Snippets
Misc
Packages
- {clevercsv} - Provides a drop-in replacement for the {csv} package with improved dialect detection for messy CSV files. It also provides a handy command line tool that can standardize a messy file or generate Python code to import it.
- {tabbed} (JOSS) - Similar to {clevercsv} except uses row length and type consistency measures to automatically detect metadata, header and data sections of a D(delimiter)SV file. Furthermore, tabbed provides a value-based conditional reader for reading these irregular DSV files at scale.
Convert datetime to local NYC time (source)
# Transform sunrise and sunset to datetime in NYC timezone from datetime import datetime, timezone from zoneinfo import ZoneInfo import time # Timestamp, Sunrise and Sunset to NYC timezone target_timezone = ZoneInfo("America/New_York") dt_utc = datetime.fromtimestamp(sunrise, tz=timezone.utc) sunrise_nyc = str(dt_utc.astimezone(target_timezone).time()) # get only sunrise time time dt_utc = datetime.fromtimestamp(sunset, tz=timezone.utc) sunset_nyc = str(dt_utc.astimezone(target_timezone).time()) # get only sunset time time dt_utc = datetime.fromtimestamp(timestamp, tz=timezone.utc) time_nyc = str(dt_utc.astimezone(target_timezone))- Also video on handling this in pandas
Regression formula (link)
# Dependent variable dependent = 'YConsumption' # Exogenous variables exog_vars = ['XAge', 'XMale1'] # Endogenous variable endog_vars = ['XIncomeEndo'] # Instrumental variables instruments = ['ZChildQuantity6', 'ZEducation'] formula = "{dep} ~ 1 + {exog} + [{endog} ~ {instr}]".format( dep = dependent, exog = '+'.join(exog_vars), endog = endog_vars[0], instr = '+'.join(instruments) )
Refactoring
Convert group of functions into a class
From pybites video
Group of functions before refactoring
api_config = { "api_url": "https://example.com/api", "api_key": "1234567890abcdef", } def setup_connection(api_url, api_key, user_id, session_token): print(f"Setting up connection to {api_url} with API key {api_key}, for user {user_id} with session {session_token}") def fetch_data(user_id, session_token): setup_connection(api_config['api_url'], api_config['api_key'], user_id, session_token) print(f"Fetching data for user {user_id} with session {session_token}") def process_data(user_id, session_token, data): setup_connection(api_config['api_url'], api_config['api_key'], user_id, session_token) print(f"Processing data {data} for user {user_id} with session {session_token}") def save_data(user_id, session_token, data): setup_connection(api_config['api_url'], api_config['api_key'], user_id, session_token) print(f"Saving data {data} for user {user_id} with session {session_token}")- Many of the functions have the same arguments
- Many of the functions call the same function
The created class after refactoring
class ApiClient: def __init__(self, config, user_id, session_token): self.api_url = config['api_url'] self.api_key = config['api_key'] self.user_id = user_id self.session_token = session_token self._setup_connection() def _setup_connection(self): print(f"Setting up connection to {self.api_url} with API key {self.api_key}, for user {self.user_id} with session {self.session_token}") def fetch_data(self): print(f"Fetching data for user {self.user_id} with session {self.session_token}") def process_data(self, data): print(f"Processing data {data} for user {self.user_id} with session {self.session_token}") def save_data(self, data): print(f"Saving data {data} for user {self.user_id} with session {self.session_token}") api_config = { "api_url": "https://example.com/api", "api_key": "1234567890abcdef", } client = ApiClient(api_config, 123, "abc") client.fetch_data() client.process_data("some data") client.save_data("some other data")
Gather a group of constants into an enum classs
From pybites video
Group of constants all related to a common concept (e.g. user status)
Enums are a class that makes code more organized and readable by grouping constants with common concepts into classes
Constants before refactoring
STATUS_ACTIVE = 1 STATUS_INACTIVE = 2 STATUS_PENDING = 3 STATUS_CANCELLED = 4 STATUS_COMPLETED = 5 def update_user_status(user_id: int, status: int): if status == STATUS_ACTIVE: print("Activating user") elif status == STATUS_INACTIVE: print("Deactivating user") # etc update_user_status(123, STATUS_ACTIVE) #> Activating userConstants after refactoring into an enum
from enum import Enum class Status(Enum): ACTIVE = 1 INACTIVE = 2 PENDING = 3 CANCELLED = 4 COMPLETED = 5 def update_user_status(user_id: int, status: Status): if status is Status.ACTIVE: print("Activating user") elif status is Status.INACTIVE: print("Deactivating user") # etc update_user_status(123, Status.INACTIVE) #> Deactivating user Status.ACTIVE.name #> 'ACTIVE' Status.INACTIVE.value #> 2 Status.__members__ #> mappingproxy({'ACTIVE': <Status.ACTIVE: 1>, #> 'INACTIVE': <Status.INACTIVE: 2>, #> ...etc}) type(Status.ACTIVE) #> <enum 'Status'>
ML Set-Up
# Suppress (annoying) warnings
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
ignore_warnings(category=ConvergenceWarning)
if not sys.warnoptions:
warnings.simplefilter("ignore")
os.environ["PYTHONWARNINGS"] = ('ignore::UserWarning,ignore::RuntimeWarning')
# Ensure logging
logging.basicConfig(
format='%(asctime)s:%(name)s:%(levelname)s - %(message)s',
level=logging.INFO,
handlers=[
logging.FileHandler("churn_benchmarking.log"),
logging.StreamHandler()
],
datefmt='%Y-%m-%d %H:%M:%S')
# Determine number of cpus available
n_cpus = mp.cpu_count()
logging.info(f"{n_cpus} cpus available")
# Visualize pipeline when calling it
set_config(display="diagram")
# Load prepared (pre-cleaned) files for benchmarking
file_paths = [f for f in glob.glob("00_data/*") if f.endswith('_cleaned.csv')]
file_names = [re.search('[ \w-]+?(?=\_cleaned.)',f)[0] for f in file_paths]
dfs = [pd.read_csv(df, low_memory=False) for df in file_paths]
data_sets = dict(zip(file_names, dfs))
if not data_sets:
logging.error('No data sets have been loaded')
raise ValueError("No data sets have been loaded")
logging.info(f"{len(data_sets){style='color: #990000'}[}]{style='color: #990000'} data sets have been loaded.")Download and Unzip helper
import urllib.request
from zipfile import ZipFile
import os
def extract(url: str, dest: str, target: str = '') -> None:
"""
Retrieve online data sources from flat or zipped CSV.
Places data in data/raw subdirectory (first creating, as needed).
For zip file, automatically unzip target file.
Args:
url (str): URL path to the source file to be downloaded
dest (str): File for the destination file to land
target (str, optional): Name of file to extract (in case of zipfile). Defaults to ''.
"""
# set-up expected directory structure, if not exists
if not os.path.exists('data'):
os.mkdir('data')
if not os.path.exists('data/raw'):
os.mkdir('data/raw')
# download file to desired location
dest_path = os.path.join('data', 'raw', dest)
urllib.request.urlretrieve(url, dest_path)
# unzip and clean-up (remove zip) if needed
if target != '':
with ZipFile(dest_path, 'r') as zip_obj:
zip_obj.extract(target, path = "data//raw")
os.remove(dest_path)
from helpers.extract import extract
url_cps_suppl = 'https://www2.census.gov/programs-surveys/cps/datasets/2020/supp/nov20pub.csv'
extract(url_cps_suppl, 'cps_suppl.csv')Extract a section of text
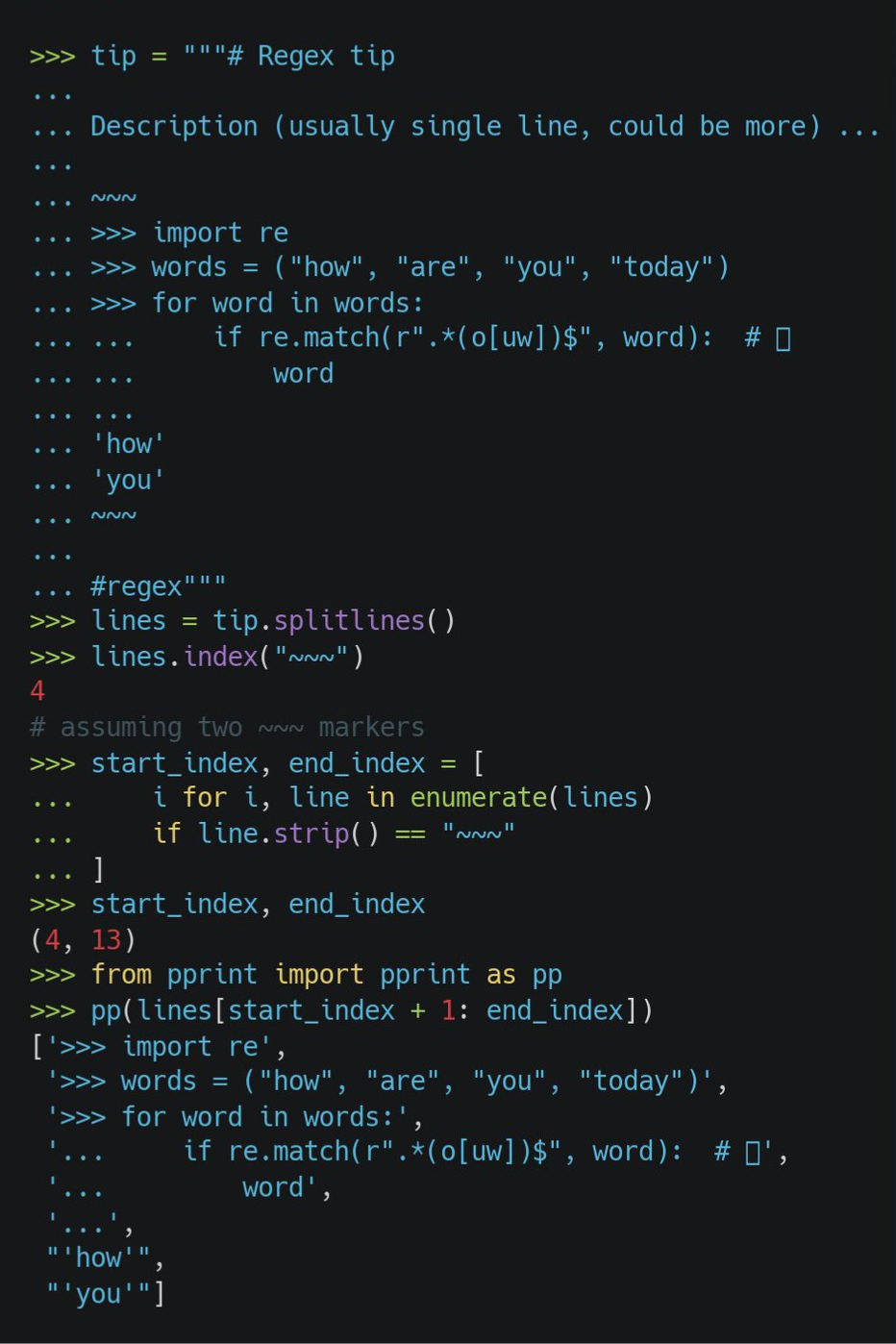
- Desired section of text is split between 2 “~~~” strings
- Process
- String is split into lines
- Find the start and stop indexes for the 2 “~~~”
- Extract lines between to the two indexes
Shell Start-Up
A start-up script automatically imports libraries, definines functions, or sets variables, etc. when the python interpreter is started.
- Every time you start a shell, the first thing you usually do is import a bunch of stuff, or frenetically press the top arrow key to recall something from your history. This is aggravated by the fact Python has very limited support for reloading changed modules in a shell, so restarting it is a common thing.
Steps
- Choose a location for your script which can be anywhere
- Create python script at the location and fill in whatever you want to happen when you start a python REPL
- Name can be pythonstartup.py or whatever
- Set the
PYTHONSTARTUPenvironment variable to the path of the fileWindows:
CMD
set PYTHONSTARTUP=C:\path\to\pythonstartup.pyPowershell
Set-Item -Name PYTHONSTARTUP -Value C:\path\to\pythonstartup.py
Mac/Linux:
export PYTHONSTARTUP=/path/to/pythonstartup.py
Example: From Happiness is a good PYTHONSTARTUP script
import atexit # First, a lot of imports. I don't use all of them all the time, # but I like to have them available. import csv import datetime as dt import hashlib import json import math import os import random import re import shelve import subprocess import sys import tempfile from collections import * from functools import partial from inspect import getmembers, ismethod, stack from io import open from itertools import * from math import * from pprint import pprint as pretty_print from types import FunctionType from uuid import uuid4 from unittest.mock import patch, Mock, MagicMock from datetime import datetime, date, timedelta import pip # Set ipython prompt to ">>> " for easier copying try: from IPython import get_ipython get_ipython().run_line_magic("doctest_mode", "") get_ipython().run_line_magic("load_ext", "ipython_autoimport") except: pass try: import asyncio # for easier pasting from typing import * from dataclasses import dataclass, field except ImportError: pass # Mostly to parse strings to dates try: import pendulum except ImportError: pass # I think you know why try: import requests except ImportError: pass # If I'm in a regular Python shell, at least activate tab completion try: import readline readline.parse_and_bind("tab: complete") except ImportError: pass try: # if rich is installed, set the repr() to be pretty printted from rich import pretty pretty.install() except ImportError: pass # I wish Python had a Path literal but I can get pretty close with this: # Tiis let me to p/"path/to/file" to get a Path object from pathlib import Path try: class PathLiteral: def __truediv__(self, other): try: return Path(other.format(**stack()[1][0].f_globals)) except KeyError as e: raise NameError("name {e} is not defined".format(e=e)) def __call__(self, string): return self / string p = PathLiteral() except ImportError: pass # Force jupyter to print any lone variable, not just the last one in a cell try: from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" except ImportError: pass # Check if I'm in a venv VENV = os.environ.get("VIRTUAL_ENV") # Make sure I always have a temp folder ready to go TEMP_DIR = Path(tempfile.gettempdir()) / "pythontemp" try: os.makedirs(TEMP_DIR) except Exception as e: pass # I'm lazy def now(): return datetime.now() def today(): return date.today() # Since restarting a shell is common, I like to have a way to persit # calculations between sessions. This is a simple way to do it. # I can do store.foo = 'bar' and get store.foo in the next session. class Store(object): def __init__(self, filename): object.__setattr__(self, "DICT", shelve.DbfilenameShelf(filename)) # cleaning the dict on the way out atexit.register(self._clean) def __getattribute__(self, name): if name not in ("DICT", "_clean"): try: return self.DICT[name] except: return None return object.__getattribute__(self, name) def __setattr__(self, name, value): if name in ("DICT", "_clean"): raise ValueError("'%s' is a reserved name for this store" % name) self.DICT[name] = value def _clean(self): self.DICT.sync() self.DICT.close() python_version = "py%s" % sys.version_info.major try: store = Store(os.path.join(TEMP_DIR, "store.%s.db") % python_version) except: # This could be solved using diskcache but I never took the time # to do it. print( "\n/!\ A session using this store already exist." ) # Shorcurt to pip install packages without leaving the shell def pip_install(*packages): """ Install packages directly in the shell """ for name in packages: cmd = ["install", name] if not hasattr(sys, "real_prefix"): raise ValueError("Not in a virtualenv") pip.main(cmd) def is_public_attribute(obj, name, methods=()): return not name.startswith("_") and name not in methods and hasattr(obj, name) # if rich is not installed def attributes(obj): members = getmembers(type(obj)) methods = {name for name, val in members if callable(val)} is_allowed = partial(is_public_attribute, methods=methods) return {name: getattr(obj, name) for name in dir(obj) if is_allowed(obj, name)} STDLIB_COLLECTIONS = ( str, bytes, int, float, complex, memoryview, dict, tuple, set, bool, bytearray, frozenset, slice, deque, defaultdict, OrderedDict, Counter, ) try: # rich a great pretty printer, but if it's not there, # I have a decent fallback from rich.pretty import print as pprint except ImportError: def pprint(obj): if isinstance(obj, STDLIB_COLLECTIONS): pretty_print(obj) else: try: name = "class " + obj.__name__ except AttributeError: name = obj.__class__.__name__ + "()" class_name = obj.__class__.__name__ print(name + ":") attrs = attributes(obj) if not attrs: print(" <No attributes>") for name, val in attributes(obj).items(): print(" ", name, "=", val) # pp/obj is a shortcut to pprint(obj), it work as a postfix operator as # well, which in the shell is handy class Printer(float): def __call__(self, *args, **kwargs): pprint(*args, **kwargs) def __truediv__(self, other): pprint(other) def __rtruediv__(self, other): pprint(other) def __repr__(self): return repr(pprint) pp = Printer() pp.__doc__ = pprint.__doc__ # Same as the printer, but for turning something into a list with l/obj class ToList(list): def __truediv__(self, other): return list(other) def __rtruediv__(self, other): return list(other) def __call__(self, *args, **kwargs): return list(*args, **kwargs) l = ToList() # Those alias means JSON is now valid Python syntax that you can copy/paste null = None true = True false = False- Also has a class for creating fake data. See article for the code.