Ensembling
Misc
- Packages
- {BayesBlend} (Vignette) - Easy Model Blending using Pseudo-Bayesian Model Averaging, Stacking and Hierarchical Stacking in Python
- {loo::stacking_weights} (Vignette) - Model averaging via stacking of predictive distributions
- {stacks} - Performs model stacking that aligns with the tidymodels
- Papers
- Bayesian Stacking (paper)
- Regressions where the coefficients are a simplex - Peter Ellis post
- Can be used to to determine weights in a ensemble
- 3 Methods: quadratic programming, a Dirichlet distribution in Stan, and using glmnet’s lower bound constraint
- May be better to used a ML model for the ensembling procedure since the features are probably highly correlated
- Feature-Weighted Linear Stacking (FWLS) (Paper)
- Incorporates meta-features for improved accuracy while retaining the well-known virtues of linear regression regarding speed, stability, and interpretability
- use of meta-features, additional inputs describing each observation in a dataset, can boost the performance of ensemble methods, but the greatest reported gains have come from nonlinear procedures requiring significant tuning and training time.
- Meta-features - should be discrete variables
- Example (product sales model): current season, year, information about the products, and vendors variables
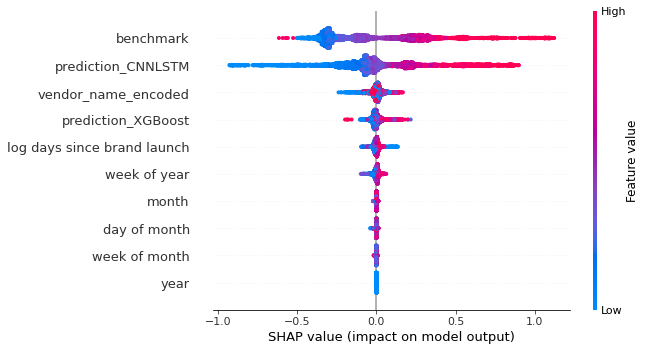
- “benchmark” is just a 28-day MA model, prediction_CNNLSTM is a DL model, and prediction_XGBoost is an xgboost model
- Example (product sales model): current season, year, information about the products, and vendors variables
- Need to read the paper but the article I read that used this method used predictors from the base models as these “meta-features.”
- Manually
With tidymodels objects from drob 1:58:08, Predicting box office performance
on_test_set <- function(d) { bind_cols(predict(mod_obj1, d) %>% rename(mod_name1 = .pred), predict(mod_ojt2, d) %>% rename(mod_name2 = .pred)) %>% augment(combination, newdata = .) %>% transmute(id = d$id, outcome_var = 2 ^ fitted # outcome was transformed with log2 during preprocessing on_test_set(test_set) %>% rename(.pred = outcome_var) %>% bind_cols(test) %>% rmse(log2(.pred), outcome_var) # loss metric is RMSLE (Root Mean Squared Log Error)
Stacks
Steps:
- Add models and tune a penalyzed regression model to determine weights
- blend_predictions args: penalty, mixture, metric, control
- control is for tune::control_grid
- metric used to determine penalty. Use the same one you used to tune the models.
- blend_predictions args: penalty, mixture, metric, control
lin_best <- lin_location_tune %>% filter_parameters(parameters = select_best(lin_location_tune)) xg_best <- xg_tune %>% filter_parameters(parameters = select_best(xg_tune)) lin_xg_blend <- stacks() %>% add_candidates(lin_best) %>% add_candidates(xg_best) %>% blend_predictions()- Fit the ensemble on the full training set
lin_xg_fit <- lin_xg_blend %>% fit_members()- Measure performance on the test set
predictions <- lin_xg_fit %>% predict(test, type = "prob", members = TRUE) # Log loss by model, or by the blend predictions %>% select(contains("_Rained")) %>% bind_cols(select(test, rain_tomorrow)) %>% gather(model, prediction, -rain_tomorrow) %>% mutate(prediction = 1 - prediction) %>% group_by(model) %>% mn_log_loss(rain_tomorrow, prediction)- Add models and tune a penalyzed regression model to determine weights
sklearn
Majority Vote
from sklearn.ensemble import VotingClassifier X, y = make_classification(n_samples=1000) ensemble = VotingClassifier( estimators=[ ("xgb", xgb.XGBClassifier(eval_metric="auc")), ("lgbm", lgbm.LGBMClassifier()), ("cb", cb.CatBoostClassifier(verbose=False)), ], voting="soft", # n_jobs=-1, ) _ = ensemble.fit(X, y)If the classes are probabilities or predictions are continuous, the predictions are averaged.
voting = “soft” says use probabilities
voting = “hard” says each model makes a binary classification (guessing 50/50 threshold), and the ensemble model tally’s up the votes to output its final result
weights argument can be used to assign different coefficients for more accurate models
votingRegressoralso available
Stacking
from sklearn.ensemble import StackingClassifier, StackingRegressor from sklearn.linear_model import LogisticRegression X, y = make_classification(n_samples=1000) ensemble = StackingClassifier( estimators=[ ("xgb", xgb.XGBClassifier(eval_metric="auc")), ("lgbm", lgbm.LGBMClassifier()), ("cb", cb.CatBoostClassifier(verbose=False)), ], final_estimator=LogisticRegression(), cv=5, passthrough=False # n_jobs=-1, ) _ = ensemble.fit(X, y)StackingRegressoralso available