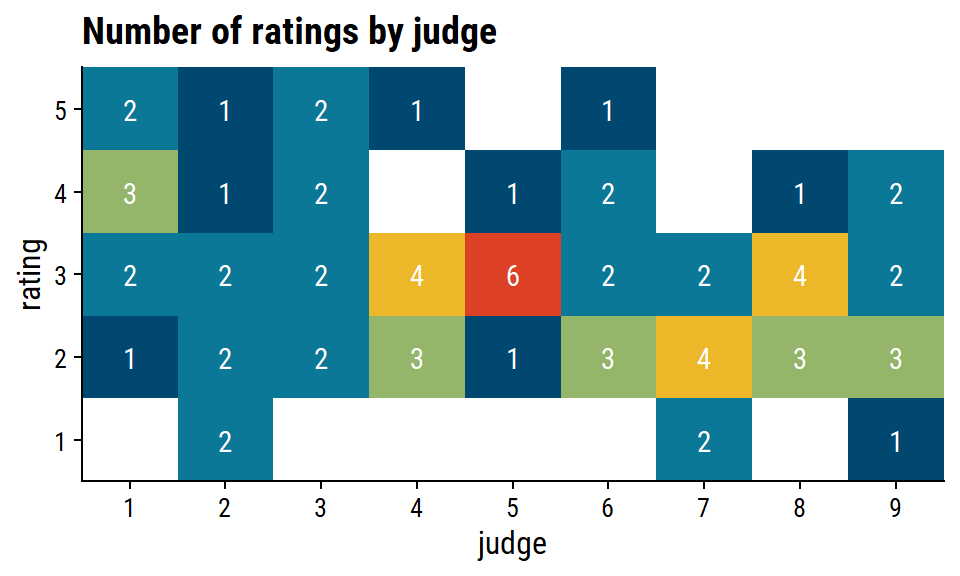
Code
wine %>% count(judge, rating) %>% ggplot(aes(x = judge, y = rating)) + geom_tile(aes(fill = n)) + geom_text(aes(label = n), color = "white") + scale_x_discrete(expand = c(0, 0)) + scale_y_discrete(expand = c(0, 0)) + theme(legend.position = "none") + labs(title = "Number of ratings by judge")- There’s some judge-specific variability in the perception of bitterness of wine. judge 5, for instance, doesn’t stray far from rating = 3, while judge 7 didn’t consider any of the wines particularly bitter.
Grouped Bar
Example
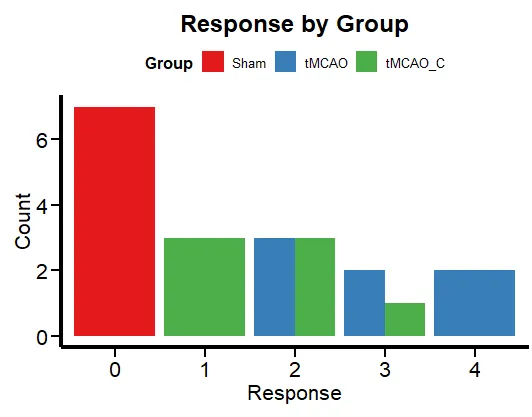
Code
ggplot(df, aes(x = factor(Response), fill = Group)) + geom_bar(position = "dodge") + labs(x = "Response", y = "Count", title = "Response by Group") + theme_minimal() + scale_fill_brewer(palette = "Set1") + plot_theme() + theme(legend.position = "top", legend.direction = "horizontal")- This is just to get an idea of the frequencies for each group level.
Histograms
The shape can help you choose a link function (See Cumalative Link Models (CLM) >> Link Functions)
If distributions of a pre-treatment/baseline (outcome) variable looks substantially different than the (post-treatment) outcome variable, then the treatment likely had an effect
Example: Simple Percentages
\(\mbox{lvl}_1 = \mbox{lvl}_{1/N} = 0.2219\), \(\mbox{lvl}_2 = 0.2488\), \(\mbox{lvl}_3 = 0.25\), and \(\mbox{lvl}_4 = 0.2794\)- Monotonicly increasing, so skewing left
Example: Histogram, Cumulative Proportion, Log Cumulative Proportion (article)
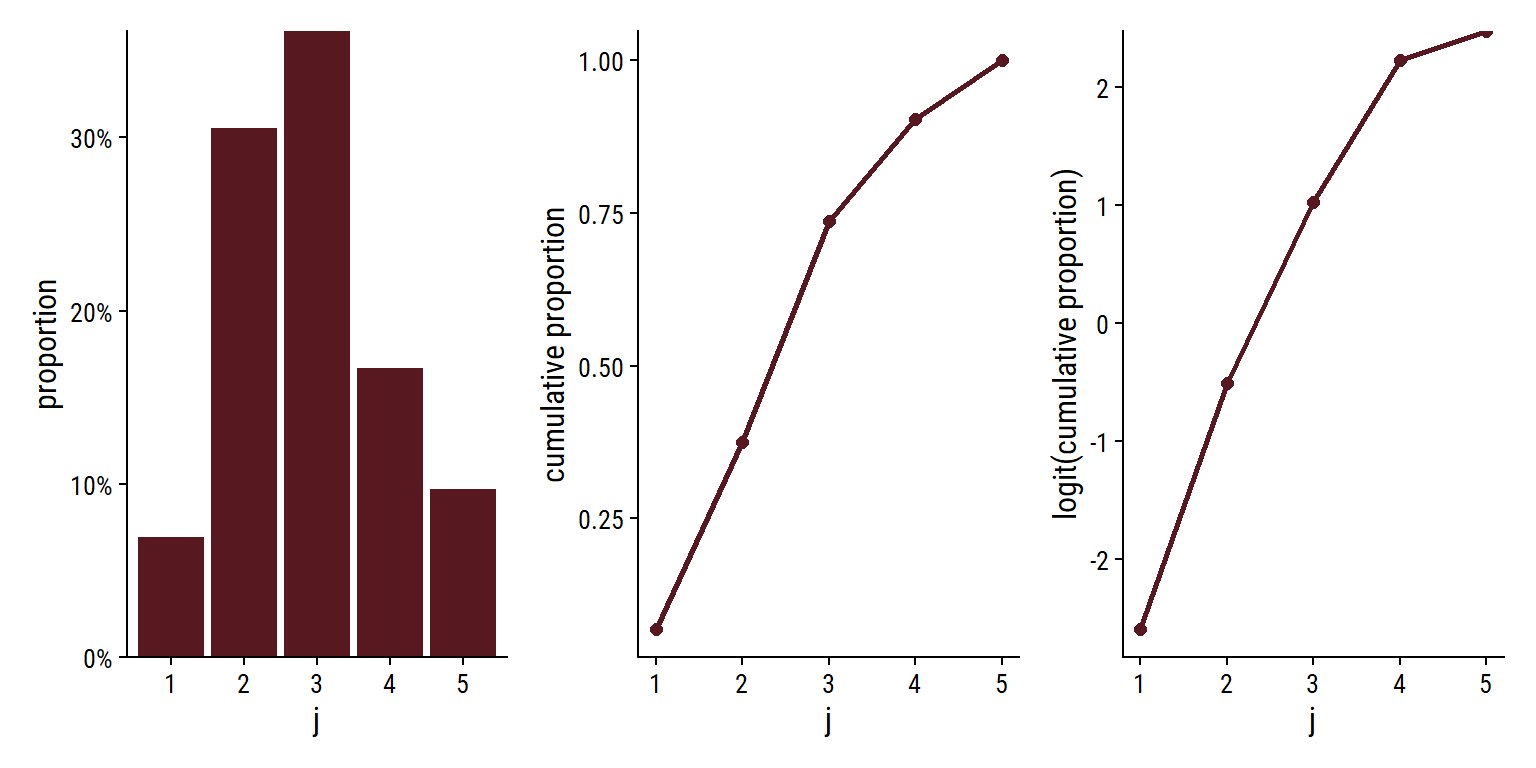
Code
wine_prop <- wine %>% count(rating) %>% mutate(p = n / sum(n), cumsum_p = cumsum(p)) ( ggplot(wine_prop, aes(x = rating, y = p)) + geom_col(fill = wine_red) + scale_y_continuous(labels = scales::percent, expand = c(0, 0)) + labs(x = "j", y = "proportion") ) + ( ggplot(wine_prop, aes(x = as.integer(rating), y = cumsum_p)) + geom_point(size = 2) + geom_line(size = 1) + labs(x = "j", y = "cumulative proportion") ) + ( ggplot(wine_prop, aes(x = as.integer(rating), y = log(cumsum_p) - log(1 - cumsum_p))) + geom_point(size = 2) + geom_line(size = 1) + labs(x = "j", y = "logit(cumulative proportion)") )- Data from Proportional Odds (PO) >> Example 1
- Proportions are used since the response is from a multinomial distribution
- See Cumulative Link Models (CLM) >> Response variable follows the Multinomial distribution
- Distribution looks a little right-skewed.
Bi-variate boxplots
Look for trends of the median
Example: Numeric vs Ordinal
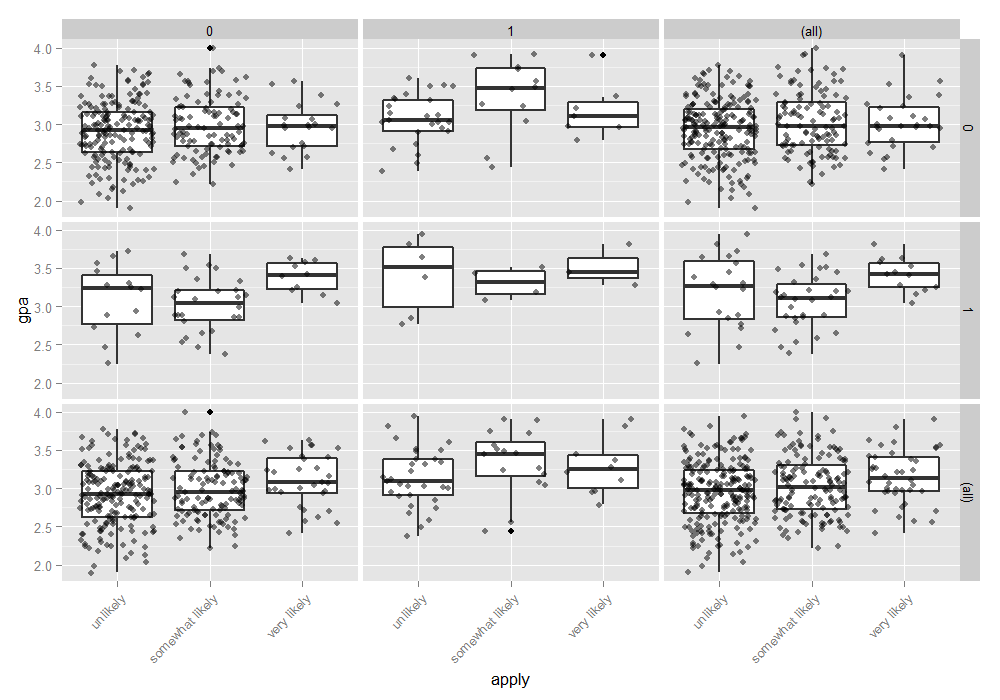
Code
ggplot(dat, aes(x = apply, y = gpa)) + geom_boxplot(size = .75) + geom_jitter(alpha = .5) + facet_grid(pared ~ public, margins = TRUE) + theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1))- In the lower right hand corner, is the overall relationship between apply and gpa which appears slightly positive.
Pre-intervention means of the outcome by explanatory variables
Example
CC = 0, TV = 0 2.152 CC = 0, TV = 1 2.087 CC = 1, TV = 0 2.050 CC = 1, TV = 1 1.979- CC and TV are binary explanatory variables
- The mean score of the pre-treatment outcome doesn’t change much given these two explanatory variables.
- I think this shows that for the most part that assignment of the two different treatments was balanced in terms of the scores of the baseline variable.
Dot Plots
Example: 4 explanatory factor variables (article)
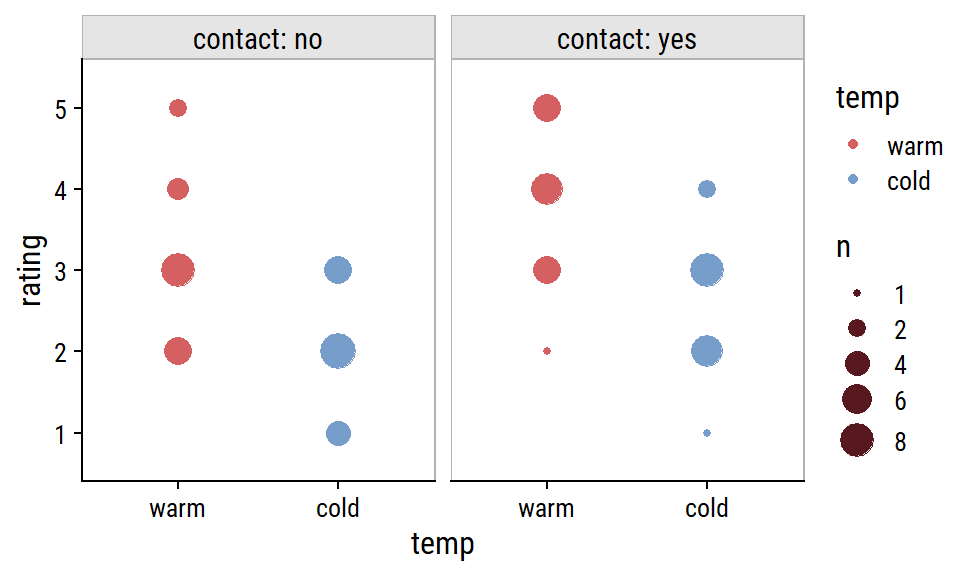
Code
wine %>% count(contact, rating, temp) %>% mutate(temp = fct_rev(temp)) %>% ggplot(aes(x = temp, y = rating, color = temp)) + geom_point(aes(group = temp, size = n)) + facet_wrap(~contact, scales = "free_x", labeller = labeller(contact = label_both)) + scale_size(breaks = c(1, 2, 4, 6, 8)) + add_facet_borders()- Data from Proportional Odds (PO) >> Example 1
- Most judges seem to rate warm bottles highest especially when contact = yes.
- Compared to the crosstab, I think this more clearly shows that there is an effect present between temp and rating especially when moderated by contact.
Diagnostics
Packages
- {apor} - Produces several metrics to assess the prediction of ordinal categories based on the estimated probability distribution for each unit of analysis produced by any model returning a matrix with these probabilitie
- {generalhoslem} - Lipsitz and Pulkstenis-Robinson tests
- {sure} - Constructs SUrrogate-based REsiduals and diagnostics for ordinal and general regression models (See Phenology paper in Misc >> Papers for use in the wild)
- They use a surrogate continuous variable in place of the discrete response, based on the conditional distribution of Z given the observed Z. Surrogate residuals are randomized, so the random seed must be set for reproducibility.
- Currently supports cumulative link models from packages ‘MASS’, ‘ordinal’, ‘rms’, and ‘VGAM’. Support for binary regression models using the standard ‘glm’ function is also available
cond.H - Located in top row of GOF metrics. The condition number of the Hessian is a measure of how identifiable the model is.
- Values larger than 1e4 indicate that the model may be ill defined
Deviance: \(-2 \cdot (\mbox{LogLik Reduced Model} - \mbox{LogLik Saturated model})\)
- Likelihood ratio statistic for the comparison of the full and reduced models
- Reduced model is the model you just fit.
- Can usually be extracted from the model object (e.g. {ordinal}:
ll_reduced <- mod$logLik)
- Can usually be extracted from the model object (e.g. {ordinal}:
- Saturated Model also called the Full Model
Also see Regression, Discrete >> Terms
The Full Model has a parameter for each observation and describes the data perfectly while the reduced model provides a more concise description of the data with fewer parameters.
Usually calculated from the data themselves
data(wine, package = "ordinal") tab <- with(wine, table(temp:contact, rating)) ## Get full log-likelihood (aka saturated model log-likelihood) pi.hat <- tab / rowSums(tab) (ll.full <- sum(tab * ifelse(pi.hat > 0, log(pi.hat), 0))) ## -84.01558
GOF (rule of thumb): If the deviance about the same size as the difference in the number of parameters (i.e. \(p_{\mbox{full}} - p_{\mbox{reduced}}\)), there is NOT evidence of lack of fit. (ordinal vignette, pg 14)
- Example (Have doubts this is correct)
- Looking at the number of parameters (no.par) for fm1 in Example 1 (below) and the model summary in Proportional Odds (PO) >> Example 1, the number of parameters for the reduced model is the \(\mbox{number of regression parameters} (2) + \mbox{number of thresholds} (4)\)
- For the full model (aka saturated), the number of thresholds should be the same, and there should be one more regression parameter, an interaction between temp and contact. So, 7 should be the number of parameters for the full model
- Therefore, for a good-fitting model, the deviance should be close to \(p_{\text{full}} - p_{\text{reduced}} = 7 - 6 = 1\)
- This example uses “number of parameters” which is the phrase in the vignette, but I think it’s possible he might mean degrees of freedom (dof) which he immediatedly discusses afterwards. In the LR Test example below, under LR.Stat, which is essentially what deviance is, the number is around 11 which is quite aways from 1. Not exactly an apples to apples comparison, but the size after adding 1 parameter just makes me wonder if dof would match this scale of numbers for deviances better.
- Example (Have doubts this is correct)
Model Selection: A difference in deviance between two nested models is identical to the likelihood ratio statistic for the comparison of these models
- See Example 1 (below)
Requirement: Deviance tests are fine if the expected frequencies under the reduced model are not too small and as a general rule they should all be at least five.
- Also see Discrete Analysis notebook
Residual Deviance: \(D_{\text{resid}} = D_{\text{total}} - D_{\text{reduced}}\)
- A concept similar to a residual sums of squares (RSS)
- Total Deviance (\(D_{\text{total}}\)) is the Null Deviance: \(-2*(\mbox{LogLik Null Model} - \mbox{LogLik Saturated model})\)
- Analogous to the total sums of squares for linear models
- \(D_{\text{reduced}}\) is the calculation of Deviance shown above
- See example 7, pg 13 ({ordinal} vignette) for (manual) code
Example 1: Model selection with LR tests
fm2 <- ordinal::clm(rating ~ temp, data = wine) anova(fm2, fm1) #> Likelihood ratio tests of cumulative link models: #> formula: link: threshold: #> fm2 rating ~ temp logit flexible #> fm1 rating ~ temp + contact logit flexible #> no.par AIC logLik LR.stat df Pr(>Chisq) #> fm2 5 194.03 -92.013 #> fm1 6 184.98 -86.492 11.043 1 0.0008902 ***- For fm1 model, see Proportional Odds (PO) >> Example 1
- Special method for clm objects from the package; produces an Analysis of Deviance (ANODE) table
- Adding contact produces a better model (pval < 0.05)
Example 2: LR tests for variables
drop1(fm1, test = "Chi") #> rating ~ contact + temp #> Df AIC LRT Pr(>Chi) #> <none> 184.98 #> contact 1 194.03 11.043 0.0008902 *** #> temp 1 209.91 26.928 2.112e-07 *** # fit null model fm0 <- ordinal::clm(rating ~ 1, data = wine) add1(fm0, scope = ~ temp + contact, test = "Chi") #> Df AIC LRT Pr(>Chi) #> <none> 215.44 #> temp 1 194.03 23.4113 1.308e-06 *** #> contact 1 209.91 7.5263 0.00608 **- For fm1 model, see Proportional Odds (PO) >> Example 1
drop1- Tests the same thing as the Wald tests in the summary except with \(\chi^2\) instead of t-tests
- i.e. Whether the estimates, while controlling for the other variables, differ from 0, except with LR tests.
- In this case, LR tests slightly more significant than the Wald tests
- Tests the same thing as the Wald tests in the summary except with \(\chi^2\) instead of t-tests
add1- Tests variables where they’re the only explanatory variable in the model (i.e. ingores other variables)
- Both variables still significant even without controlling for the other variable
Cumulative Link Models (CLM)
A general class of ordinal regression models that include many of the models in this note.
Types
Proportional Odds Model: CLM with a logit link
Proportional Hazards Model: CLM with a log-log link, for grouped survival times
\[-\log(1-\gamma_j(\boldsymbol{x}_i)) = e^{\theta_j - \boldsymbol{x}_i^T \boldsymbol{\beta}}\]
- Link Function: \(\log(− \log(1 − \gamma))\)
- Inverse Link: \(1 − e^{− e^\eta}\)
- Distribution: \(\mbox{Gumbel} (\min)^b\) (?)
- \(1 − \gamma_j(x_i)\) is the probability or survival beyond category \(j\) given \(x_i\).
Partial Proportional Odds: Also referred to as Unequal Slopes, Partial Effects, and Nominal Effects
Cumulative Link Mixed Models (CLMM): CLMs with normally distributed random effects
Link Functions
.png)
- Note the shape of the distributions of the response (see EDA) to help choose a link function
- See Proportional Odds (PO) >> Example 2
- e.g. A logit link assumes the latent variable probability (and error distribution) is a logistic distribution (fatter tails than a Normal distribution) while a probit link assumes a Normal latent variable probability distribution.
- Kurtotic, see Mathematics, Statistics >> Descriptive Statistics >> Kurtosis (i.e. Higher sharper peaks w/short tails, flatter peaks w/long tails)
- Default parameter values fit a symmetric heavy tailed distribution (high, sharp peak)
- Note the shape of the distributions of the response (see EDA) to help choose a link function
Model
.png)
- \(j\) is the jth ordinal category where \(j_1 \lt j_2 \lt \ldots\)
- \(i\) is the ith observation
- The regression part \(x^T_i \beta\) is independent of \(j\), so \(\beta\) has the same effect for each of the \(J − 1\) cumulative logits
- The \(\{\theta_j\}\) parameters provide each cumulative logit (for each \(j,\) see below) with its own intercept
- \(\theta\) is called a “threshold.” See below, Latent Variable Concept
- \(z_i\): A vector of covariates affecting the scale
- \(\zeta\): A vector of scale parameters to be estimated
Response variable follows the Multinomial distribution
\[\begin{aligned} &\gamma_{i,j} = P(Y_i \le j) = \pi_{i,1} + \cdots + \pi_{i,j}\\ &\text{with} \quad \sum_{j=1}^J \pi_{i,j} = 1 \end{aligned}\]
- The output is the probability that the response is the jth category or lower.
- \(\pi_{i,j}\) denotes the probability that the ith observation falls in response category \(j\)
- This distribution can be visualized by looking at the cumulative proportions in the observed data (See EDA >> Histograms)
Cumulative Logits (Logit Link)
.png)
- \(j = 1 , \ldots , J - 1\) , so cumulative logits are defined for all but the last category
- If \(x\) represent a treatment variable with two levels (e.g., placebo and treatment), then \(x_2 − x_1 = 0 - 1 = -1\) and the odds ratio is \(e^{−\beta_{\text{treatment}}}\).
- Similarly the odds ratio of the event \(Y \ge j\) is \(e^{\beta_\text{treatment}}\) (i.e. inverse of \(Y \le j\)).
Latent Variable Concept
- Notes from Models for Proportional and Nonproportional Odds
- Also see the Proportional Odds (PO) >> Probit Link section
- “To motivate the ordinal regression model, it is often assumed that there is an unobservable latent variable ( \(y^*\) ) which is related to the actual response through the”threshold concept.” An example of this is when respondents are asked to rate their agreement with a given statement using the categories “Disagree,” “Neutral,” “Agree.” These three options leave no room for any other response, though one can argue that these are three possibilities along a continuous scale of agreement that would also make provision for “Strongly Agree” and “Disagree somewhat.” The ordinal responses captured in \(y\) and the latent continuous variable \(y^*\) are linked through some fixed, but unknown, thresholds.”
- A response occurs in category \(j\) (\(Y = j\)) if the latent response process \(y^*\) exceeds the threshold value, \(\theta_{j-1}\) , but does not exceed the threshold value, \(\theta_j\) .
- I think \(y^*\) is continous on the scale of logits. \(\theta_j\)s are also intercepts in the model equations and also on the scale of logits (see Proportional Odds (PO) >> Example 3)
- The cumulative probabilities are given in terms of the cumulative logits with \(J−1\) strictly increasing model thresholds \(\theta_1, \theta_2, \ldots , \theta_{J-1}\).
- With \(J = 4\), we would have \(J −1 = 3\) cumulative probabilities, given in terms of 3 thresholds \(\theta_1\), \(\theta_2\), and \(\theta_3\) . The thresholds represent the marginal response probabilities in the \(J\) categories.
- Each cumulative logit is a model equation with a threshold for an intercept
- To set the location of the latent variable, it is common to set a threshold to zero. Usually, the first of the threshold parameters ( \(\theta_1\)) is set to zero.
- Alternatively, the model intercept (\(\beta_0\)) is set to zero and \(J −1\) thresholds are estimated. (Think this is the way {ordinal} does it.)
Structured Thresholds
- If ratings are the response variable, placing restrictions on thresholds and fitting a model allows us to test assumptions on how the judges are using the response scale
- An advantage of applying additional restrictions on the thresholds is that the model has fewer parameters to estimate which increases model sensitivity.
- Threshold distances are affected by the shape of the latent variable distribution which is determined by the link function used
- i.e. If it’s determined that threshold distances are equidistant under a normal distribution (logit link) assumption, then they will not be equidistant if a different link function is used.
- Example: Is the reponse scale being treated by judges as equidistant between values.
e.g. Is the distance between a rating of 2 and a rating of 1 the same as the distance between a rating of 2 and a rating of 3?
Mathematically: \(\theta_j − \theta_{j−1}\) = constant for \(j = 2, ..., J−1\) where \(\theta\) are the thresholds and \(J\) is the number of levels in the response variable.
Fit equidistant, PO model
fm.equi <- clm(rating ~ temp + contact, data = wine, threshold = "equidistant") summary(fm.equi) #> link threshold nobs logLik AIC niter max.grad cond.H #> logit equidistant 72 -87.86 183.73 5(0) 4.80e-07 3.2e+01 #> #> Estimate Std.Error z.value Pr(>|z|) #> tempwarm 2.4632 0.5164 4.77 1.84e-06 *** #> contactyes 1.5080 0.4712 3.20 0.00137 ** #> #> Threshold coefficients: #> Estimate Std.Error z.value #> threshold.1 -1.0010 0.3978 -2.517 #> spacing 2.1229 0.2455 8.646- spacing: Average distance between consecutive thresholds
Compare spacing parameter with your model’s average spacing
mean(diff(coef(fm1)[1:4])) #> 2.116929fm1 is from Proportional Odds (PO) >> Example 1
Result: fm1 spacing is very close to fm.equi spacing. Judges are likely applying the response scale as having equal distance between rating values.
Does applying threshold restrictions decrease the model’s GOF
anova(fm1, fm.equi) #> no.par AIC logLik LR.stat df Pr(>Chisq) #> fm.equi 4 183.73 -87.865 #> fm1 6 184.98 -86.492 2.7454 2 0.2534- No statistical difference in log-likelihoods. Fewer parameters to estimate is better, so keep the equidistant thresholds
Proportional Odds (PO)
Misc
- The treatment effect for proportional odds model will be the average of the treatment effects of \(J-1\) logistic regression models where each model is dichotmized at each, but not the last, ordinal level.
- The intercepts in the proportional odds model will be similar to those intercepts from the \(J-1\) logistic regression models
- The intercepts of these logistic models have to be different, but the slopes could (in principle) be the same or same-ish. If they are the same, then the proportional odds assumption holds.
- The proportional odds model has a smaller std.error for its treatment effect than any of the treatment effects of the \(J-1\) logistic regression models (i.e. more accurately estimated in p.o. model)
- The intercepts in the proportional odds model will be similar to those intercepts from the \(J-1\) logistic regression models
- Benefits
- It enforces stochastic ordering (?)
- Lots of choices for link functions.
- Reasonable model for analysing ordinal data
- \(\beta\) will be some sort of appropriately-weighted average of what you’d get for the separate logistic regressions
Assumption
- The independent variable effect is the same for all levels of the ordinal outcome variable
- \(\beta\)s (i.e. treatment effect) are not allowed to vary with \(j\) (i.e. response variable levels) or equivalently that the threshold parameters \({\theta_j}\) are not allowed to depend on regression variables
- Example:
- Outcome = health_status (1 for poor, 2 for average, 3 for good and 4 for excellent)
- Independent Variable = family_income (1 for above avg, 0 for below average)
- If the proportional odds assumption holds then:
- The log odds of being at average health from poor health is \(\beta_1\) if family income increases to above average status.
- The log odds of being at good heath from average health is \(\beta_1\) if family income increases to above average status.
- The log odds of being at excellent heath from good health is \(\beta_1\) if family income increases to above average status.
- Testing the assumption
- Also see Partial Proportional Odds >> Examples 2, 3
- Even if the model fails the PO assumption, it can still be useful
- See
- See Misc >> Harrell summary and comparison of a PO model vs Logistic (the far right branch)
- {CORPlot} Intro below
- For testing the treatment effect, the PO assumption does not matter.
- If the null hypothesis of no treatment effect holds, then the PO assumption automatically holds also. Pre-testing the PO assumption is useless, and can even invalidate the subsequent tests.
- For estimating & reporting treatment effects, the PO assumption does matter.
- If the effect is heterogeneous then no single-number summary (such as the common odds ratio) can faithfully represent it. We propose the cumulative odds ratio plots to show the effect of the treatment at every level of the ordinal scale, and what it means to make the PO assumption.
- See
- If the model badly fails the PO assumption, move to PPO, generalized ordered probit, or multinomial logit.
- Issues with testing
- Small Sample Sizes: For some variables, you might not have enough power to detect important violations of the PO assumption.
- Large Sample Sizes: For some variables, you will detect small, unimportant violations of the PO assumption and reject a good model.
- Omnidirectional goodness-of-fit tests don’t tell you which variables you should look at for improvements.
- You can test this assumption by fitting a PO model and PPO model.
- Then, comparing both models via LR Test or using {ordinal::nominal_test} (See below, Partial Proportional Odds (PPO) >> Example 2 and Example 3)
- Statistical Tests
gofcat::brant.test(mod)- Provides the means of testing the parallel regression assumption in the ordinal regression models.- Currently supports
serp,clm,polr, andvglm - p > 0.05 says the assumption holds
- Currently supports
rms::plot.xmean.ordinal(y ~ x, data = d)- Plots predicted values and expected predicted values (assumes assumption holds)
- If both line track closely together, then the assumption holds
- Better than the Brant Test because if the two lines drift apart, it can show how badly the assumption fails.
- Test the impact of violating the PO assumption: {rms::impactPO}
- Graphically assess the PO assumption by comparing the ORs of a PO model and a cumulative logistic regression (i.e., no proportionality constraint)
- Assess graphically (article, Harrell RMS pg 316)
Calculate estimated effects for each explanatory variable in a univariate logistic regression model (e.g.
glm(apply ~ pared, family = binomial))sf <- function(y) { c('Y>=1' = qlogis(mean(y >= 1)), 'Y>=2' = qlogis(mean(y >= 2)), 'Y>=3' = qlogis(mean(y >= 3))) } (s <- with(dat, summary(as.numeric(apply) ~ pared + public + gpa, fun=sf))) #> +-------+-----------+---+----+--------+------+ #> | | |N |Y>=1|Y>=2 |Y>=3 | #> +-------+-----------+---+----+--------+------+ #> |pared |No |337|Inf |-0.37834|-2.441| #> | |Yes | 63|Inf | 0.76547|-1.347| #> +-------+-----------+---+----+--------+------+ #> |public |No |343|Inf |-0.20479|-2.345| #> | |Yes | 57|Inf |-0.17589|-1.548| #> +-------+-----------+---+----+--------+------+ #> |gpa |[1.90,2.73)|102|Inf |-0.39730|-2.773| #> | |[2.73,3.00)| 99|Inf |-0.26415|-2.303| #> | |[3.00,3.28)|100|Inf |-0.20067|-2.091| #> | |[3.28,4.00]| 99|Inf | 0.06062|-1.804| #> +-------+-----------+---+----+--------+------+ #> |Overall| |400|Inf |-0.20067|-2.197| #> +-------+-----------+---+----+--------+------+For \(Y \ge 2\) and pared = no, -0.37834 is the same as the intercept of the univariate model
For \(Y \ge 2\) and pared = yes, 0.76547 is the same as the intercept + coefficient of the univariate model
For each variable, calculate differences in estimates between levels of the ordinal response
s[, 4] <- s[, 4] - s[, 3] s[, 3] <- s[, 3] - s[, 3] s ## +-------+-----------+---+----+----+------+ ## | | |N |Y>=1|Y>=2|Y>=3 | ## +-------+-----------+---+----+----+------+ ## |pared |No |337|Inf |0 |-2.062| ## | |Yes | 63|Inf |0 |-2.113| ## +-------+-----------+---+----+----+------+ ## |public |No |343|Inf |0 |-2.140| ## | |Yes | 57|Inf |0 |-1.372| ## +-------+-----------+---+----+----+------+ ## |gpa |[1.90,2.73)|102|Inf |0 |-2.375| ## | |[2.73,3.00)| 99|Inf |0 |-2.038| ## | |[3.00,3.28)|100|Inf |0 |-1.890| ## | |[3.28,4.00]| 99|Inf |0 |-1.864| ## +-------+-----------+---+----+----+------+ ## |Overall| |400|Inf |0 |-1.997| ## +-------+-----------+---+----+----+------+For pared, the difference in estimates between \(Y \ge 2\) and \(Y \ge 3\) is -2.062 and -2.113. Therefore, it would seem that the PO assumption holds up pretty well for pared.
For public, the difference in estimates between \(Y \ge 2\) and \(Y \ge 3\) is -2.140 and -1.372. Therefore, it would seem that the PO assumption does NOT hold up for public.
If there was a \(Y \ge 4\), then for pared, the difference in estimates between \(Y \ge 3\) and \(Y \ge 4\) should be near 2 as well in order for the PO assumption to hold for that variable.
Plot
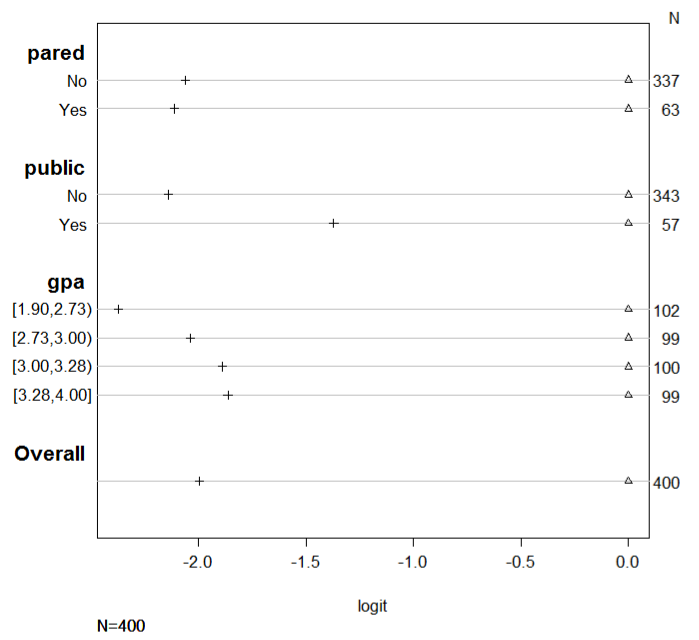
plot(s, which=1:3, pch=1:3, xlab='logit', main=' ', xlim=range(s[,3:4]))- In addition to the PO assumption not seemingly holding for public, there also seems to be some substantial differences between the quantiles of gpa.
- The 3rd and 4th seem to be in agreement, but not the 1st and maybe not the 2nd.
- In addition to the PO assumption not seemingly holding for public, there also seems to be some substantial differences between the quantiles of gpa.
- Assess PO assumption via ECDF
Procedure
- Compute the empirical cumulative distribution function (ECDF) for the response variable, stratified by group
- Take the logit transformation of each ECDF
- Check for parallelism
- Linearity would be required only if using a parametric logistic distribution instead of using our semiparametric PO model
Example: Harrell BFBR Ch. 7.7
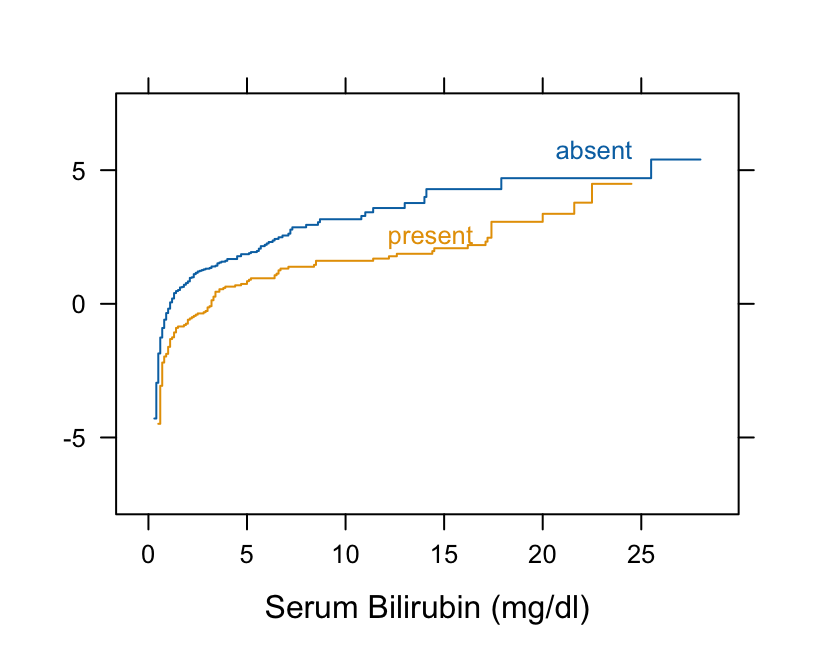
Code
Hmisc::getHdata(pbc) pbc[, c("bili", "spiders")] |> dplyr::glimpse() #> Rows: 418 #> Columns: 2 #> $ bili <labelled> 14.5, 1.1, 1.4, 1.8, 3.4, 0.8, 1.0, 0.3, 3.2, 12.6, 1.4, 3.6, 0.7, 0.8, 0.8, 0.7, 2.7, 11.4, 0.7, 5.1, 0.6, 3.4, 17.4… #> $ spiders <fct> present, present, absent, present, present, absent, absent, absent, present, present, present, present, absent, absent, ab… # Take logit of ECDF Hmisc::Ecdf(~ bili, group = spiders, data = pbc, fun = qlogis)- The curves are primarily parallel (even at the far left, despite the optical illusion)
- Nonlinearity that is present is irrelevant
Examples
Example 1: Ordinal ~ Categorical + Categorical
- Data and Model
Notes from
- Video: Ordinal Regression Demystified = Proportional Odds = Ordered Logit = Cumulative Link (Part 1) by yuzaR
- Video: Ordinal Regression Part 2: Cumulative and Exceedance Probabilities by yuzaR
data(wine, package = "ordinal") glimpse(as_tibble(wine)) #> Rows: 72 #> Columns: 6 #> $ response <dbl> 36, 48, 47, 67, 77, 60, 83, 90, 17, 22, 14, 50, 30, 51, 90, 7… #> $ rating <ord> 2, 3, 3, 4, 4, 4, 5, 5, 1, 2, 1, 3, 2, 3, 5, 4, 2, 3, 3, 2, 5… #> $ temp <fct> cold, cold, cold, cold, warm, warm, warm, warm, cold, cold, c… #> $ contact <fct> no, no, yes, yes, no, no, yes, yes, no, no, yes, yes, no, no,… #> $ bottle <fct> 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5… #> $ judge <fct> 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3…- Temperature and contact between juice and skins can be controlled when crushing grapes during wine production
- Other variables
- response: alternative outcome; wine bitterness rating on a 0-100 scale
- Random Effects
- bottle with 8 levels
- judge with 9 levels
fm1 <- ordinal::clm(rating ~ contact + temp, data = wine) summary(fm1) #> formula: rating ~ contact + temp #> data: wine #> #> link threshold nobs logLik AIC niter max.grad cond.H #> logit flexible 72 -86.49 184.98 6(0) 4.01e-12 2.7e+01 #> #> Coefficients: #> Estimate Std.Error z value Pr(>|z|) #> contactyes 1.5278 0.4766 3.205 0.00135 ** #> tempwarm 2.5031 0.5287 4.735 2.19e-06 *** #> --- #> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 #> #> Threshold coefficients: #> Estimate Std.Error z value #> 1|2 -1.3444 0.5171 -2.600 #> 2|3 1.2508 0.4379 2.857 #> 3|4 3.4669 0.5978 5.800 #> 4|5 5.0064 0.7309 6.850 #> #> confint(fm1) #> 2.5 % 97.5 % #> tempwarm 1.5097627 3.595225 #> contactyes 0.6157925 2.492404- Model: \(\mbox{logit}(P(Y_i \le j)) = \theta_j − \beta_1(\mbox{temp}_i ) − \beta_2(\mbox{contact}_i)\)
- Response is wine rating (1 to 5 = most bitter)
- The response variable should be an ordered factor class
- In this example, both explanatory variables were factor variables.
- The response variable should be an ordered factor class
- cond.H - Located in top row of GOF metrics. The condition number of the Hessian is a measure of how identifiable the model is.
- Values larger than 1e4 indicate that the model may be ill defined
- Regression Coefficients
- temp: \(\beta_1(\mbox{warm} − \mbox{cold}) = 2.50\)
- The reference level is cold, and this is the effect of moving from cold to warm
- contact: \(\beta_2(\mbox{yes} − \mbox{no}) = 1.53\)
- The odds ratio of bitterness being rated in category \(j\) or above (\(\mbox{OR}(Y ≥ j)\)) is \(e^{\beta_2(\mbox{yes − no})} = e^{1.53} = 4.61\).
- Note: this is \(\mbox{Pr}(Y \ge j)\) which is why we’re using the positive \(\beta\)
- The reference level is no, and this is the effect of moving from no to yes
- The odds ratio of bitterness being rated in category \(j\) or above (\(\mbox{OR}(Y ≥ j)\)) is \(e^{\beta_2(\mbox{yes − no})} = e^{1.53} = 4.61\).
- Interpretation:
- contact and warm temperature both lead to higher probabilities of observations in the high categories
- Holding contact at its reference level (no), this says that having warm wine instead of a cold wine increases the log odds of the wine tasting more bitter by 2.50 times.
- The odds of the rating being higher are \(4.61\) times greater when contact = yes than when contact = no.
- temp: \(\beta_1(\mbox{warm} − \mbox{cold}) = 2.50\)
See Cumulative Link Model >> Latent Variable Concept for details on Thresholds
emmeans(fm1, ~ cut|contact+temp, mode = "linear.predictor") #> contact = no, temp = cold: #> cut emmean SE df asymp.LCL asymp.UCL #> 1|2 -1.344 0.517 Inf -2.3579 -0.331 #> 2|3 1.251 0.438 Inf 0.3926 2.109 #> 3|4 3.467 0.598 Inf 2.2953 4.638 #> 4|5 5.006 0.731 Inf 3.5739 6.439 #> #> contact = yes, temp = cold: #> cut emmean SE df asymp.LCL asymp.UCL #> 1|2 -2.872 0.587 Inf -4.0232 -1.721 #> 2|3 -0.277 0.407 Inf -1.0740 0.520 #> 3|4 1.939 0.488 Inf 0.9820 2.896 #> 4|5 3.479 0.597 Inf 2.3077 4.650 #> #> contact = no, temp = warm: #> cut emmean SE df asymp.LCL asymp.UCL #> 1|2 -3.847 0.645 Inf -5.1117 -2.583 #> 2|3 -1.252 0.460 Inf -2.1540 -0.351 #> 3|4 0.964 0.434 Inf 0.1123 1.815 #> 4|5 2.503 0.540 Inf 1.4441 3.562 #> #> contact = yes, temp = warm: #> cut emmean SE df asymp.LCL asymp.UCL #> 1|2 -5.375 0.768 Inf -6.8805 -3.870 #> 2|3 -2.780 0.531 Inf -3.8200 -1.740 #> 3|4 -0.564 0.408 Inf -1.3629 0.235 #> 4|5 0.976 0.459 Inf 0.0752 1.876 #> #> Results are given on the logit (not the response) scale. #> Confidence level used: 0.95- The thresholds from
summary(fm1)(aka intercepts) are \(\{\theta_j\} = \{−1.34, 1.25, 3.47, 5.01\}\)- Often the thresholds are not of primary interest, but they are an integral part of the model.
- It is not relevant to test whether the thresholds are equal to zero, so no p-values are provided for this test.
- Using {emmeans}, we see these are the ratings thresholds for when contact = no, temp = cold (the reference categories)
Use ANOVA to test for an interaction
fm1_inter <- clm(rating ~ contact * temp, data = wine, link = "logit") # drop1(fm1_inter, test = "Chisq") accomplishes the same thing as anova anova(fm1, fm1_inter) #> Likelihood ratio tests of cumulative link models: #> #> formula: link: threshold: #> fm1 rating ~ contact + temp logit flexible #> fm1_inter rating ~ contact * temp logit flexible #> #> no.par AIC logLik LR.stat df Pr(>Chisq) #> fm1 6 184.98 -86.492 #> fm1_inter 7 186.83 -86.416 0.1514 1 0.6972- No interaction which doesn’t totally surprise me given the EDA plot (See EDA >> Dot Plots), but I did think it’d be closer.
- Get Probabilities
probs_fm1 <- emmeans(fm1, specs = ~ contact+temp|rating, mode = "prob") #> rating = 1: #> contact temp prob SE df asymp.LCL asymp.UCL #> no cold 0.20679 0.08480 Inf 0.04055 0.3730 #> yes cold 0.05355 0.02980 Inf -0.00479 0.1119 #> no warm 0.02089 0.01320 Inf -0.00497 0.0467 #> yes warm 0.00461 0.00352 Inf -0.00230 0.0115 #> #> rating = 2: #> contact temp prob SE df asymp.LCL asymp.UCL #> no cold 0.57065 0.08680 Inf 0.40045 0.7409 #> yes cold 0.37765 0.08850 Inf 0.20416 0.5511 #> no warm 0.20142 0.07230 Inf 0.05965 0.3432 #> yes warm 0.05380 0.02670 Inf 0.00150 0.1061 #> #> rating = 3: #> contact temp prob SE df asymp.LCL asymp.UCL #> no cold 0.19229 0.06390 Inf 0.06708 0.3175 #> yes cold 0.44306 0.07940 Inf 0.28744 0.5987 #> no warm 0.50158 0.07500 Inf 0.35461 0.6485 #> yes warm 0.30421 0.07810 Inf 0.15122 0.4572 #> #> rating = 4: #> contact temp prob SE df asymp.LCL asymp.UCL #> no cold 0.02362 0.01380 Inf -0.00343 0.0507 #> yes cold 0.09582 0.04260 Inf 0.01237 0.1793 #> no warm 0.20049 0.06760 Inf 0.06798 0.3330 #> yes warm 0.36360 0.08670 Inf 0.19364 0.5336 #> #> rating = 5: #> contact temp prob SE df asymp.LCL asymp.UCL #> no cold 0.00665 0.00483 Inf -0.00281 0.0161 #> yes cold 0.02993 0.01730 Inf -0.00407 0.0639 #> no warm 0.07563 0.03780 Inf 0.00158 0.1497 #> yes warm 0.27378 0.09130 Inf 0.09479 0.4528 #> #> Confidence level used: 0.95- The slope estimates indicate that we should se higher probabilities for higher ratings when contact = yes, temp = warm (bottom rows in each rating), and that is indeed what we see.
- When a wine is produced at a warm temperature and [contact][temperature] with grape skins, there is a 27% chance that the wine will [rate][temperature] 5 on the bitterness scale.
The chance of achieving a rating at or below a certain rating (i.e. the sum of probabilities at and below a certain rating)
cum_probs <- emmeans( fm1, specs = ~ temp + contact | cut, mode = "cum.prob" ) cum_probs #> cut = 1|2: #> temp contact cumprob SE df asymp.LCL asymp.UCL #> cold no 0.20679 0.08480 Inf 0.04055 0.3730 #> warm no 0.02089 0.01320 Inf -0.00497 0.0467 #> cold yes 0.05355 0.02980 Inf -0.00479 0.1119 #> warm yes 0.00461 0.00352 Inf -0.00230 0.0115 #> #> cut = 2|3: #> temp contact cumprob SE df asymp.LCL asymp.UCL #> cold no 0.77744 0.07580 Inf 0.62894 0.9259 #> warm no 0.22230 0.07950 Inf 0.06642 0.3782 #> cold yes 0.43119 0.09970 Inf 0.23572 0.6267 #> warm yes 0.05841 0.02920 Inf 0.00122 0.1156 #> #> cut = 3|4: #> temp contact cumprob SE df asymp.LCL asymp.UCL #> cold no 0.96973 0.01750 Inf 0.93534 1.0041 #> warm no 0.72388 0.08680 Inf 0.55368 0.8941 #> cold yes 0.87425 0.05370 Inf 0.76904 0.9795 #> warm yes 0.36262 0.09420 Inf 0.17797 0.5473 #> #> cut = 4|5: #> temp contact cumprob SE df asymp.LCL asymp.UCL #> cold no 0.99335 0.00483 Inf 0.98389 1.0028 #> warm no 0.92437 0.03780 Inf 0.85033 0.9984 #> cold yes 0.97007 0.01730 Inf 0.93608 1.0041 #> warm yes 0.72622 0.09130 Inf 0.54722 0.9052 #> #> Confidence level used: 0.95- cut = 2|3 when temp = cold, contact = no says the probability of getting a rating of 2 or below under those conditions is 77.7%
- cut in the rating threshold
That chance of achieving a rating above a certain rating (i.e. the sum of probabilities above a certain rating)
emmeans(fm1, specs = ~ temp + contact | cut, mode = "exc.prob") #> cut = 1|2: #> temp contact exc.prob SE df asymp.LCL asymp.UCL #> cold no 0.79321 0.08480 Inf 0.62697 0.9595 #> warm no 0.97911 0.01320 Inf 0.95326 1.0050 #> cold yes 0.94645 0.02980 Inf 0.88812 1.0048 #> warm yes 0.99539 0.00352 Inf 0.98849 1.0023 #> #> cut = 2|3: #> temp contact exc.prob SE df asymp.LCL asymp.UCL #> cold no 0.22256 0.07580 Inf 0.07406 0.3711 #> warm no 0.77770 0.07950 Inf 0.62181 0.9336 #> cold yes 0.56881 0.09970 Inf 0.37334 0.7643 #> warm yes 0.94159 0.02920 Inf 0.88440 0.9988 #> #> cut = 3|4: #> temp contact exc.prob SE df asymp.LCL asymp.UCL #> cold no 0.03027 0.01750 Inf -0.00412 0.0647 #> warm no 0.27612 0.08680 Inf 0.10593 0.4463 #> cold yes 0.12575 0.05370 Inf 0.02053 0.2310 #> warm yes 0.63738 0.09420 Inf 0.45274 0.8220 #> #> cut = 4|5: #> temp contact exc.prob SE df asymp.LCL asymp.UCL #> cold no 0.00665 0.00483 Inf -0.00281 0.0161 #> warm no 0.07563 0.03780 Inf 0.00158 0.1497 #> cold yes 0.02993 0.01730 Inf -0.00407 0.0639 #> warm yes 0.27378 0.09130 Inf 0.09479 0.4528 #> #> Confidence level used: 0.95- cut = 2|3 when temp = cold, contact = no says the probability of getting a rating higher than 2 (i.e. 3, 4, or 5) under those conditions is 22.2%
- cut in the rating threshold
- Risk Differences using the different types of probabilities
Between Predictor Conditions
pairs(probs_fm1) #> rating = 1: #> contrast estimate SE df z.ratio p.value #> no cold - yes cold 0.1532 0.0698 Inf 2.194 0.1248 #> no cold - no warm 0.1859 0.0775 Inf 2.397 0.0776 #> no cold - yes warm 0.2022 0.0838 Inf 2.414 0.0745 #> yes cold - no warm 0.0327 0.0264 Inf 1.237 0.6029 #> yes cold - yes warm 0.0489 0.0273 Inf 1.792 0.2772 #> no warm - yes warm 0.0163 0.0106 Inf 1.529 0.4201 #> #> rating = 2: #> contrast estimate SE df z.ratio p.value #> no cold - yes cold 0.1930 0.0879 Inf 2.195 0.1245 #> no cold - no warm 0.3692 0.0956 Inf 3.861 0.0007 #> no cold - yes warm 0.5168 0.0907 Inf 5.700 <.0001 #> yes cold - no warm 0.1762 0.1120 Inf 1.567 0.3975 #> yes cold - yes warm 0.3238 0.0825 Inf 3.927 0.0005 #> no warm - yes warm 0.1476 0.0620 Inf 2.381 0.0808 #> #> rating = 3: #> contrast estimate SE df z.ratio p.value #> no cold - yes cold -0.2508 0.0808 Inf -3.105 0.0103 #> no cold - no warm -0.3093 0.0924 Inf -3.347 0.0045 #> no cold - yes warm -0.1119 0.0791 Inf -1.415 0.4898 #> yes cold - no warm -0.0585 0.0533 Inf -1.098 0.6909 #> yes cold - yes warm 0.1389 0.1040 Inf 1.339 0.5381 #> no warm - yes warm 0.1974 0.0801 Inf 2.465 0.0655 #> #> rating = 4: #> contrast estimate SE df z.ratio p.value #> no cold - yes cold -0.0722 0.0353 Inf -2.048 0.1705 #> no cold - no warm -0.1769 0.0615 Inf -2.876 0.0210 #> no cold - yes warm -0.3400 0.0858 Inf -3.964 0.0004 #> yes cold - no warm -0.1047 0.0709 Inf -1.476 0.4518 #> yes cold - yes warm -0.2678 0.0788 Inf -3.399 0.0038 #> no warm - yes warm -0.1631 0.0710 Inf -2.298 0.0985 #> #> rating = 5: #> contrast estimate SE df z.ratio p.value #> no cold - yes cold -0.0233 0.0140 Inf -1.659 0.3455 #> no cold - no warm -0.0690 0.0346 Inf -1.993 0.1906 #> no cold - yes warm -0.2671 0.0904 Inf -2.954 0.0166 #> yes cold - no warm -0.0457 0.0353 Inf -1.296 0.5656 #> yes cold - yes warm -0.2439 0.0835 Inf -2.919 0.0184 #> no warm - yes warm -0.1982 0.0770 Inf -2.572 0.0495 #> #> P value adjustment: tukey method for comparing a family of 4 estimates- This tests for statistical differences in probabilities
- The probability of a rating of 5 is 2% lower when contact = no, temp = cold rather than contact = yes, temp = cold
Between Response Categories
emmeans(fm1, specs = ~ rating|contact+temp, mode = "prob") |> pairs() #> contact = no, temp = cold: #> contrast estimate SE df z.ratio p.value #> rating1 - rating2 -0.363860 0.1540 Inf -2.362 0.1259 #> rating1 - rating3 0.014499 0.1250 Inf 0.116 1.0000 #> rating1 - rating4 0.183171 0.0901 Inf 2.032 0.2504 #> rating1 - rating5 0.200140 0.0864 Inf 2.317 0.1395 #> rating2 - rating3 0.378359 0.1290 Inf 2.925 0.0284 #> rating2 - rating4 0.547031 0.0921 Inf 5.942 <.0001 #> rating2 - rating5 0.563999 0.0883 Inf 6.385 <.0001 #> rating3 - rating4 0.168672 0.0571 Inf 2.952 0.0262 #> rating3 - rating5 0.185641 0.0613 Inf 3.027 0.0209 #> rating4 - rating5 0.016968 0.0109 Inf 1.550 0.5295 #> #> contact = yes, temp = cold: #> contrast estimate SE df z.ratio p.value #> rating1 - rating2 -0.324100 0.0866 Inf -3.744 0.0017 #> rating1 - rating3 -0.389514 0.0963 Inf -4.044 0.0005 #> rating1 - rating4 -0.042275 0.0585 Inf -0.723 0.9513 #> rating1 - rating5 0.023619 0.0371 Inf 0.637 0.9690 #> rating2 - rating3 -0.065414 0.1590 Inf -0.410 0.9941 #> rating2 - rating4 0.281825 0.1180 Inf 2.391 0.1176 #> rating2 - rating5 0.347719 0.0975 Inf 3.566 0.0033 #> rating3 - rating4 0.347239 0.0869 Inf 3.997 0.0006 #> rating3 - rating5 0.413133 0.0801 Inf 5.158 <.0001 #> rating4 - rating5 0.065894 0.0367 Inf 1.797 0.3755 #> #> contact = no, temp = warm: #> contrast estimate SE df z.ratio p.value #> rating1 - rating2 -0.180528 0.0670 Inf -2.695 0.0546 #> rating1 - rating3 -0.480688 0.0794 Inf -6.051 <.0001 #> rating1 - rating4 -0.179606 0.0729 Inf -2.465 0.0987 #> rating1 - rating5 -0.054739 0.0423 Inf -1.293 0.6953 #> rating2 - rating3 -0.300160 0.1210 Inf -2.472 0.0971 #> rating2 - rating4 0.000922 0.1230 Inf 0.008 1.0000 #> rating2 - rating5 0.125789 0.0943 Inf 1.334 0.6700 #> rating3 - rating4 0.301082 0.1230 Inf 2.454 0.1015 #> rating3 - rating5 0.425949 0.0950 Inf 4.484 0.0001 #> rating4 - rating5 0.124867 0.0668 Inf 1.871 0.3333 #> #> contact = yes, temp = warm: #> contrast estimate SE df z.ratio p.value #> rating1 - rating2 -0.049193 0.0244 Inf -2.013 0.2597 #> rating1 - rating3 -0.299602 0.0768 Inf -3.900 0.0009 #> rating1 - rating4 -0.358988 0.0876 Inf -4.096 0.0004 #> rating1 - rating5 -0.269176 0.0925 Inf -2.910 0.0298 #> rating2 - rating3 -0.250409 0.0713 Inf -3.514 0.0040 #> rating2 - rating4 -0.309794 0.0982 Inf -3.155 0.0139 #> rating2 - rating5 -0.219983 0.1040 Inf -2.105 0.2177 #> rating3 - rating4 -0.059386 0.1420 Inf -0.419 0.9936 #> rating3 - rating5 0.030425 0.1490 Inf 0.205 0.9996 #> rating4 - rating5 0.089811 0.1510 Inf 0.594 0.9760 #> #> P value adjustment: tukey method for comparing a family of 5 estimates- When contact = yes, temp = warm, you’re more likely to get a rating of 3 than a rating of 1 by 29.9%
Between Predictor Conditions
cum_probs |> pairs() #> cut = 1|2: #> contrast estimate SE df z.ratio p.value #> cold no - warm no 0.1859 0.0775 Inf 2.397 0.0776 #> cold no - cold yes 0.1532 0.0698 Inf 2.194 0.1248 #> cold no - warm yes 0.2022 0.0838 Inf 2.414 0.0745 #> warm no - cold yes -0.0327 0.0264 Inf -1.237 0.6029 #> warm no - warm yes 0.0163 0.0106 Inf 1.529 0.4201 #> cold yes - warm yes 0.0489 0.0273 Inf 1.792 0.2772 #> #> cut = 2|3: #> contrast estimate SE df z.ratio p.value #> cold no - warm no 0.5551 0.0914 Inf 6.071 <.0001 #> cold no - cold yes 0.3462 0.1010 Inf 3.433 0.0033 #> cold no - warm yes 0.7190 0.0885 Inf 8.128 <.0001 #> warm no - cold yes -0.2089 0.1330 Inf -1.571 0.3955 #> warm no - warm yes 0.1639 0.0682 Inf 2.404 0.0763 #> cold yes - warm yes 0.3728 0.0924 Inf 4.034 0.0003 #> #> cut = 3|4: #> contrast estimate SE df z.ratio p.value #> cold no - warm no 0.2459 0.0793 Inf 3.101 0.0104 #> cold no - cold yes 0.0955 0.0447 Inf 2.135 0.1421 #> cold no - warm yes 0.6071 0.0986 Inf 6.157 <.0001 #> warm no - cold yes -0.1504 0.1000 Inf -1.500 0.4376 #> warm no - warm yes 0.3613 0.1030 Inf 3.523 0.0024 #> cold yes - warm yes 0.5116 0.0926 Inf 5.524 <.0001 #> #> cut = 4|5: #> contrast estimate SE df z.ratio p.value #> cold no - warm no 0.0690 0.0346 Inf 1.993 0.1906 #> cold no - cold yes 0.0233 0.0140 Inf 1.659 0.3455 #> cold no - warm yes 0.2671 0.0904 Inf 2.954 0.0166 #> warm no - cold yes -0.0457 0.0353 Inf -1.296 0.5656 #> warm no - warm yes 0.1982 0.0770 Inf 2.572 0.0495 #> cold yes - warm yes 0.2439 0.0835 Inf 2.919 0.0184 #> #> P value adjustment: tukey method for comparing a family of 4 estimates- The cumulative probability of having a rating of 2 or smaller (cut = 2|3) is 56% higher for conditions temp = cold, contact = no than for temp = warm, contact = no. This difference is statistically significant.
Between Response Thresholds
emmeans( fm1, specs = ~ cut | temp + contact, mode = "cum.prob" ) |> pairs(infer = TRUE) |> dplyr::as_data_frame() |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> # A tibble: 24 × 7 #> contrast temp contact estimate asymp.LCL asymp.UCL p.value #> <fct> <fct> <fct> <dbl> <dbl> <dbl> <dbl> #> 1 1|2 - 2|3 cold no -0.571 -0.794 -0.348 0 #> 2 1|2 - 3|4 cold no -0.763 -0.97 -0.556 0 #> 3 1|2 - 4|5 cold no -0.787 -1.00 -0.572 0 #> 4 2|3 - 3|4 cold no -0.192 -0.356 -0.028 0.014 #> 5 2|3 - 4|5 cold no -0.216 -0.403 -0.029 0.016 #> 6 3|4 - 4|5 cold no -0.024 -0.059 0.012 0.318 #> 7 1|2 - 2|3 warm no -0.201 -0.387 -0.016 0.027 #> 8 1|2 - 3|4 warm no -0.703 -0.917 -0.489 0 #> 9 1|2 - 4|5 warm no -0.903 -1 -0.807 0 #> 10 2|3 - 3|4 warm no -0.502 -0.694 -0.309 0 #> 11 2|3 - 4|5 warm no -0.702 -0.89 -0.515 0 #> 12 3|4 - 4|5 warm no -0.2 -0.374 -0.027 0.016 #> 13 1|2 - 2|3 cold yes -0.378 -0.605 -0.15 0 #> 14 1|2 - 3|4 cold yes -0.821 -0.958 -0.683 0 #> 15 1|2 - 4|5 cold yes -0.917 -0.998 -0.835 0 #> 16 2|3 - 3|4 cold yes -0.443 -0.647 -0.239 0 #> 17 2|3 - 4|5 cold yes -0.539 -0.778 -0.299 0 #> 18 3|4 - 4|5 cold yes -0.096 -0.205 0.014 0.11 #> 19 1|2 - 2|3 warm yes -0.054 -0.122 0.015 0.182 #> 20 1|2 - 3|4 warm yes -0.358 -0.595 -0.121 0.001 #> 21 1|2 - 4|5 warm yes -0.722 -0.953 -0.49 0 #> 22 2|3 - 3|4 warm yes -0.304 -0.505 -0.104 0.001 #> 23 2|3 - 4|5 warm yes -0.668 -0.885 -0.451 0 #> 24 3|4 - 4|5 warm yes -0.364 -0.586 -0.141 0- For conditions temp = cold, contact = no, the bitterness rating stabilizes at the 3rd ratings threshold since it’s cumulative probability is already so high that moving to the 4th ratings threshold results in a non-statistically significant diffference (3|4 - 4|5, p-value = 0.318)
Between Predictor Conditions
exc_probs |> pairs(infer = TRUE) #> cut = 1|2: #> contrast estimate SE df asymp.LCL asymp.UCL z.ratio p.value #> cold no - warm no -0.1859 0.0775 Inf -0.3851 0.013314 -2.397 0.0776 #> cold no - cold yes -0.1532 0.0698 Inf -0.3327 0.026196 -2.194 0.1248 #> cold no - warm yes -0.2022 0.0838 Inf -0.4174 0.012995 -2.414 0.0745 #> warm no - cold yes 0.0327 0.0264 Inf -0.0351 0.100459 1.237 0.6029 #> warm no - warm yes -0.0163 0.0106 Inf -0.0436 0.011075 -1.529 0.4201 #> cold yes - warm yes -0.0489 0.0273 Inf -0.1191 0.021227 -1.792 0.2772 #> #> cut = 2|3: #> contrast estimate SE df asymp.LCL asymp.UCL z.ratio p.value #> cold no - warm no -0.5551 0.0914 Inf -0.7900 -0.320235 -6.071 <.0001 #> cold no - cold yes -0.3462 0.1010 Inf -0.6054 -0.087126 -3.433 0.0033 #> cold no - warm yes -0.7190 0.0885 Inf -0.9463 -0.491762 -8.128 <.0001 #> warm no - cold yes 0.2089 0.1330 Inf -0.1328 0.550570 1.571 0.3955 #> warm no - warm yes -0.1639 0.0682 Inf -0.3390 0.011257 -2.404 0.0763 #> cold yes - warm yes -0.3728 0.0924 Inf -0.6102 -0.135367 -4.034 0.0003 #> #> cut = 3|4: #> contrast estimate SE df asymp.LCL asymp.UCL z.ratio p.value #> cold no - warm no -0.2459 0.0793 Inf -0.4495 -0.042192 -3.101 0.0104 #> cold no - cold yes -0.0955 0.0447 Inf -0.2104 0.019419 -2.135 0.1421 #> cold no - warm yes -0.6071 0.0986 Inf -0.8604 -0.353801 -6.157 <.0001 #> warm no - cold yes 0.1504 0.1000 Inf -0.1072 0.407962 1.500 0.4376 #> warm no - warm yes -0.3613 0.1030 Inf -0.6247 -0.097816 -3.523 0.0024 #> cold yes - warm yes -0.5116 0.0926 Inf -0.7496 -0.273685 -5.524 <.0001 #> #> cut = 4|5: #> contrast estimate SE df asymp.LCL asymp.UCL z.ratio p.value #> cold no - warm no -0.0690 0.0346 Inf -0.1579 0.019943 -1.993 0.1906 #> cold no - cold yes -0.0233 0.0140 Inf -0.0593 0.012762 -1.659 0.3455 #> cold no - warm yes -0.2671 0.0904 Inf -0.4994 -0.034822 -2.954 0.0166 #> warm no - cold yes 0.0457 0.0353 Inf -0.0449 0.136306 1.296 0.5656 #> warm no - warm yes -0.1982 0.0770 Inf -0.3961 -0.000263 -2.572 0.0495 #> cold yes - warm yes -0.2439 0.0835 Inf -0.4584 -0.029271 -2.919 0.0184 #> #> Confidence level used: 0.95 #> Conf-level adjustment: tukey method for comparing a family of 4 estimates #> P value adjustment: tukey method for comparing a family of 4 estimates- The exceedance probability of having a rating of larger than 2 (cut = 2|3) is 56% higher for conditions temp = warm, contact = no than for temp = cold, contact = no. This difference is statistically significant.
- It seems to be the additive inverse (i.e. \(-1 \cdot a = -a\)) of the risk difference using cumulative probabilities.
Between Response Thresholds
emmeans( fm1, specs = ~ cut | temp + contact, mode = "exc.prob" ) |> pairs(infer = TRUE) |> dplyr::as_data_frame() |> dplyr::select(-SE, -df, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> # A tibble: 24 × 7 #> contrast temp contact estimate asymp.LCL asymp.UCL p.value #> <fct> <fct> <fct> <dbl> <dbl> <dbl> <dbl> #> 1 1|2 - 2|3 cold no 0.571 0.348 0.794 0 #> 2 1|2 - 3|4 cold no 0.763 0.556 0.97 0 #> 3 1|2 - 4|5 cold no 0.787 0.572 1.00 0 #> 4 2|3 - 3|4 cold no 0.192 0.028 0.356 0.014 #> 5 2|3 - 4|5 cold no 0.216 0.029 0.403 0.016 #> 6 3|4 - 4|5 cold no 0.024 -0.012 0.059 0.318 #> 7 1|2 - 2|3 warm no 0.201 0.016 0.387 0.027 #> 8 1|2 - 3|4 warm no 0.703 0.489 0.917 0 #> 9 1|2 - 4|5 warm no 0.903 0.807 1 0 #> 10 2|3 - 3|4 warm no 0.502 0.309 0.694 0 #> 11 2|3 - 4|5 warm no 0.702 0.515 0.89 0 #> 12 3|4 - 4|5 warm no 0.2 0.027 0.374 0.016 #> 13 1|2 - 2|3 cold yes 0.378 0.15 0.605 0 #> 14 1|2 - 3|4 cold yes 0.821 0.683 0.958 0 #> 15 1|2 - 4|5 cold yes 0.917 0.835 0.998 0 #> 16 2|3 - 3|4 cold yes 0.443 0.239 0.647 0 #> 17 2|3 - 4|5 cold yes 0.539 0.299 0.778 0 #> 18 3|4 - 4|5 cold yes 0.096 -0.014 0.205 0.11 #> 19 1|2 - 2|3 warm yes 0.054 -0.015 0.122 0.182 #> 20 1|2 - 3|4 warm yes 0.358 0.121 0.595 0.001 #> 21 1|2 - 4|5 warm yes 0.722 0.49 0.953 0 #> 22 2|3 - 3|4 warm yes 0.304 0.104 0.505 0.001 #> 23 2|3 - 4|5 warm yes 0.668 0.451 0.885 0 #> 24 3|4 - 4|5 warm yes 0.364 0.141 0.586 0- For wines with temp = cold, contact = no, the chance of exceeding a rating of 3 (3|4) is 2.4% higher than the chance of exceeding a rating of 4 (4|5). This difference is not statistically significant (p-value = 0.318).
- Risk Ratios using the different types of probabilities
Between Predictor Conditions
probs_fm1 |> regrid("log") |> contrast(method = "pairwise") |> summary(type = "response", infer = TRUE, by = NULL) #> contrast rating ratio SE df asymp.LCL asymp.UCL null z.ratio p.value #> no cold / yes cold 1 3.8619 1.6700 Inf 0.99091 15.051 1 3.116 0.0536 #> no cold / no warm 1 9.9001 4.9800 Inf 2.04138 48.012 1 4.554 0.0002 #> no cold / yes warm 1 44.8737 33.3000 Inf 4.36498 461.319 1 5.120 <.0001 #> yes cold / no warm 1 2.5635 1.5900 Inf 0.36797 17.859 1 1.521 0.9837 #> yes cold / yes warm 1 11.6195 6.1100 Inf 2.23570 60.390 1 4.668 0.0001 #> no warm / yes warm 1 4.5327 2.1500 Inf 1.02598 20.025 1 3.191 0.0417 #> no cold / yes cold 2 1.5111 0.3120 Inf 0.79084 2.887 1 2.000 0.7527 #> no cold / no warm 2 2.8332 0.9840 Inf 0.95341 8.419 1 2.999 0.0781 #> no cold / yes warm 2 10.6066 5.4900 Inf 2.08990 53.830 1 4.560 0.0002 #> yes cold / no warm 2 1.8750 0.7920 Inf 0.49853 7.052 1 1.488 0.9878 #> yes cold / yes warm 2 7.0193 3.2500 Inf 1.63946 30.053 1 4.203 0.0008 #> no warm / yes warm 2 3.7437 1.5900 Inf 0.98486 14.231 1 3.101 0.0563 #> no cold / yes cold 3 0.4340 0.1350 Inf 0.16327 1.154 1 -2.678 0.1999 #> no cold / no warm 3 0.3834 0.1330 Inf 0.12895 1.140 1 -2.760 0.1596 #> no cold / yes warm 3 0.6321 0.2090 Inf 0.22417 1.782 1 -1.388 0.9956 #> yes cold / no warm 3 0.8833 0.1030 Inf 0.61289 1.273 1 -1.065 1.0000 #> yes cold / yes warm 3 1.4564 0.4270 Inf 0.58119 3.650 1 1.284 0.9987 #> no warm / yes warm 3 1.6488 0.3810 Inf 0.79853 3.404 1 2.163 0.6053 #> no cold / yes cold 4 0.2465 0.1110 Inf 0.05999 1.013 1 -3.109 0.0549 #> no cold / no warm 4 0.1178 0.0587 Inf 0.02465 0.563 1 -4.289 0.0005 #> no cold / yes warm 4 0.0650 0.0388 Inf 0.00997 0.423 1 -4.576 0.0001 #> yes cold / no warm 4 0.4779 0.2340 Inf 0.10264 2.225 1 -1.506 0.9858 #> yes cold / yes warm 4 0.2635 0.1070 Inf 0.07382 0.941 1 -3.287 0.0299 #> no warm / yes warm 4 0.5514 0.1500 Inf 0.23510 1.293 1 -2.190 0.5800 #> no cold / yes cold 5 0.2222 0.1050 Inf 0.05049 0.978 1 -3.184 0.0427 #> no cold / no warm 5 0.0879 0.0461 Inf 0.01699 0.455 1 -4.639 0.0001 #> no cold / yes warm 5 0.0243 0.0178 Inf 0.00245 0.241 1 -5.079 <.0001 #> yes cold / no warm 5 0.3957 0.2410 Inf 0.05849 2.677 1 -1.521 0.9837 #> yes cold / yes warm 5 0.1093 0.0540 Inf 0.02322 0.515 1 -4.482 0.0002 #> no warm / yes warm 5 0.2762 0.1160 Inf 0.07419 1.028 1 -3.070 0.0623 #> #> Confidence level used: 0.95 #> Conf-level adjustment: sidak method for 30 estimates #> Intervals are back-transformed from the log scale #> P value adjustment: sidak method for 30 tests #> Tests are performed on the log scale- The code transforms the odds to the log scale, calculates pairwise differences, then transforms back to the probability scale.
- The probability of a wine rating of 1 is around 45 times greater when contact = no, temp = cold than when contact = yes, temp = warm.
- Note the huge standard errors and wide range between the upper and lower CIs
- The probabiity of a wine rating of 2 is around 51% higher (1.5111 - 1.0000) when contact = no, temp = cold than when contact = yes, temp = cold.
- Note that the CI contains 1 (where 1 indicates no statistical difference) which aligns with a p-value of 0.7527
Between Response Categories
emmeans( fm1, specs = ~ rating | temp + contact, mode = "prob" ) |> regrid("log") |> contrast(method = "pairwise") |> summary(type = "response", infer = TRUE, by = NULL) |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> contrast temp contact ratio asymp.LCL asymp.UCL p.value #> 1 rating1 / rating2 cold no 0.362 0.069 1.917 0.870 #> 2 rating1 / rating3 cold no 1.075 0.144 8.024 1.000 #> 3 rating1 / rating4 cold no 8.755 0.639 120.017 0.263 #> 4 rating1 / rating5 cold no 31.094 1.533 630.733 0.009 #> 5 rating2 / rating3 cold no 2.968 0.757 11.637 0.341 #> 6 rating2 / rating4 cold no 24.161 2.998 194.688 0.000 #> 7 rating2 / rating5 cold no 85.807 6.895 1067.782 0.000 #> 8 rating3 / rating4 cold no 8.141 1.739 38.125 0.000 #> 9 rating3 / rating5 cold no 28.914 4.083 204.767 0.000 #> 10 rating4 / rating5 cold no 3.551 0.666 18.925 0.447 #> 11 rating1 / rating2 warm no 0.104 0.017 0.621 0.002 #> 12 rating1 / rating3 warm no 0.042 0.005 0.379 0.000 #> 13 rating1 / rating4 warm no 0.104 0.008 1.390 0.180 #> 14 rating1 / rating5 warm no 0.276 0.016 4.647 0.998 #> 15 rating2 / rating3 warm no 0.402 0.099 1.633 0.772 #> 16 rating2 / rating4 warm no 1.005 0.141 7.176 1.000 #> 17 rating2 / rating5 warm no 2.663 0.258 27.471 1.000 #> 18 rating3 / rating4 warm no 2.502 0.628 9.973 0.736 #> 19 rating3 / rating5 warm no 6.632 1.061 41.451 0.035 #> 20 rating4 / rating5 warm no 2.651 0.511 13.760 0.903 #> 21 rating1 / rating2 cold yes 0.142 0.024 0.835 0.015 #> 22 rating1 / rating3 cold yes 0.121 0.015 0.996 0.049 #> 23 rating1 / rating4 cold yes 0.559 0.042 7.451 1.000 #> 24 rating1 / rating5 cold yes 1.789 0.108 29.688 1.000 #> 25 rating2 / rating3 cold yes 0.852 0.240 3.022 1.000 #> 26 rating2 / rating4 cold yes 3.941 0.556 27.913 0.623 #> 27 rating2 / rating5 cold yes 12.619 1.259 126.494 0.016 #> 28 rating3 / rating4 cold yes 4.624 1.035 20.659 0.039 #> 29 rating3 / rating5 cold yes 14.805 2.182 100.461 0.000 #> 30 rating4 / rating5 cold yes 3.202 0.610 16.819 0.620 #> 31 rating1 / rating2 warm yes 0.086 0.014 0.526 0.001 #> 32 rating1 / rating3 warm yes 0.015 0.002 0.149 0.000 #> 33 rating1 / rating4 warm yes 0.013 0.001 0.199 0.000 #> 34 rating1 / rating5 warm yes 0.017 0.001 0.333 0.000 #> 35 rating2 / rating3 warm yes 0.177 0.041 0.764 0.005 #> 36 rating2 / rating4 warm yes 0.148 0.021 1.063 0.070 #> 37 rating2 / rating5 warm yes 0.197 0.021 1.846 0.542 #> 38 rating3 / rating4 warm yes 0.837 0.212 3.298 1.000 #> 39 rating3 / rating5 warm yes 1.111 0.209 5.897 1.000 #> 40 rating4 / rating5 warm yes 1.328 0.276 6.396 1.000- When temp = cold, contact = no, the probability of the wine receiving a 1 rating is 1.075 times higher than the probability of receiving a 3 rating.
Between Predictor Conditions
cum_probs |> regrid("log") |> contrast(method = "pairwise") |> summary(type = "response", infer = TRUE, by = NULL) |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> contrast cut ratio asymp.LCL asymp.UCL p.value #> 1 cold no / warm no 1|2 9.900 2.110 46.444 0.000 #> 2 cold no / cold yes 1|2 3.862 1.020 14.627 0.043 #> 3 cold no / warm yes 1|2 44.874 4.584 439.258 0.000 #> 4 warm no / cold yes 1|2 0.390 0.058 2.609 0.963 #> 5 warm no / warm yes 1|2 4.533 1.059 19.409 0.033 #> 6 cold yes / warm yes 1|2 11.620 2.315 58.333 0.000 #> 7 cold no / warm no 2|3 3.497 1.229 9.955 0.006 #> 8 cold no / cold yes 2|3 1.803 0.930 3.497 0.141 #> 9 cold no / warm yes 2|3 13.310 2.574 68.822 0.000 #> 10 warm no / cold yes 2|3 0.516 0.132 2.010 0.969 #> 11 warm no / warm yes 2|3 3.806 1.024 14.148 0.042 #> 12 cold yes / warm yes 2|3 7.382 1.787 30.503 0.000 #> 13 cold no / warm no 3|4 1.340 0.950 1.888 0.193 #> 14 cold no / cold yes 3|4 1.109 0.946 1.301 0.676 #> 15 cold no / warm yes 3|4 2.674 1.191 6.004 0.004 #> 16 warm no / cold yes 3|4 0.828 0.551 1.244 0.982 #> 17 warm no / warm yes 3|4 1.996 0.944 4.220 0.104 #> 18 cold yes / warm yes 3|4 2.411 1.128 5.155 0.009 #> 19 cold no / warm no 4|5 1.075 0.957 1.206 0.750 #> 20 cold no / cold yes 4|5 1.024 0.979 1.071 0.926 #> 21 cold no / warm yes 4|5 1.368 0.932 2.007 0.253 #> 22 warm no / cold yes 4|5 0.953 0.848 1.071 0.996 #> 23 warm no / warm yes 4|5 1.273 0.912 1.776 0.471 #> 24 cold yes / warm yes 4|5 1.336 0.932 1.915 0.280- Wine with the condition temp = cold, contact = no is roughtly 3.5 times more likely to receive a bitterness rating of 2 or less than a wine with the conditions temp = warm, contact = no. This difference is statistically significant (p-value = 0.006)
Between Response Thresholds
emmeans( fm1, specs = ~ cut | temp + contact, mode = "cum.prob" ) |> regrid("log") |> contrast(method = "pairwise") |> summary(type = "response", infer = TRUE, by = NULL) |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> contrast temp contact ratio asymp.LCL asymp.UCL p.value #> 1 1|2 / 2|3 cold no 0.266 0.083 0.854 0.012 #> 2 1|2 / 3|4 cold no 0.213 0.062 0.739 0.003 #> 3 1|2 / 4|5 cold no 0.208 0.059 0.730 0.003 #> 4 2|3 / 3|4 cold no 0.802 0.618 1.041 0.200 #> 5 2|3 / 4|5 cold no 0.783 0.586 1.046 0.202 #> 6 3|4 / 4|5 cold no 0.976 0.934 1.020 0.903 #> 7 1|2 / 2|3 warm no 0.094 0.020 0.441 0.000 #> 8 1|2 / 3|4 warm no 0.029 0.005 0.184 0.000 #> 9 1|2 / 4|5 warm no 0.023 0.003 0.154 0.000 #> 10 2|3 / 3|4 warm no 0.307 0.122 0.776 0.002 #> 11 2|3 / 4|5 warm no 0.240 0.084 0.690 0.001 #> 12 3|4 / 4|5 warm no 0.783 0.581 1.056 0.253 #> 13 1|2 / 2|3 cold yes 0.124 0.028 0.546 0.000 #> 14 1|2 / 3|4 cold yes 0.061 0.012 0.323 0.000 #> 15 1|2 / 4|5 cold yes 0.055 0.010 0.301 0.000 #> 16 2|3 / 3|4 cold yes 0.493 0.267 0.911 0.010 #> 17 2|3 / 4|5 cold yes 0.444 0.224 0.884 0.007 #> 18 3|4 / 4|5 cold yes 0.901 0.774 1.050 0.591 #> 19 1|2 / 2|3 warm yes 0.079 0.016 0.389 0.000 #> 20 1|2 / 3|4 warm yes 0.013 0.002 0.097 0.000 #> 21 1|2 / 4|5 warm yes 0.006 0.001 0.060 0.000 #> 22 2|3 / 3|4 warm yes 0.161 0.050 0.520 0.000 #> 23 2|3 / 4|5 warm yes 0.080 0.019 0.336 0.000 #> 24 3|4 / 4|5 warm yes 0.499 0.258 0.968 0.030- The bitterness rating for wine with the condition temp = cold, contact = no stabilizes at the second ratings threshold since we no longer see significant differences after that point ((2|3 - 3|4, p-value = 0.20)
Between Predictor Conditions
exc_probs |> regrid("log") |> contrast(method = "revpairwise") |> summary(type = "response", infer = TRUE, by = NULL) |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> contrast cut ratio asymp.LCL asymp.UCL p.value #> 1 warm no / cold no 1|2 1.234 0.910 1.675 0.565 #> 2 cold yes / cold no 1|2 1.193 0.904 1.575 0.712 #> 3 cold yes / warm no 1|2 0.967 0.887 1.053 0.998 #> 4 warm yes / cold no 1|2 1.255 0.907 1.737 0.541 #> 5 warm yes / warm no 1|2 1.017 0.983 1.051 0.965 #> 6 warm yes / cold yes 1|2 1.052 0.962 1.150 0.871 #> 7 warm no / cold no 2|3 3.494 1.292 9.449 0.003 #> 8 cold yes / cold no 2|3 2.556 0.954 6.850 0.080 #> 9 cold yes / warm no 2|3 0.731 0.383 1.397 0.971 #> 10 warm yes / cold no 2|3 4.231 1.443 12.406 0.001 #> 11 warm yes / warm no 2|3 1.211 0.921 1.592 0.543 #> 12 warm yes / cold yes 2|3 1.655 0.995 2.754 0.055 #> 13 warm no / cold no 3|4 9.122 1.978 42.070 0.000 #> 14 cold yes / cold no 3|4 4.154 1.032 16.729 0.040 #> 15 cold yes / warm no 3|4 0.455 0.092 2.249 0.965 #> 16 warm yes / cold no 3|4 21.057 3.126 141.828 0.000 #> 17 warm yes / warm no 3|4 2.308 0.932 5.717 0.105 #> 18 warm yes / cold yes 3|4 5.069 1.459 17.608 0.002 #> 19 warm no / cold no 4|5 11.372 2.275 56.848 0.000 #> 20 cold yes / cold no 4|5 4.500 1.055 19.199 0.034 #> 21 cold yes / warm no 4|5 0.396 0.061 2.572 0.963 #> 22 warm yes / cold no 4|5 41.168 4.349 389.707 0.000 #> 23 warm yes / warm no 4|5 3.620 1.000 13.111 0.050 #> 24 warm yes / cold yes 4|5 9.148 2.007 41.693 0.000contrast(method = "revpairwise")just reverses the order of the categories in the contrast calculation. For example, with “pairwise”, the first row is cold no / warm no- Wine with the condition temp = warm, contact = no is roughtly 3.5 times more likely to receive a bitterness rating greater than 2 than a wine with the conditions temp = cold, contact = no. This difference is statistically significant (p-value = 0.003)
Between Response Thresholds
emmeans( fm1, specs = ~ cut | temp + contact, mode = "exc.prob" ) |> regrid("log") |> contrast(method = "pairwise") |> summary(type = "response", infer = TRUE, by = NULL) |> dplyr::select(-SE, -df, -null, -z.ratio) |> dplyr::mutate(dplyr::across(dplyr::where(is.numeric), ~ round(.x, 3))) #> contrast temp contact ratio asymp.LCL asymp.UCL p.value #> 1 1|2 / 2|3 cold no 3.564 1.371 9.264 0.001 #> 2 1|2 / 3|4 cold no 26.205 4.787 143.443 0.000 #> 3 1|2 / 4|5 cold no 119.272 13.836 1028.180 0.000 #> 4 2|3 / 3|4 cold no 7.353 2.153 25.109 0.000 #> 5 2|3 / 4|5 cold no 33.466 5.948 188.298 0.000 #> 6 3|4 / 4|5 cold no 4.551 1.311 15.807 0.004 #> 7 1|2 / 2|3 warm no 1.259 0.941 1.684 0.305 #> 8 1|2 / 3|4 warm no 3.546 1.367 9.196 0.001 #> 9 1|2 / 4|5 warm no 12.947 2.813 59.588 0.000 #> 10 2|3 / 3|4 warm no 2.817 1.243 6.383 0.002 #> 11 2|3 / 4|5 warm no 10.283 2.445 43.244 0.000 #> 12 3|4 / 4|5 warm no 3.651 1.167 11.420 0.012 #> 13 1|2 / 2|3 cold yes 1.664 1.013 2.734 0.039 #> 14 1|2 / 3|4 cold yes 7.527 2.078 27.256 0.000 #> 15 1|2 / 4|5 cold yes 31.625 5.415 184.702 0.000 #> 16 2|3 / 3|4 cold yes 4.523 1.549 13.208 0.000 #> 17 2|3 / 4|5 cold yes 19.006 3.799 95.101 0.000 #> 18 3|4 / 4|5 cold yes 4.202 1.259 14.026 0.006 #> 19 1|2 / 2|3 warm yes 1.057 0.969 1.154 0.715 #> 20 1|2 / 3|4 warm yes 1.562 0.998 2.445 0.053 #> 21 1|2 / 4|5 warm yes 3.636 1.310 10.092 0.002 #> 22 2|3 / 3|4 warm yes 1.477 0.993 2.198 0.060 #> 23 2|3 / 4|5 warm yes 3.439 1.276 9.267 0.003 #> 24 3|4 / 4|5 warm yes 2.328 0.990 5.475 0.056- For wines with temp = cold, contact = no, the chance of exceeding a rating of 3 (3|4) is 4.55 times higher (or 355% higher) than the chance of exceeding a rating of 4 (4|5). This difference is statistically significant (p-value = 0.004).
- Visualizations
Effects and Thresholds
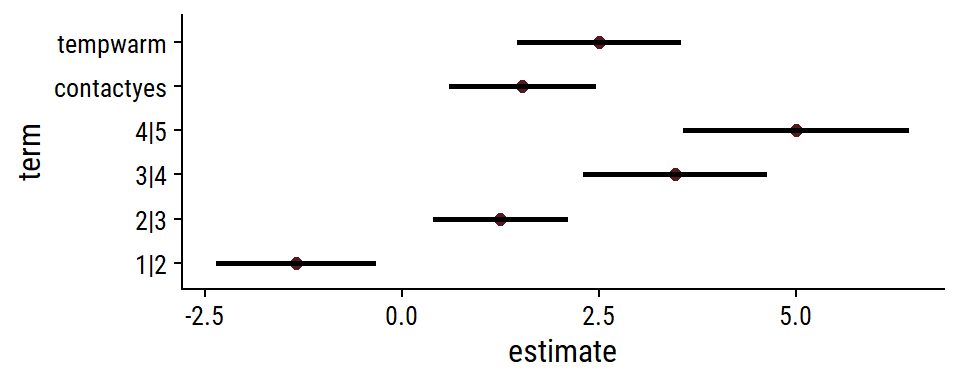
Code
tidy(fm1, conf.int = TRUE, conf.type = "Wald") %>% ggplot(aes(y = term, x = estimate)) + geom_point(size = 2) + geom_linerange(size = 1, aes(xmin = conf.low, xmax = conf.high))- Effect sizes are logits and thresholds are also on the log scale.
Exponentiate and Summarize
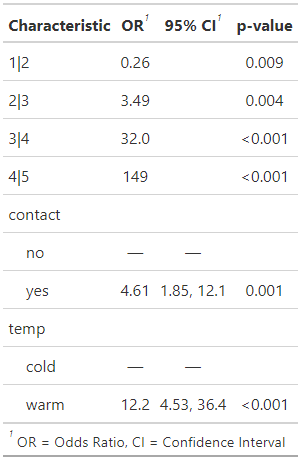
Code
gtsummary::tbl_regression(fm1, exponentiate = TRUE, intercept = TRUE)- Not sure the PO model threshold CIs weren’t calculated.
Visualizing the uncertainty allows us to see ratings with overlap (likely no difference) and no overlap (likely a difference)
Predicted Probabilities
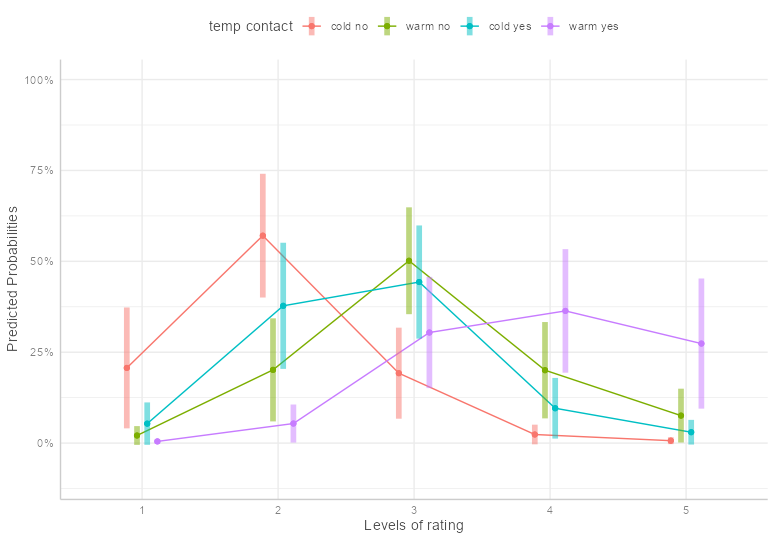
Code
theme_set(ggeffects::theme_ggeffects()) emmip(fm1, temp + contact ~ rating, mode = "prob", dodge = 0.3, CIs = TRUE) + theme(legend.position = "top") + scale_y_continuous(labels = scales::percent, limits = c(-0.1, 1)) + ylab("Predicted Probabilities")- Temperature and Contact vs Rating
Cumulative Probabilities
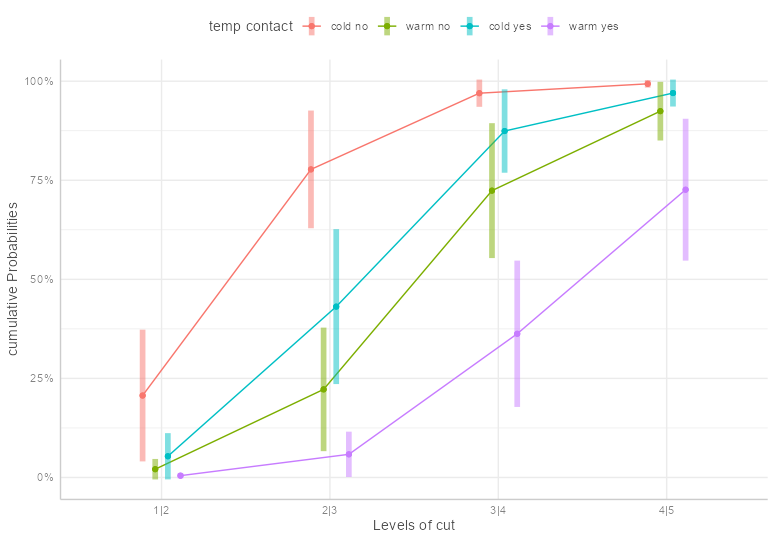
Code
theme_set(ggeffects::theme_ggeffects()) emmip( fm1, temp + contact ~ cut, mode = "cum.prob", dodge = 0.3, CIs = TRUE ) + theme(legend.position = "top") + scale_y_continuous(labels = scales::percent) + ylab("cumulative Probabilities")- “Levels of Cut” are the rating thresholds
Exceedance Probabilities
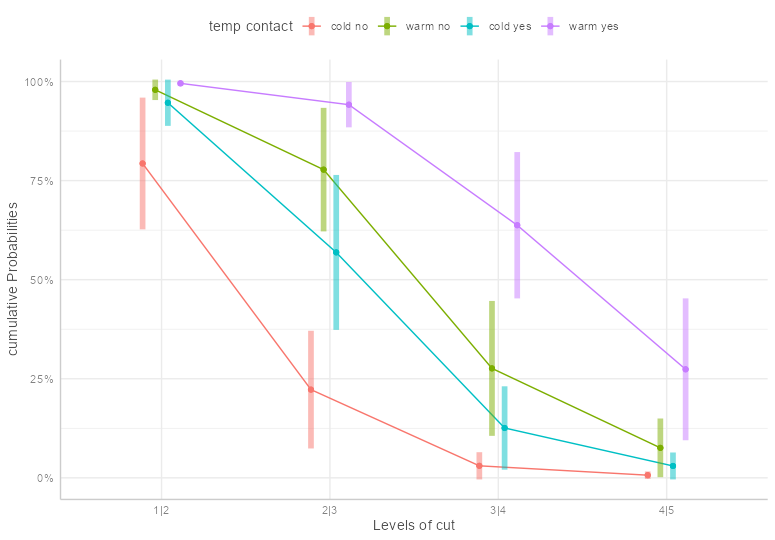
Code
theme_set(ggeffects::theme_ggeffects()) emmip( fm1, temp + contact ~ cut, mode = "exc.prob", dodge = 0.3, CIs = TRUE ) + theme(legend.position = "top") + scale_y_continuous(labels = scales::percent) + ylab("cumulative Probabilities")Example 2: Weighted Complimentary Log-Log Link, Comparing Links
Data
Code
#> year pct income #> 1 1960 6.5 0-3 #> 2 1960 8.2 3-5 #> 3 1960 11.3 5-7 #> 4 1960 23.5 7-10 #> 5 1960 15.6 10-12 #> 6 1960 12.7 12-15 #> 7 1960 22.2 15+ #> 8 1970 4.3 0-3 #> 9 1970 6.0 3-5 #> 10 1970 7.7 5-7 #> 11 1970 13.2 7-10 #> 12 1970 10.5 10-12 #> 13 1970 16.3 12-15 #> 14 1970 42.1 15+- income (ordered factor) are intervals in thousands of 1973 US dollars
- pct (numeric) is percent of the population in that income bracket from that particular year
- year (factor)
Comparing multiple links
> links <- c("logit", "probit", "cloglog", "loglog", "cauchit") > sapply(links, function(link) { ordinal::clm(income ~ year, data = income, weights = pct, link = link)$logLik }) #> logit probit cloglog loglog cauchit #> -353.3589 -353.8036 -352.8980 -355.6028 -352.8434- The cauchy distribution has the highest log-likelihood and is therefore the best fit to the data, but is closely followed by the complementary log-log link
Fit the cloglog for interpretation convenience
mod <- clm(income ~ year, data = income, weights = pct, link = "cloglog") summary(mod) #> link threshold nobs logLik AIC niter max.grad cond.H #> cloglog flexible 200.1 -352.90 719.80 6(0) 1.87e-11 7.8e+01 #> #> Estimate Std. Error z value Pr(>|z|) #> year1970 0.5679 0.1749 3.247 0.00116 ** #> #> Threshold coefficients: #> Estimate Std. Error z value #> 0-3|3-5 -2.645724 0.310948 -8.509 #> 3-5|5-7 -1.765970 0.210267 -8.399 #> 5-7|7-10 -1.141808 0.164710 -6.932 #> 7-10|10-12 -0.398434 0.132125 -3.016 #> 10-12|12-15 0.004931 0.123384 0.040 #> 12-15|15+ 0.418985 0.120193 3.486- ** The uncertainty of parameter estimates depends on the sample size, which is unknown here, so hypothesis tests should not be considered **
- Interpretation
“If \(p_{1960}(x)\) is proportion of the population with an income larger than \(x\) in 1960 and \(p_{1970}(x)\) is the equivalent in 1970, then approximately”
\[\begin{aligned} \log p_{1960} (x) &= e^{\hat\beta} \log p_{1970}(x) \\ &= e^{0.568} \log p_{1970}(x) \end{aligned}\]
So for any income dollar amount, the proportion of the population in 1960 (or 1970 w/some algebra) with that income or greater can be estimated.
Example 3: {MASS::polr} (article)
m <- polr(apply ~ pared + public + gpa, data = dat, Hess = TRUE) summary(m) ## Coefficients: ## Value Std. Error t value ## pared 1.0477 0.266 3.942 ## public -0.0588 0.298 -0.197 ## gpa 0.6159 0.261 2.363 ## ## Intercepts: ## Value Std. Error t value ## unlikely|somewhat likely 2.204 0.780 2.827 ## somewhat likely|very likely 4.299 0.804 5.345 ## ## Residual Deviance: 717.02 ## AIC: 727.02Response: apply to grad school with levels: unlikely, somewhat likely, and very likely (coded 1, 2, and 3)
- The researchers believe there is a greater distance between somewhat likely and very likely than somewhat likely and unlikely.
- See Cumulative Link Models (CLM) >> Structured Thresholds
- The researchers believe there is a greater distance between somewhat likely and very likely than somewhat likely and unlikely.
Explanatory:
- pared - Parent’s Education (0/1), Graduate School or Not
- public - Public School or Not (i.e. Private) (0/1)
- gpa (numeric)
Model
\[\begin{aligned} \mbox{logit}(\hat P(Y\le 1)) &= (2.20-1.05) \times (\mbox{pared}-(-0.06)) \times (\mbox{public}-0.616) \times \mbox{gpa} \\ \mbox{logit}(\hat P(Y\le 2)) &= (4.30-1.05) \times (\mbox{pared}-(-0.06)) \times (\mbox{public}-0.616) \times \mbox{gpa} \end{aligned}\]
- Equation shows the thresholds (aka cutpoints) as intercepts and the minus sign propugated through the rest of the regression equation
Add p-values to the summary table
## store table (ctable <- coef(summary(m))) ## calculate and store p values p <- pnorm(abs(ctable[, "t value"]), lower.tail = FALSE) * 2 ## combined table (ctable <- cbind(ctable, "p value" = p))CIs:
- Profile CIs:
confint(m) - Assuming normality:
confint.default(m)
- Profile CIs:
Interpretation:
In Ordered Log Odds (aka Ordered Logits)
- pared: For a one unit increase in pared (i.e., going from 0 to 1), we expect a \(1.05\) increase in the expected value of apply on the log odds scale, given all of the other variables in the model are held constant.
- gpa: For one unit increase in gpa, we would expect a \(0.62\) increase in the expected value of apply in the log odds scale, given that all of the other variables in the model are held constant
In Odds Ratios (aka Proportional Odds Ratios): (w/CIs
exp(cbind(OR = coef(m), ci = confint(m))- This is a Proportional Odds Model so the effect size is the same at all levels of the response variable.
- pared:
- For students whose parents did have a graduate degree, the odds of being more likely (i.e., very or somewhat likely versus unlikely) to apply is \(2.85\) times that of students whose parents did NOT have a graduate degree, holding constant all other variables.
- For students whose parents did have a graduate degrees, the odds of being less likely to apply (i.e., unlikely versus somewhat or very likely) is \(2.85\) times that of students whose parents did NOT have a graduate degree, holding constant all other variables.
- public
- For students in public school, the odds of being more likely (i.e., very or somewhat likely versus unlikely) to apply is \(5.71\%\) lower [i.e., (\(1 -0.943) \times 100\%\)] than private school students, holding constant all other variables.
- For students in private school, the odds of being more likely to apply is \(1.06\) times [i.e., \(\frac{1}{0.943}\)] that of public school students, holding constant all other variables (positive odds ratio).
- For students in private school, the odds of being less likely to apply (i.e., unlikely versus somewhat or very likely) is \(5.71\%\) lower than public school students, holding constant all other variables.
- For students in public school, the odds of being less likely to apply is \(1.06\) times that of private school students, holding constant all other variables (positive odds ratio).
- For students in public school, the odds of being more likely (i.e., very or somewhat likely versus unlikely) to apply is \(5.71\%\) lower [i.e., (\(1 -0.943) \times 100\%\)] than private school students, holding constant all other variables.
- gpa
- For every one unit increase in student’s GPA the odds of being more likely to apply (very or somewhat likely versus unlikely) is multiplied \(1.85\) times (i.e., increases \(85\%\)), holding constant all other variables.
- For every one unit decrease in student’s GPA the odds of being less likely to apply (unlikely versus somewhat or very likely) is multiplied \(1.85\) times, holding constant all other variables.
Predictions:
predict(m, data = newdat, type = "probs")Plot Predictions
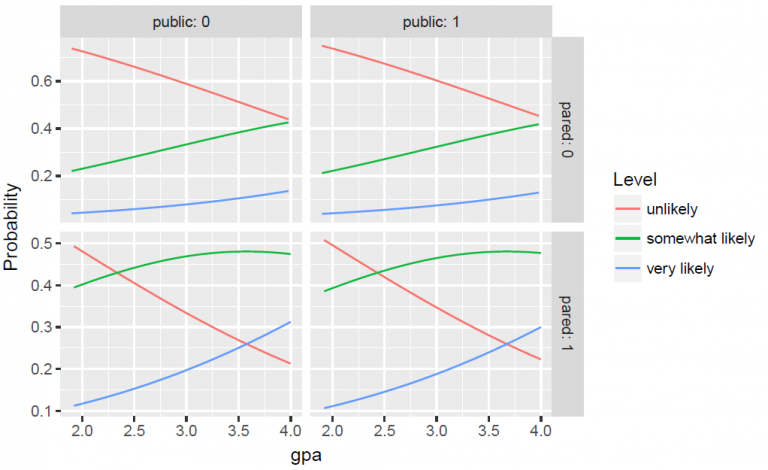
Code
newdat <- cbind(newdat, predict(m, newdat, type = "probs")) lnewdat <- melt(newdat, id.vars = c("pared", "public", "gpa"), variable.name = "Level", value.name="Probability") ggplot(lnewdat, aes(x = gpa, y = Probability, colour = Level)) + geom_line() + facet_grid(pared ~ public, labeller="label_both")
Partial Proportional Odds (PPO)
Also referred to as Unequal Slopes, Partial Effects, and Nominal Effects
\(\beta\)s are allowed to vary with \(j\) (ordinal outcome levels) or equivalently, the threshold parameters \(\{\theta_j\}\) are allowed to depend on regression variables.
- i.e In PO, it was assumed that the independent variable effect is the same for all levels of the ordinal outcome variable. The PPO model allows that effect to vary according to the outcome variable level.
Used when the proportional odds assumption is violated (or a generalized ordered probit model is also recommended)
Two sets of thresholds are applied at conditions with and without an explanatory variable
See Cumulative Link Models (CLM) >> Model for how the PPO term fits into the model equation (e.g. \(\tilde \beta\))
Example 1: {ordinal}
fm.nom <- clm(rating ~ temp, nominal = ~ contact, data = wine) summary(fm.nom) #> link threshold nobs logLik AIC niter max.grad cond.H #> logit flexible 72 -86.21 190.42 6(0) 1.64e-10 4.8e+01 #> #> Estimate Std.Error z.value Pr(>|z|) #> tempwarm 2.519 0.535 4.708 2.5e-06 *** #> #> Threshold coefficients: #> Estimate Std.Error z.value #> 1|2.(Intercept) -1.3230 0.5623 -2.353 #> 2|3.(Intercept) 1.2464 0.4748 2.625 #> 3|4.(Intercept) 3.5500 0.6560 5.411 #> 4|5.(Intercept) 4.6602 0.8604 5.416 #> 1|2.contactyes -1.6151 1.1618 -1.390 #> 2|3.contactyes -1.5116 0.5906 -2.559 #> 3|4.contactyes -1.6748 0.6488 -2.581 #> 4|5.contactyes -1.0506 0.8965 -1.172- See Proportional Odds >> Example 1 for variable descriptions
- PPO is for contact
- Model: \(\mbox{logit}(P(Y_i \le j)) = \theta_j + \tilde{\beta}_j (\mbox{contact}_i) − \beta(\mbox{temp}_i)\)
- Two sets of thresholds are applied at conditions with (yes) and without (no) contact
- Response variable should be an ordered factor class
- In this example, both explanatory variables were factor variables.
- It is not possible to estimate both \(\beta_2(\mbox{contact}_i)\) and \(\tilde{\beta}_j(\mbox{contact}_i)\) in the same model. Consequently variables that appear in nominal cannot enter in the formula as well
- Results
- \(\hat \beta(\mbox{warm} − \mbox{cold}) = 2.52\)
- The reference level is cold, and this is the effect of moving from cold to warm
- \(\{\hat \theta_j\} = \{−1.32, 1.25, 3.55, 4.66\}\)
- \({\hat{\tilde \beta_j} (\mbox{yes} − \mbox{no})} = \{−1.62, − 1.51, − 1.67, − 1.05\}\)
- \(\hat \beta(\mbox{warm} − \mbox{cold}) = 2.52\)
- Partial Effects: The odds ratio of bitterness being rated in category \(j\) or above (\(\mbox{OR}(Y \ge j)\)) now vary with \(j\):
- \(\mbox{ORs} = e^{-\hat{\tilde \beta}_j (\mbox{yes}− \mbox{no})} = e^{\{-(-1.6151), -(-1.5116), -(-1.6748), -(-1.0506)\}} = \{5.03, 4.53, 5.34, 2.86\}\)
- Me: The odds of the rating being greater or equal to \(2\) are \(4.53\) times greater when contact = yes than when contact = no.
Example 2: Test the PO assumption for 1 variable w/LR Test
anova(fm1, fm.nom) #> formula: nominal: link: threshold: #> fm1 rating ~ temp + contact ~1 logit flexible #> fm.nom rating ~ temp ~contact logit flexible #> #> no.par AIC logLik LR.stat df Pr(>Chisq) #> fm1 6 184.98 -86.492 #> fm.nom 9 190.42 -86.209 0.5667 3 0.904- fm1 model from Proportional Odds >> Example 1, but the formula column in the summary tells you what variables are in it.
- There is only little difference in the log-likelihoods of the two models and the test is insignificant (pval < 0.05). Thus, there is no evidence that the proportional odds assumption is violated for contact.
Example 3: Test the PO assumption for all variables w/LR Test
nominal_test(fm1) #> Df logLik AIC LRT Pr(>Chi) #> <none> -86.492 184.98 #> temp 3 -84.904 187.81 3.1750 0.3654 #> contact 3 -86.209 190.42 0.5667 0.9040Behavior of this function is similar to the
anovaexample above except the action is taken with every variable in the formula- If any variables are in the scale argument, they are also tested.
Note that contact has the same LRT pval as the previous example
No pvals < 0.05, therefore no violations of the PO assumption for any variable.
Scale Effects
Adding scale effects to a cumulative link model (CLM) involves modeling the variability of the latent variable in the model as a function of covariates, rather than assuming that the variability (or scale) is constant across observations.
i.e. A typical CLM assumes each observation is sampled from the same latent variable probability distribution with the same scale parameter.
Since a probit link models a latent variable (y*) probability distribution that’s Gaussian, the variance is modeled by using scale effects.
An alternative to partial proportional odds when nonproportional odds structures are encountered in the data. (i.e. the proportional odds assumption isn’t valid)
- Using scale effects is often a better approach, and it uses fewer parameters which often lead to more sensitive tests than nominal effects
- Commonly used when heteroskedasticity is present.
See Cumulative Link Models (CLM) >> Model for how scale effects fit into the model equation
The practical interpretation of the effect is only about the direction (increase or decrease) in probability and not by any amount. You can make direct calculations of the increase or decrease, by setting predictor values and using
predict. Marginal effects might also be possible as well. (See the Probit section for a more in-depth explanation of a similar situation.)Example 1: {ordinal}, Allow scale to vary according to a variable
fm.sca <- clm(rating ~ temp + contact, scale = ~ temp, data = wine) summary(fm.sca) #> link threshold nobs logLik AIC niter max.grad cond.H #> logit flexible 72 -86.44 186.88 8(0) 5.25e-09 1.0e+02 #> #> Estimate Std.Error z.value Pr(>|z|) #> tempwarm 2.6294 0.6860 3.833 0.000127 *** #> contactyes 1.5878 0.5301 2.995 0.002743 ** #> #> log-scale coefficients: #> Estimate Std.Error z.value Pr(>|z|) #> tempwarm 0.09536 0.29414 0.324 0.746 #> #> Threshold coefficients: #> Estimate Std.Error z value #> 1|2 -1.3520 0.5223 -2.588 #> 2|3 1.2730 0.4533 2.808 #> 3|4 3.6170 0.7774 4.653 #> 4|5 5.2982 1.2027 4.405Model
\[\begin{aligned} &\mbox{logit}(P(Y_i \le j)) = \frac{\theta_J - \beta_1(\mbox{temp}_i) - \beta_2(\mbox{contact}_i)}{e^{\zeta(\mbox{temp}_i)}} \\ &\text{where} \quad i = 1, \ldots, n \; \text{and} \; j=1, \ldots, J-1 \end{aligned}\]
- Scale parameter of the latent variable distribution varies by temp
- The scale term in the denominator. See Cumulative Link Models (CLM) >> Model for more details on this term
- Location parameter of the latent distribution is allowed to depend on both temp and contact
- The location expression is the numerator
- Scale parameter of the latent variable distribution varies by temp
Response variable should be an ordered factor class
- In this example, both explanatory variables were factor variables.
Results
- The location of the latent distribution is shifted \(2.63\sigma\) (scale units) when temperature is warm as compared to cold conditions and \(1.59\sigma\) when there’s presence (yes) of contact as compared to absence (no) of contact. (Reference levels: temp = cold, contact = no)
- We can’t interpret these effects directly like a typical model. Indirectly we see the shifts are positive, so the higher levels of the outcome variable are more likely for warm temperatures or when there’s contact. (See Probit effect interpretation. I think it should be similar since we’re talking about shifts in the location parameter of the y* distribution)
- We also could create a grid of every combination of the two factor predictor values and see how the predicted probabilities compare. {marginaleffects} would be useful for this.
- The scale of the latent distribution is \(\sigma\) at cold conditions but \(\sigma \times e^{\zeta(warm−cold)} = \sigma \times e^{0.095} = 1.10\sigma\) , i.e., \(10\%\) higher, at warm conditions.
- However, the p value for the scale effect in the summary output shows that the ratio of scales is not significantly different from 1 (or equivalently that the difference on the log-scale is not different from 0).
- Therefore, assuming the same scale for each observation would be okay and a different model should be tried (e.g. PPO). A different link and therefore different y* distribution with scale effects would also be an option.
- The location of the latent distribution is shifted \(2.63\sigma\) (scale units) when temperature is warm as compared to cold conditions and \(1.59\sigma\) when there’s presence (yes) of contact as compared to absence (no) of contact. (Reference levels: temp = cold, contact = no)
Example 2: Detect scale effects of variables
scale_test(fm1) #> Df logLik AIC LRT Pr(>Chi) #> <none> -86.492 184.98 #> temp 1 -86.439 186.88 0.10492 0.7460 #> contact 1 -86.355 186.71 0.27330 0.6011- fm1 comes from Proportional Odds (PO) >> Example 1
- Function has similar behavior to
nominal_test(see Partial Proportional Odds (PPO) >> Example 3) - No pvals < 0.05, therefore no evidence of scale effects for any variable.
- Note that the p-value for temp is the same as the one in the scale effects model results of Example 1.
Probit
- Also see When the Mean is Misleading: a Guide to Ordered Regression for Meaningfully Modeling Ordinal Outcomes
- Demonstrates the application of ordered probit models on criminology data. Includes R code that compares frequentist and Bayesian linear and multilevel approaches to ordinal modeling
- Assumes that the cumulative probabilities (i.e. latent variable, y*) follow a standard normal cumulative distribution and the residuals follow a normal distribution
- Same proportional odds assumption applies but not considered a “proportional odds model.”
- Because probit models involve a normal distribution for y*, the thresholds are standardized score values (i.e. z-scores), with most values occurring between approximately -3 and +3.
- As with a binary outcome, the logit and probit analysis will nearly always lead to the same conclusions
- Ordered probit regression is very, very similar to running an ordered logistic regression. The main difference is in the interpretation of the coefficients.
- The coefficients of represent the change in the z-score (standard normal quantile) for being at or below a certain category of the response for a one-unit change in the predictor.
- Example:
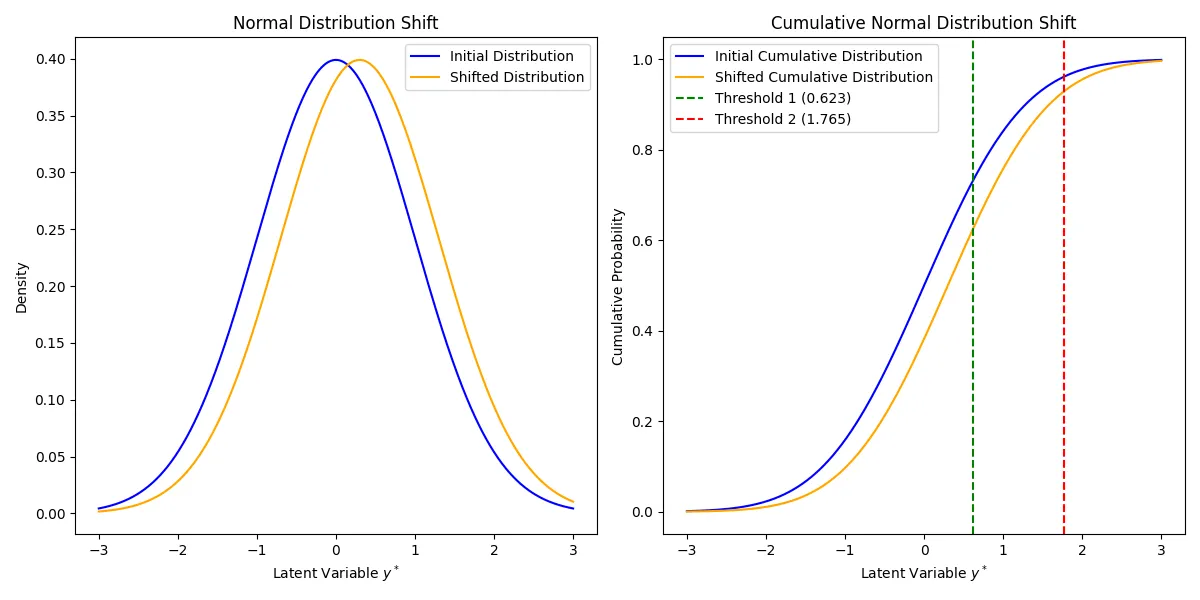
- Income is a predictor in a probit CLM. The estimated coefficient is 0.30.
- An increase in Income by one unit shifts the distribution of y* to the right by 0.30 standard deviations. This shift affects the probability of y* crossing the thresholds that define the ordinal categories.
- The probability that the outcome is in a particular category depends on the cumulative normal distribution function, \(\Phi\), evaluated at the thresholds and adjusted for the predictors. This shift translates into changes in the probabilities of the ordinal outcomes through the cumulative normal distribution function
- In general, for each one-unit increase in Income, the expected value of the latent variable, y* increases by 0.045 standard deviations.
- The practical interpretation of the effect is only about the direction (increase or decrease) in probability and not by any amount. You can make direct calculations of the increase or decrease, by setting predictor values and using
predict. Marginal effects might also be possible as well. (Also see the interpretation example)
- Example:
- Probability Calculation Given a Continuous Predictor
- To find the probability of being in each category for a given \(x\) value with thresholds \(\tau_1\) and \(\tau_2\), we can use the cumulative normal distribution:
- Category 1 (\(y = 1\)):
\[P(y = 1 | x) = P(y^* \leq \tau_1 | x) = \Phi(\tau_1 - \beta_0 - \beta_1 x)\] - Category 2 (\(y = 2\)):
\[P(y = 2 | x) = P(\tau_1 < y^* \leq \tau_2 | x) = \Phi(\tau_2 - \beta_0 - \beta_1 x) - \Phi(\tau_1 - \beta_0 - \beta_1 x)\] - Category 3 (\(y = 3\)):
\[P(y = 3 | x) = P(y^* > \tau_2 | x) = 1 - \Phi(\tau_2 - \beta_0 - \beta_1 x)\]
- Category 1 (\(y = 1\)):
- By plugging in specific values for \(x\), we can calculate these probabilities and see how they change with variations in \(x\).
- To find the probability of being in each category for a given \(x\) value with thresholds \(\tau_1\) and \(\tau_2\), we can use the cumulative normal distribution:
- Example: Interpreting a Continuous Predictor
- Outcome: Satisfaction, Predictor: Income
- Let \(\beta_0 = 0\) for simplicity and \(\beta_1 = 0.3\) with the thresholds \(\tau_1 = 0.623\) and \(\tau_2 = 1.765\).
- Initial Income = 0:
\[\begin{aligned} &P(y = 1 | \mbox{Income} = 0) = \Phi (0.623) \approx 0.734 \\ &P(y=2|\mbox{Income} = 0) = \Phi (1.765) - \Phi (0.623) \approx 0.226 \\ &P(y=3|\mbox{Income} = 0) = 1 - \Phi(1.765) \approx 0.040 \end{aligned}\] - Increased Income = 1:
\[\begin{aligned} &P(y = 1 | \mbox{Income} = 1) = \Phi (0.623-0.3) \approx 0.626 \\ &P(y=2|\mbox{Income} = 1) = \Phi (1.765-0.3) - \Phi (0.623-0.3) \approx 0.290 \\ &P(y=3|\mbox{Income} = 1) = 1 - \Phi(1.765-0.3) \approx 0.084 \end{aligned}\] - Interpretation
- As Income increases, the probability of being in the lowest satisfaction category (\(y = 1\)) decreases. The probability decreases because the threshold \(\tau_1\) becomes relatively smaller compared to the shifted latent variable y*. This means the cumulative probability up to \(\tau_1\) decreases.
- The probability of being in the medium satisfaction category (\(y = 2\)) increases.
- The probability of being in the highest satisfaction category (\(y = 3\)) increases.
- If \(\beta_1 = -0.3\), then:
- As Income increases, the probability of being in the lowest satisfaction category (\(y = 1\)) increases.
- The probability of being in the medium satisfaction category (\(y = 2\)) decreases.
- The probability of being in the highest satisfaction category (\(y = 3\)) decreases.
- Examples
Example 1: Probit, {brms} (article)
Ordinal_Fit <- brm(Response ~ Group, data = df, family = cumulative("probit"), seed = 8807, control = list(adapt_delta = 0.99), file = "Models/ordinal-fit.rds", file_refit = "never") # don't change file if model is updated # Add metrics for model comparison Ordinal_Fit <- add_criterion(Ordinal_Fit, c("loo", "waic", "bayes_R2"))
Generalized Ordinal Regression
- Todo
Mixed Effects
- Misc
- Also see Mixed Effects, General
- Papers
- Bayesian transition models for ordinal longitudinal outcomes
- Paper that’s a tutorial with examples in R
- Also in R >> Documents >> Regression >> Mixed Effects
- Harrell post describes the model
- A highly flexible longitudinal proportional odds logistic model for binary, ordinal, or continuous outcomes, with within-patient serial correlation handled through a simple Markov process in which the patient’s previous visit outcome level becomes a predictor for the outcome in the current time period.
- This is a discrete time state transition model, also called a multistate model, but extended to have an unlimited number of outcome states as long as they can be ordered.
- Bayesian transition models for ordinal longitudinal outcomes
- Example 1: Varying Intercepts Model
Model
clmm_mod <- clmm( rating ~ temp + contact + (1|judge), data = wine, link = "logit" ) # older function clmm2_mod <- clmm2( rating ~ temp + contact, random = judge, data = wine, link = "logistic", Hess = TRUE ) summary(clmm_mod) #> link threshold nobs logLik AIC niter max.grad cond.H #> logit flexible 72 -81.57 177.13 332(999) 1.03e-05 2.8e+01 #> #> Random effects: #> Groups Name Variance Std.Dev. #> judge (Intercept) 1.279 1.131 #> Number of groups: judge 9 #> #> Coefficients: #> Estimate Std. Error z value Pr(>|z|) #> tempwarm 3.0630 0.5954 5.145 2.68e-07 *** #> contactyes 1.8349 0.5125 3.580 0.000344 *** #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 #> #> Threshold coefficients: #> Estimate Std. Error z value #> 1|2 -1.6237 0.6824 -2.379 #> 2|3 1.5134 0.6038 2.507 #> 3|4 4.2285 0.8090 5.227 #> 4|5 6.0888 0.9725 6.261See Proportional Odds >> Example 1 for variable descriptions
Some extension functions work with
clmmand others work withclmm2- Confusingly,
clmmis the newer function, but the {ordinal} package owner stopped in the middle of developing it.
- Confusingly,
Compare with PO Model
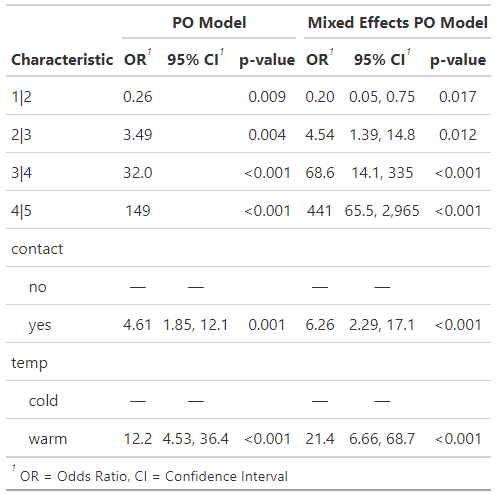
Code
fm1_tbl <- gtsummary::tbl_regression(fm1, exponentiate = TRUE, intercept = TRUE) clmm_tbl <- gtsummary::tbl_regression(clmm_mod, exponentiate = TRUE, intercept = TRUE) gtsummary::tbl_merge( tbls = list(fm1_tbl, clmm_tbl), tab_spanner = c("**PO Model**", "**Mixed Effects PO Model**") ) anova(fm1, clmm_mod) #> formula: link: threshold: #> fm1 rating ~ contact + temp logit flexible #> clmm_mod rating ~ temp + contact + (1 | judge) logit flexible #> #> no.par AIC logLik LR.stat df Pr(>Chisq) #> fm1 6 184.98 -86.492 #> clmm_mod 7 177.13 -81.565 9.853 1 0.001696 **- The mixed model produces the better fit.
- Not sure why the PO model threshold CIs weren’t calculated by {gtsummary}
Get Profile CIs
profile(clmm2_mod, nSteps = 30) |> confint() #> 2.5 % 97.5 % #> stDev 0.5014978 2.266741- Also see Confidence & Prediction Intervals >> Misc
- Package has only implemented the profile method for the variance estimate of the mixed model and can’t be used with the newer
clmmfunction - You either need to set Hess = TRUE in the model function or specify a range for the estimate in the
profilefunction.
Get Conditional Modes
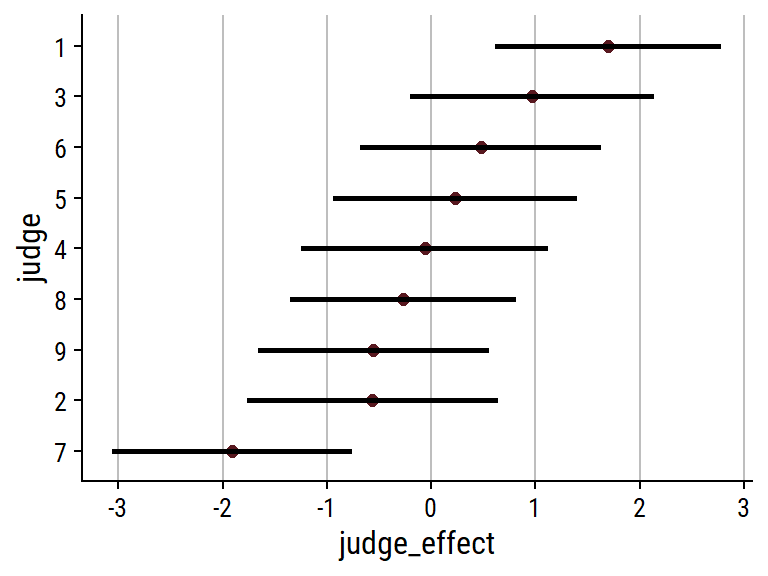
Code
tibble( judge_effect = clmm_mod$ranef, cond_var = clmm_mod$condVar ) |> mutate( judge = fct_reorder(factor(1:n()), judge_effect), conf.low = judge_effect - qnorm(0.975) * sqrt(cond_var), conf.high = judge_effect + qnorm(0.975) * sqrt(cond_var) ) |> ggplot(aes(y = judge, x = judge_effect)) + geom_point(size = 2) + geom_linerange(size = 1, aes(xmin = conf.low, xmax = conf.high)) + theme(panel.grid.major.x = element_line(color = "grey"))- With the fixed effect variables at their reference/baseline levels