General
Misc
- Packages
- CRAN Task View
- {Rcope} - Provides flexible, alternative IV-free methods using copulas to handle endogeneity in regressors
- Implements the two-stage copula endogeneity correction (2sCOPE) method to fit models with continuous endogenous regressors and both continuous and discrete exogenous regressors
- Papers
- Numerical validation as a critical aspect in bringing R to the Clinical Research
- Slides that show various discrepancies between R output and programs like SAS and SPSS and solutions.
- Procedure for adopting packages into core analysis procedures (i.e. popularity, documentation, author activity, etc.)
- Numerical validation as a critical aspect in bringing R to the Clinical Research
- Notes from
- ATE or LATE?
- If proposed policy is to give everyone the treatment, then ATE
- If proposed policy only affects a subset, then maybe LATE is more appropriate
Terms
- Disturbances - The error term in an econometric models (aka residuals in a regression)
- Economic Shock - Refers to any change to fundamental macroeconomic variables or relationships that has a substantial effect on macroeconomic outcomes and measures of economic performance,
- Examples: unemployment, consumption, and inflation.
- Endogenous Variable - Variables that are correlated with the population error term. “Determined inside the model”.
- An observed endogenous variable is affected by other variables in the system (it is roughly equivalent to a dependent variable in an experiment). It’s the variable that show differences we wish to explain.
- When the causality between X and Y goes both directions, both are endogenous.
- Also see Glossary: DS terms
- Exogenous Variable - Variables that are NOT correlated with the population error term. “Determined outside the model”
- An observed exogenous variable is not controlled by other variables in the system (it is roughly equivalent to an independent variable in an experiment). It’s the variable used to explain the differences in the endogenous variable.
- Limited Dependent Variable (LDV) - A variable whose range of possible values is “restricted in some important way.”
- i.e. censoring, truncating, discrete
- e.g. Probabilities, or is constrained to be positive, as in the case of wages or hours worked
Standard Errors
Misc
- Packages
- {ceser}
- {clubSandwich}
- {conleyreg} - Allows for serial correlation over all (or a specified number of) time periods, as well as spatial correlation among units that fall within a certain distance of each other.; Alternative to using a geospatial variable (e.g. region, country) as a fixed effect.
- Supports ols, logit, probit, and poisson models
- Conely SEs assume that the degree of correlation in errors decays as the distance between two locations increases.
- Use a distance-based correction to account for spatial dependence. The errors of observations close to each other are assumed to be correlated, but this correlation weakens as the geographical distance between them increases. This allows for a more continuous and flexible adjustment to the error structure across space.
- {fwildclusterboot}
- {hcinfer} - HC0 through HC5m estimators implemented plus HCbeta which was developed by the authors of the package
- {sandwich}
- {SpatialInference::conely_SE} - Computes conely SEs for spatially correlated residuals
- Includes more kernel options than {conelyreg} (Besides the Barlett, the Epanechnikov kernel is also recommended)
- Vignette shows how to estimate the distance cutoff using a covariogram from {gstat}
- If you use clustered standard errors for multiple group variables, the robust standard errors also cover interactions involving these variables and variables nested within the group variables (Thread, Paper)
- “So if you are clustering by country and year, then this will also catch the cluster-year interaction. Similarly, in the hierarchical setting where you’ve got students nested in classes nested in schools, clustering by school will still catch the classroom-level dependence.”
Heteroskedastic Robust Standard Errors
- Discussed by Zeileis in his econometrics book and in White’s paper
- Types
- H0 is the original
- H1 follows H0 but corrects for degrees of freedom. Only unbiased when experiment is balanced.
Balance example: data for vehicle accidents has state and year variables. Balanced is each state has accidents data for each year
Example
lmtest::coeftest(model, vcov. = vcovHC, type = "HC1") # vcovHC is part of the sandwich package
- H2 is unbiased when errors are homeoskedastic
- i.e. Don’t just blindly use without checking for homeoskedastity
- H3 is derived from jackknife procedure
- Also HC4, HC5, and modified HC4m
- HC4 corrects for high-leverage points
- Cribari-Neto F., Da Silva W.B. (2011). “A New Heteroskedasticity-Consistent Covariance Matrix Estimator for the Linear Regression Model.” Advances in Statistical Analysis, 95(2), 129–146
- Guidelines
- tl;dr - Use HC3 (default method for
vcovHC) for small to moderately sized data sets and jackknife,vcovBS(..., type = "jackknife")orvcovJK, for large datasets (HC3 computation will fail). - If sample size is small and heteroskedasticity present, then H0, H1, or H2 shouldn’t be used. H3 isn’t quite as reliable as regular OLS standard errors.
- If heteroskedasticity present, then H3 is superior, otherwise H2 better than H1 which is better than H0
- No real guidance on HC4, HC5, and modified HC4m. See paper (above)
- tl;dr - Use HC3 (default method for
Heteroskedastic and Autocorrelation (HAC) Consistent
- Discussed in Hanck book
- Similar as for heteroskedasticity, autocorrelation invalidates the usual standard error formulas as well as heteroskedasticity-robust standard errors since these are derived under the assumption that there is no autocorrelation.
- R2 and F test not affected (Wald test preferred when heterskadasticity and autocorrelation present)
- Not sure where I got this. Wasn’t from the Hanck book
- Newey-West is suboptimal; the QS kernel is optimal
Clustered Standard Errors
- Belong to HAC type of standard errors. They allow for heteroskedasticity and autocorrelated errors within an entity but not correlation across entities.
- From https://datascience.blog.wzb.eu/2021/05/18/clustered-standard-errors-with-r/
- In ordinary least squares (OLS) regression, we assume that the regression model errors are independent. This is not the case here: Each subject may be surveyed several times so within each subject’s repeated measures, the errors will be correlated. Although that is not a problem for our regression estimates (they are still unbiased [Roberts 2013], it is a problem for for the precision of our estimates — the precision will typically be overestimated, i.e. the standard errors (SEs) will be lower than they should be [Cameron and Miller 2013]. The intuition behind this regarding our example is that within our clusters we usually have lower variance since the answers come from the same subject and are correlated. This lowers our estimates’ SEs.
vcovCL()will give STATA clustered standard errors.vcovCL()may be biased downwards- Circumstances where it may be biased downwards (i.e. CIs too small)
- Imprecise calculations arise when there is a low number of clusters (e.g. classrooms, schools)
- less than 50 clusters
- Multi-way (i.e. more than 1 fixed effect in panel data)
- If the cluster sizes are wildly different.
- If the intra-cluster correlations varies across clusters.
- Imprecise calculations arise when there is a low number of clusters (e.g. classrooms, schools)
- Solutions:
vcovJK-Not downward biased and yield better coverage rates for confidence intervals compared to other “robust” covariance estimates- Based on leave-one-out estimates of the coefficients/parameters of a model. This means that the model is reestimated after dropping each observational unit once, i.e., each individual observation in independent observations or each cluster in dependent data
- HC3 seems to be an estimate of the Jackknife. To obtain HC3 covariances that exactly match the jackknife covariances, the jackknife has to be centered with the full-sample estimates (arg center = “estimate”) and the right finite-sample adjustment (?) has to be selected for the HC3.
- Satterthwaite corrected cluster robust sandwich estimator (?)
- Wild Cluster Bootstrap {clubSandwich} {fwildclusterboot}
- Computationally expensive
- fwildclusterboot is VERY fast though
- {modernBoot::wild_boot_lm} - Performs wild bootstrap resampling for linear regression models to handle heteroscedasticity. Supports Rademacher and Mammen weight schemes
- Computationally expensive
- For small cluster sizes, choose wild cluster bootstrap over Satterthwaite corrected cluster robust sandwich estimator when: (article)
- Extreme treatment proportions (e.g. 80% obs treated, 10% control)
- Extreme differences in cluster sizes (i.e. extreme imbalance)
- Cluster-estimated {ceser}
- More conservative than the CRSE method,
sandwich::vcovCL - Less sensitive to the number of clusters and to the heterogeneity of the clusters, which can be a problem for both CRSE and bootstrap methods
- Also has heteroskedacity corrections: HC0, HC1, HC2, HC3, or HC4
- More conservative than the CRSE method,
- Circumstances where it may be biased downwards (i.e. CIs too small)
Instrumental Variables (IV)
Model
\[\begin{align} Y_i &= \beta_0 + \beta_1 X_i + \beta_2 W_i + u_i \\ X_i &= \pi_0 + \pi_1 Z_i + \pi_2 W_i + v_i \quad \text{where}\; i = 1, \ldots, n \end{align}\]
- \(u\) and \(v\) are error terms, \(X\) is an endogenous variable, \(Z\) is an exogenous, instrumental variable, \(W\) is another predictor of the outcome variable except it’s exogenous.
Misc
- Packages
- {cragg} - Implements Cragg-Donald and Stock and Yogo tests for weak instruments in R
- {endogeneity} - Various recursive two-stage models to address the endogeneity issue of treatment variables in observational study or mediators in experiments.
- Supposedly it handles the absence of a good intrument by “model-based identification, which makes parametric assumption about the endogeneity structure.” But this just looks like a two-stage IV model except they aren’t calling Z an IV. ¯\_(ツ)_/¯
- {ivreg} - Instrumental variable estimation for linear models by two-stage least-squares (2SLS) regression or by robust-regression via M-estimation (2SM) or MM-estimation (2SMM).
- {iv.sensemakr} - Sensitivity Analysis Tools for Instrumental Variable Estimates
- {RPIV} - Residual Prediction Test for Well-Specification of Instrumental Variable Models
- {senseR} - Provides statistical diagnostics to evaluate whether proxy indicators reliably represent an unobservable target construct
- Components:
- Spearman Rank Correlation (montonicity)
- Proportion of variance explained (R-squared) (information)
- Sensitivity of regression coefficients across subsamples (stability)
- Similarity of standardized distributions via Kolmogorov–Smirnov test (distribution alignment)
- Penalization for strong nonlinearity indicating potential proxy distortion (bias risk)
- Guidelines: The overall score is the average of the five components (range: 0 to 1)
- Suitable proxy: score >= 0.70
- Conditionally suitable: 0.40 <= score < 0.70
- Not suitable proxy: score < 0.40
- Components:
- Resources
- Video series covering all the concepts
- If X and u are correlated (endogenity) then OLS is inconsistent. So IV modeling uses the Z to isolate the part of X that isn’t correlated with u. Potential causes for this correlation between X and u are:
- Unobservable omitted variable(s)
- Using an IV allows us to use part of X than isn’t associated with the omitted variable (i.e. confounder) but is still associated with Y
- Measurement error
- simultaneous causality
- Unobservable omitted variable(s)
- Packages
Terms
- Endogenous Variable - Variables that are correlated with u, the population error term. “Determined inside the model”.
- When the causality between X and Y goes both directions, both are endogenous.
- Exogenous Variable - Variables that are NOT correlated with u. “Determined outside the model”
- Endogenous Variable - Variables that are correlated with u, the population error term. “Determined inside the model”.
Conditions for Valid Instruments
- Instrument Relevance: \(Corr (X , Z) \neq 0\) (Predictive of X)
- Checks (1st stage)
- Instrument should have a significant p-val
- F-Test stat > 10; t-test stat > 3.16 (rules of thumb)
- Checks (1st stage)
- Instrument Exogeneity: \(Corr (Z, u) = 0\), \(Corr(Z, v) = 0\)
- Check: “balancing test (t-test); results should be insignificant” (?)
- Would’ve thought you could do some kind of check on the residuals
- Check: “balancing test (t-test); results should be insignificant” (?)
- Exclusion Restriction: No impact on the dependent variable directly. It only impacts the dependent variable through its impact on the treatment variable
- Instrument Relevance: \(Corr (X , Z) \neq 0\) (Predictive of X)
Diagnostics
- Wu–Hausman Test - Test of endogeneity i.e. where you need IV modeling at all.
- If all of the regressors are exogenous, then both the OLS and 2SLS estimators are consistent, and the OLS estimator is more efficient, but if one or more regressors are endogenous, then the OLS estimator is inconsistent.
- A large test statistic and small p-value suggests that the OLS estimator is inconsistent and the 2SLS estimator is therefore to be preferred.
- Sargan Test - Test of overidentification. An overspecified model has more instrumental variables than coefficients to estimate, it’s possible that the instrumental variables provide conflicting information about the values of the coefficients. - A large test statistic and small p-value suggests that the model is misspecified. - Inapplicable to a just-identified regression equation, with an equal number of instrumental variables and coefficients
- Wu–Hausman Test - Test of endogeneity i.e. where you need IV modeling at all.
Good Instruments
- May not have a strong causal relationship with x and therefore overlooked in the subject matter literature. Domain “field work” into the data generating process can help identify new instruments.
- The effect of the instrument on the population is somewhat random (Instruments perform a quasi-randomization)
- e.g. A policy that may or may not have an effect on a population should make it exogenous. Something outside the control of the individual that influences her likelihood of participating in a program, but is otherwise not associated with her characteristics.
- Examples
- Outcome: log(wage), predictor: woman’s education, instrument: mother’s education
- This might not follow condition #2. If the daughter’s “ability” is an omitted variable which is in the error term (u), and “mother’s education” are correlated, then #2 is violated.
- Outcome: #_of_kids (fertility), predictor: years_of_education, instrument: pre/post government policy that increases mandatory years of education
- Outcome: log(wage), predictor: woman’s education, instrument: mother’s education
Steps
Regress X on Z where the π-terms and Z are the parts uncorrelated with u.
Drop the error term, v, which is the part of X that’s correlated with u
Regress the Y on the modified X to estimate the βs
\[\begin{align} Y_i &= \beta_0 + \beta_1 \tilde X_i + \beta_2 W_i + u_i \\ \tilde X_i &= \pi_0 + \pi_1 Z_i + \pi_2 W_i \end{align}\]
When OLS is used to calculate the modified X, this process is called Two-Stage Least Squares (2SLS)
Effects (Also see LATE in Effects, Calculating LATE and Compliance in Experiments, Analysis)
- Using an instrumental variable allows us to identify the impact of the treatment on compliers. This is known as the local average treatment effect or LATE.
- The LATE is the impact that the treatment has on the people that comply with the instrument.
- \(\hat\beta_{IV}\) only captures the causal effect of X on Y for compliers whose X vary by Z
- \(\hat\beta_{IV}\) is a weighted average of the treatment effect for compliers, with more weight given to more compliant groups
- Example: it is the impact of additional years of schooling (treatment) on fertility of women (outcome) affected by the school reform policy (instrument) only because they live in municipalities that had implemented it.
- **Requires an extra restriction on the instrumental variable**
- Monotonocity (no defiers): There is no one in the sample that does not receive the treatment because they received the instrument. This is usually a reasonable assumption to make but it can only be made based on intuition.
- (Mathematically) it’s the number of people assigned and received treatment is always greater than or equal to the number of people not assigned yet received treatment.
- Monotonocity (no defiers): There is no one in the sample that does not receive the treatment because they received the instrument. This is usually a reasonable assumption to make but it can only be made based on intuition.
- LATE = ATE if any of the following is true
- No heterogeneity in treatment effects
- \(\beta_{1,i} = \beta_1 \quad \forall i\)
- No heterogeneity in first-stage responses to the instrument Z
- \(\pi_{1,i} = \pi_1 \quad \forall i\)
- No correlation between response to instrument Z and response to treatment X
- \(\text{Cov}(\beta_{1,i} , \pi_{1,i}) = 0\)
- No heterogeneity in treatment effects
- The LATE is the impact that the treatment has on the people that comply with the instrument.
- Also see Complier Average Causal Effects (CACE) https://www.rdatagen.net/post/cace-explored/
- Using an instrumental variable allows us to identify the impact of the treatment on compliers. This is known as the local average treatment effect or LATE.
Caveats
- The IV model is not an unbiased estimator, and in small samples its bias may be substantial
- A weak correlation between the instrument and endogenous variable may provide misleading inferences about parameter estimates and standard errors.
- \(\beta_1\), the average treatment effect, assumes that all subgroups experience the roughly the same effect. If there are different subgroups of the population that are substantially affected differently, then a “weighted average of subsets” approach can be used.
- Example: Y = lung cancer, X = cigarettes, Z = cigarette tax. Perhaps people whose smoking behavior is sensitive to a tax may have a different β1 than other people
Difference-in-Differences Estimator
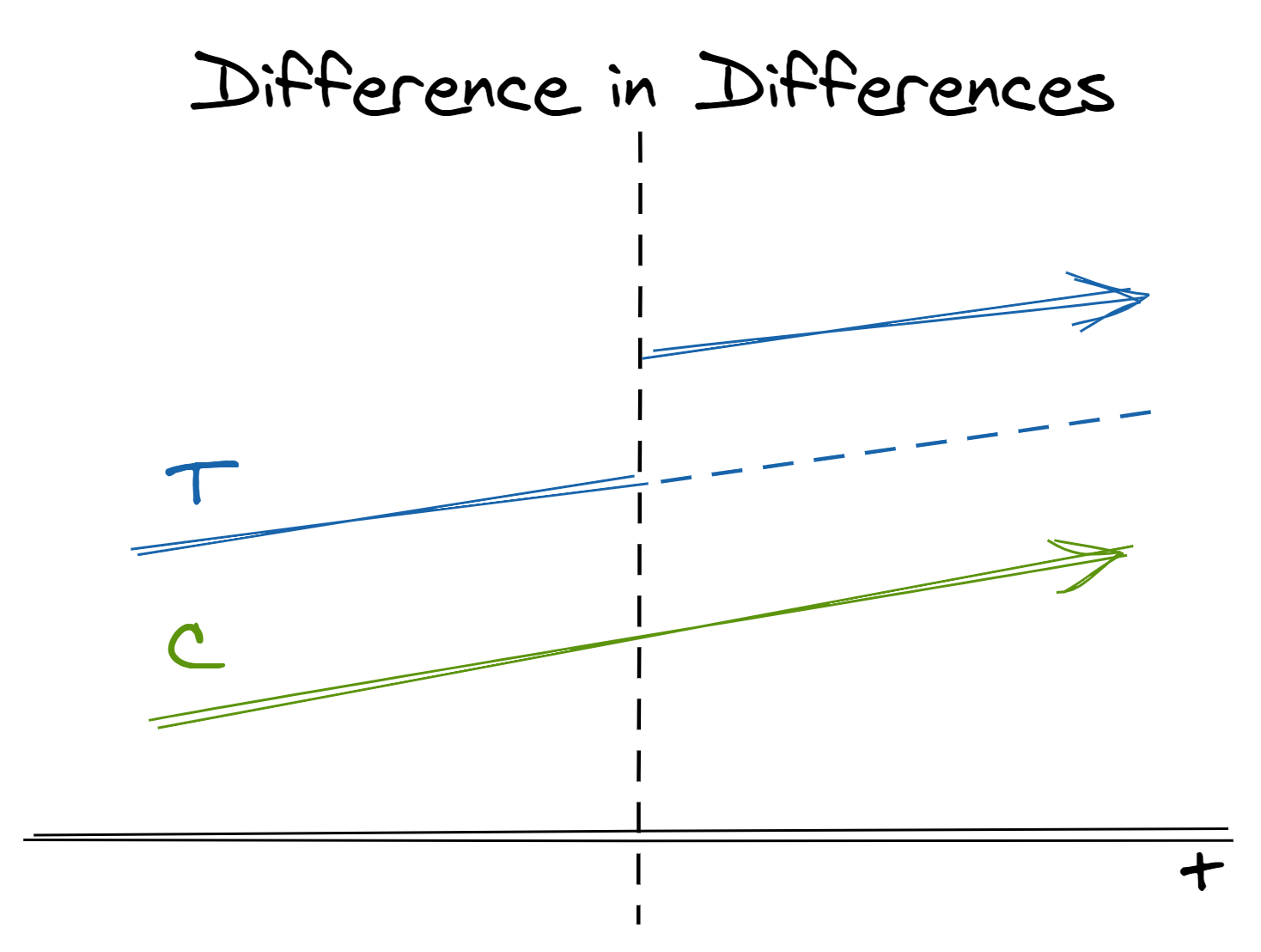
Without random samples as data, the selection into one of the two groups is by choice, thus introducing a selection bias
Some treatments we wish to apply cannot be applied at the individual level but necessarily effect entire groups. Instead of comparing treatment and control groups within the same population at the same time, we can compare the relative change across treatment and control populations across time.
When you have group-level treatments or data available, use random variation across populations to compare their overall trends over time
Packages
- {catviz} - Visualizing Causal Assignment Trees for Callaway and Sant’Anna difference-in-differences (CSDiD) and doubly robust difference-in-difference-differences (DR-DDD) Designs
- {did} - Computes ATE for DiD and allows for:
- More than two time periods
- Variation in treatment timing (i.e., units can become treated at different points in time)
- Treatment effect heterogeneity (i.e, the effect of participating in the treatment can vary across units and exhibit potentially complex dynamics, selection into treatment, or time effects)
- The parallel trends assumption holds only after conditioning on covariates
- Group-time average treatment effects are the average treatment effect for a particular group (group is defined by treatment timing) in a particular time period.
- These parameters are a natural generalization of the average treatment effect on the treated (ATT) which is identified in the textbook case with two periods and two groups to the case with multiple periods.
- {didhetero} - Tools to construct doubly robust uniform confidence bands (UCB) for the group-time conditional average treatment effect (CATT) function given a pre-treatment covariate of interest in the staggered difference-in-differences setup of Callaway and Sant’Anna (2021).
- {diff-diff} - Provides sklearn-like DiD estimators with statsmodels-style output for econometric analysis.
- Multiple Estimators: Basic DiD, Two-Way Fixed Effects, Multi-Period Event Studies, Synthetic DiD, and Callaway-Sant’Anna for staggered adoption
- Modern Inference: Robust standard errors, cluster-robust SEs, and wild cluster bootstrap
- Assumption Testing: Parallel trends tests, placebo tests, and comprehensive diagnostics
- Sensitivity Analysis: Honest DiD (Rambachan & Roth 2023) for robust inference under parallel trends violations
- Publication-Ready Output: Summary tables and event study plots
- {fastdid} - Implements the Difference-in-Differences (DiD) estimators in Callaway and Sant’Anna’s (2021)
- fast, reducing the computation time with millions of units from hours to seconds,
- flexible, allowing extensions such as time-varying covariates and multiple events.
- {fdid} - Implements the factorial difference-in-differences (FDID) framework for panel data settings where all units are exposed to a universal event but vary in a baseline factor G.
- Provides support for various estimators; supports robust, bootstrap, and jackknife variance; returns dynamic, pre/event/post aggregates and raw mean
- {moderndid} - Modern DiD estimators with diagnostic tools and sensitivity analysis.
- Multiple time periods and variation in treatment timing with group-time effects and flexible aggregation schemes
- Doubly robust difference-in-differences estimators for panel and repeated cross-section data with improved efficiency and robustness
- Sensitivity analysis for violations of parallel trends with multiple restriction types
- Continuous treatment DiD for dose-response relationships and non-binary treatments
- More methods to be implemented
- {pcdid} - Implements factor-augmented difference-in-differences (DID) estimation.
- Useful in situations where the user suspects that trends may be unparallel and/or stochastic among control and treated units.
- The estimation method is regression-based and can be considered as an extension of conventional DID regressions
- {ptetools} - Compartmentalizes the steps needed to implement estimators of group-time average treatment effects (and their aggregations)
- {staggered} (Paper) - Efficient Estimation Under Staggered Treatment Timing
- {staggR} - Fit Difference-in-Differences Models with Staggered Interventions
Papers
Manually
df_did <- df %>% mutate(after = year >= 2014) %>% mutate(treatafter = after*treat) reg <- lm(murder ~ treat + treatafter + after, data = DiD)Basically a standard lm with an interaction between the treatment indicator and time period indicator demarking before/after treatment.
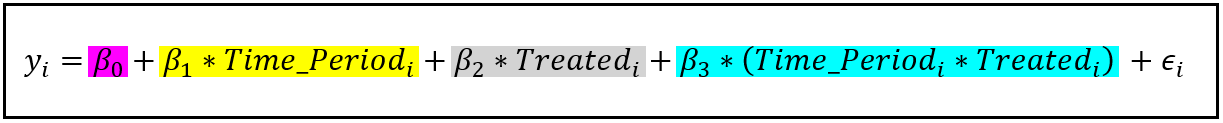
Predictions
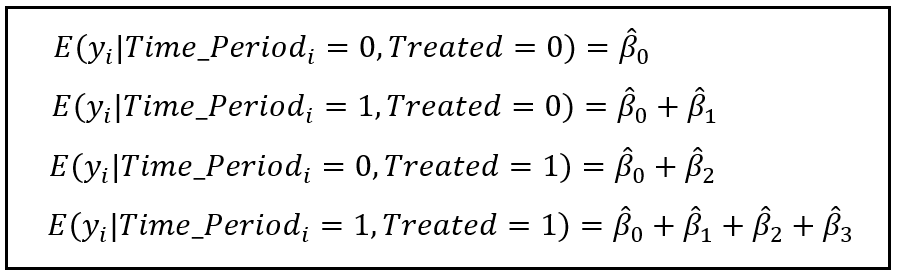
- The DiD effect works out to be the interaction effect, \(\beta_3\) = (2nd - 1st eq) - (4th - 3rd eq)
Example
- We want to estimate the effect of a store remodel on visits.
- A remodel affects all potential customers, so this “treatment” cannot be applied at the individual level; in theory, it could be randomized to individual stores, but we do not have the budget for or interest in randomly remodel many stores before there is evidence of a positive effect.
Approach
- In two separate populations, one receives the treatment and one does not. We believe but-for the treatment the two populations would have similar trends in outcome
- We can estimate the treatment effect by taking the difference between the (post-treatment difference between populations)(solid lines after treatment) and (the pre-treatment difference between populations) (solid lines before treatment)
- DiD’s control (dotted line) is an extrapolation of the treatment case that must be parallel to the mean post-treatment outcome (green line post-treatment) of the non-treated case
- The effect is the difference between DiD’s control (blue dotted line) and the post-treatment outcome (blue line post-treatment) of the treated case.
- In effect, this is the same as extrapolating the counterfactual for the treated population in the post-treatment period if it had not received treatment (the dashed line in the image above)
- Technically, this is implemented as a fixed-effects regression model
Key Assumptions
- The decision to treat the treatment group was not influenced by the outcome (no anticipation to treat)
- e.g. poverty rate spikes and community expects a policy to be enacted soon, so it acts (spends money, etc.) in anticipation of that help coming
- If not for the treatment, the two groups being compared would have parallel trends in the outcome. Note that groups are allowed to have different levels but must have similar trends over time
- Pretesting parallel trends assumption:
- Options if this assumption is violated
- Use pre-treatment variables to filter data to create similar groups (Treatment/Control) so they are more likely to have similar trends (pre-cursor to Synthetic Controls method)
- Estimate the propensity score based on observed covariates; compute the fitted value
- Run a weighted DiD model
- Extrapolate the difference in pre-treatment trends to post-treatment (paper) (Also see {HonestDiD})
- Use a “differential trends” method (explainer, says code available on request)
- includes each post-intervention time period as a dummy variable in your model, and average these to obtain an average treatment effect
- Combination of DiD and IV (paper)
- Use pre-treatment variables to filter data to create similar groups (Treatment/Control) so they are more likely to have similar trends (pre-cursor to Synthetic Controls method)
- There is no spill-over effect such that treating the treatment group has an effect on the control group
- The decision to treat the treatment group was not influenced by the outcome (no anticipation to treat)
Application
- We can estimate the effect of a store remodel on visits by comparing store traffic before and after the remodel with traffic at a store that did not remodel.
- Note how sensitive this method is to our assumptions:
- If the remodel is an expansion and caused by a foreseen increase in traffic, our first assumption is violated and our effect will be overestimated
- If the control we chose is another nearby store in the same town, we could experience spillover effects where more people who would have otherwise gone to the control store decide to go to the treatment store instead. This again would overestimate the effect
- Another counter-example that violates the assumption would be measuring the effect of placing a certain product brand near a store’s check-out on sales and using sales of a different brand of the same product as the control. Why? Since these products are substitutes, the product placement of the treatment group could “spillover” to negatively effect sales of the control
Related Methods
- Variants exist that relax different assumptions. For example, we may consider cases in which different units receive the treatment at different times, different units have different (heterogenous) treatment effects, the parallel trend assumption only holds after conditioning on covariates, and many more scenarios
- Synthetic control methods can be thought of as an extension of difference-in-differences where the control is a weighted average of a number of different possible controls
- Bayesian structural time-series methods relax the “parallel trends” asumptions of difference-in-differences by modeling the relationship between time series (including trend and seasonal components)
Abadie, Alberto (2005). “Semiparametric Difference-in-Differences Estimators,” Review of Economic Studies (2005) 72, 1–19
- Assumption: non-parallel outcome dynamics between treated and controls caused by observed characteristics
- Two-step strategy:
- Estimate the propensity score based on observed covariates; compute the fitted value
- Run a weighted DiD model
- The idea of using pre-treatment variables to adjust trends is a precursor to synthetic control
Strezhnev (2018) extends this approach to incorporate pre-treatment outcomes
Other considerations (article)
- Levels are important.
- Always look at differences in levels between treatment and control, and not just trends. If there are large differences, than think about why they are so different.
- Could these differences affect future trends in our outcome of differences?
- Functional forms matter.
- When comparing our treatment and control trends, do we think that they evolve similarly in terms of absolute or relative terms? Do we want to use levels or logs?
- Pre-treatment parallel tests are problematic.
- Only because we reject an unequal parallel trend does not mean that we confirmed its validity, and often, these rejection tests are underpowered.
- Levels are important.
Stepped Design (Athey)
- Assumptions
- Adoption date is conditional on the potential outcomes and possibly pretreatment variables. Guaranteed by design
- You can relax (troublesome) random assignment assumption by requiring only that the adoption date is completely random within subpopulations with the same values for the pre-treatment variables (e.g. units are clusters of individuals like states)
- Potential outcomes which rules out the presence of certain treatment effects
- No anticipation - outcome at present is not affected by anticipation of a future treatment date.
- Invariance to history - duration of treatment prior to a given period doesn’t affect the outcome variable value for that period
- More plausible when units are clusters of individuals (e.g. states)
- Adoption date is conditional on the potential outcomes and possibly pretreatment variables. Guaranteed by design
- “Auxillary” Assumptions (i.e. Sometimes needed for particular analyses)
- Constant treatment effect across time
- Constant treatment effect across units
- Assumptions
Synthetic Control Method (SCM)
- Creates a synthetic control based on the pre-treatment features of the treatment unit and non-treated units. A control that’s based on comparison units (i.e. non-treatment units) often provides a better control than a control solely based on the treated unit (like in DiD). After treatment, you take the difference between this synthetic control and your treatment unit to estimate the effect of the treatment. Similar to DiD, except on how the control is formulated.
- Misc
- Notes from: Using Synthetic Controls: Feasibility, Data Requirements, and Methodological Aspects
- Packages
- {coresynth} - Fast and Unified Synthetic Control Methods
- Includes: Synthetic Difference-in-Differences (SDID), Generalized Synthetic Control (GSC), Matrix Completion (MC), Time-Aware Synthetic Control (TASC), and Synthetic Interventions (SI)
- {DiSCos} (Paper) - Tools for computing counterfactual quantile functions in a Distributional Synthetic Controls (DiSco) setting
- {scpi} (Paper) - Estimation and inference procedures for synthetic control methods
- Also available for Python
- Uncertainty quantification in synthetic controls with staggered treatment adoption
- {tidysynth} - A Tidy Implementation of the Synthetic Control Method
- Allow users to inspect, visualize, and tune the synthetic control more easily
- The entire preparation process for building the synthetic control can be accomplished in a single pipe
- {coresynth} - Fast and Unified Synthetic Control Methods
- Extensions
- Generalized synthetic control by Xu (2017)
- Synthetic difference-in-differences by Doudchenko and Imbens (2017)
- Penalized synthetic control of Abadie e L’Hour (2020)
- Matrix completion methods of Athey et al. (2021)
- Terms
- Donor Pool or Donors: The group of units that are untreated which are used to calculate the synthetic control
- Unit, Cell, Case: Interchangeable names for the population level you’re testing in the experiement (e.g. herd, school, store, city, state, precinct)
- Recommended Use Cases
- When events take place at the aggregated level, e.g. county, state, province.
- You only have one treated unit and a few control units.
- Advantages
- Better apples to apples comparison that DiD since the control should be a better estimate.
- The weights (which sum to 1) from the calculation of the synthetic control add to the interpretability of the method by giving us information about the “importance” of each non-treated unit in the formulation of the synthetic control
- The donor weights are sparse due to the optimization process. Only a few donors contribute to the synthetic control.
- SCM provides transparency about how different the non-treatment units are from the treatment unit. This difference can be calculated.
- The choice of a synthetic control does not rely on the post-intervention outcomes, which makes it impossible to cherrypick the study design that may affect the conclusions.
- Choosing Units for the Donor Pool
- The risk of over-fitting may also increase with the size of the donor pool, especially when T0 (pre-treatment period) is small
- Each of the units in the donor pool have to be chosen judiciously to provide a reasonable control for the treated unit. Including in the donor pool units that are regarded by the analyst to be unsuitable controls (because of large discrepancies in the values of their observed attributes Zj or because of suspected large differences in the values of the unobserved attributes μj relative to the treated unit) is a recipe for bias.
- Donor units with similar values of the observed predictors as the treated unit should be chosen. If it’s believed that a unit has a large unobserved difference with the treated unit, it shouldn’t be included.
- As a rule of thumb, Abadie, Diamond, and Hainmueller (2010) suggest excluding units for which the prediction MSE is larger than twice the MSE of the treated unit.
- Predictors
- Predictors are often time series reported by government agencies, multilateral organizations, and private entities (e.g. GDP, crime statistics, cigarette usage, census survey micro-data
- The predictors of the outcome variable, which are used to calculate the synthetic control, are not affected by the treatment
- Data
- The larger the pre-treatment period the smaller the bias of the synthetic control estimator (assuming the synthetic control closely tracks the outcome variable during the pre-treatment period.
- A trade-off of obtaining more pre-treatment data may be that the predictors are better short term than long term.
- If this is the case, adding weights that favor more recent predictor data can help
- If the amount of pretreatment data is relatively small, then you need very good predictors of the post-treatment outcome such that residual variance will be small which will reduce the chance of overfitting.
- A trade-off of obtaining more pre-treatment data may be that the predictors are better short term than long term.
- The larger the pre-treatment period the smaller the bias of the synthetic control estimator (assuming the synthetic control closely tracks the outcome variable during the pre-treatment period.
- Robustness Checks
in-time placebo test (backdating): move the treatment date backwards in the data. If the synthetic control still closely tracks the outcome variable until the actual treatment date, then this is evidence of a reliable synthetic control
.png)
- Actual date of the treatment (i.e. German reunification) is 1990. Here the re-calculated synthetic control (dashed line) using 1980 as the treatment still tracks GDP until the actual treatment date then they split. Therefore this is evidence of a credible synthetic control.
Robustness with alternate design
- Methods
- Remove a donor from the donor pool and refit the model and see if the results hold. Repeat with each donor.
.png)
- All synthetic checks closely track pretreatment GDP and are centered around the synthetic control that used all the donors. Effect for all the synthetic checks are still negative. Evidence of robustness.
- If the exclusion of a unit from the donor pool has a large effect on results without a discernible change in pre-intervention fit, this may warrant investigating if the change in the magnitude of the estimate is caused by the effects of other interventions or by particularly large idiosyncratic shocks on the outcome of the excluded untreated unit (see Potential Issues and Solutions below)
- The choice of predictors of the outcome variable (no example given)
- Remove a donor from the donor pool and refit the model and see if the results hold. Repeat with each donor.
- Methods
Pre-Post Error Ratio
\[\lambda = \frac{\text{MSE}_{\text{post}}}{\text{MSE}_{\text{pre}}} = \frac{\frac{1}{n}\sum_{t\in \text{post}}(Y_t - \hat Y_t)^2}{\frac{1}{n}\sum_{t\in \text{pre}}(Y_t - \hat Y_t)^2}\]
Abadie, Diamond, and Hainmueller (2010) suggest to perform a randomization test is the ratio between pre-treatment MSE and post-treatment MSE.
P-Value (article)
lambdas = {} for city in cities: mse_pre = synth_predict(df, SyntheticControl(), city, treatment_year).mse mse_tot = np.mean((df[f'Synthetic [{city}]{style='color: #990000'}'] - df[city])**2) lambdas[city] = (mse_tot - mse_pre) / mse_pre print(f"p-value: {np.mean(np.fromiter(lambdas.values(), dtype='float') > lambdas[treated_city]):.4}")
- Potential Issues and Solutions
- Volatility of the outcome variable is low. Small or even large effects are difficult to detect if the outcome experiences a lot of shocks that are larger or comparable to the size of the effect.
- In units where substantial volatility is present in the outcome of interest it is advisable to remove it via filtering, in both the treatment unit as well as in the non-treatment units, before applying synthetic control techniques
- Idiosyncratic shocks in donor units
- important to eliminate from the donor pool any units that may have suffered large idiosyncratic shocks to the outcome variable during the treatment period, if it is judged that such shocks would not have affected the outcome of the treatment unit in the absence of the intervention.
- I guess the shocks indicate a substantial difference between the treatment unit and the donor
- important to eliminate from the donor pool any units that may have suffered large idiosyncratic shocks to the outcome variable during the treatment period, if it is judged that such shocks would not have affected the outcome of the treatment unit in the absence of the intervention.
- Anticipation: if any agents jumped the gun in anticipation of a policy/treatment and engaged in behavior that affects a predictor or outcome variable, the SCM results may be biased.
- If this happens, the treatment date in the dataset should be moved back to just before the agent began it’s behavior or the change in the variable occurred in reaction to agent’s behavior.
- Spillover: Donor units experience effects of the treatment even though they weren’t treated. Common if donor units are in close geographical proximity to the treatment unit.
- Donor units affected by spillover should be removed from the dataset.
- If you do include the donor, make note of the direction of the bias. Then, if the bias has a “negative” effect on the treatment effect, you can say the synthetic control estimate provides a lower bound on the magnitude of the causal effect of the treatment
- Extreme values in the treatment unit
- If the extreme values are in a predictor variable, but the synthetic control tracks the observed outcome in the pretreatment period, then all is well.
- If the synthetic control doesn’t track, then the outcome variable should be transformed to differences or growth rates
- Long time horizons: Some treatments effects take a long time to emerge.
- In these cases, you either have to just continue to wait, use surrogate outcomes, or use leading indicators
- I think “surrogate outcomes” means indirect or proxy measures of the outcome of interest
- And leading indicators isn’t referring to normal usage as a predictor but to use as the outcome.
- In these cases, you either have to just continue to wait, use surrogate outcomes, or use leading indicators
- Volatility of the outcome variable is low. Small or even large effects are difficult to detect if the outcome experiences a lot of shocks that are larger or comparable to the size of the effect.
Interrupted Time Series (ITS)
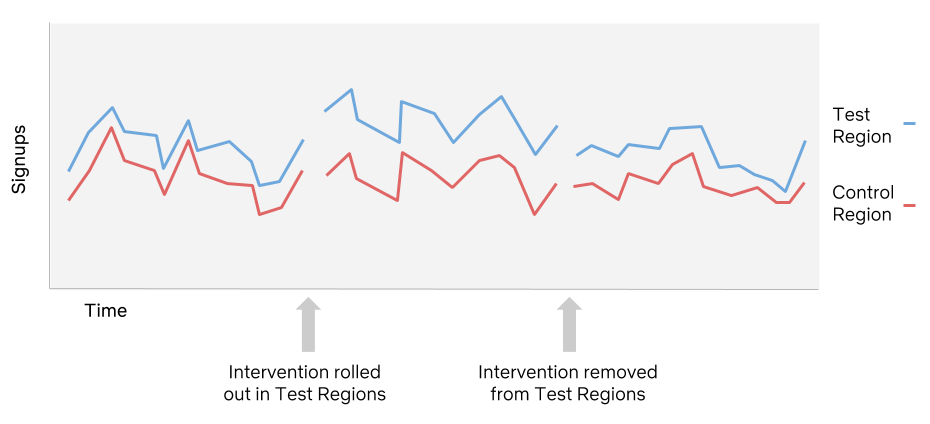
- Analysis of a single time-series data before and after the intervention
- Examine whether the outcome variable returns to the baseline after taking away the treatment condition
- Doing this multiple times increases data and adds power to the analysis (see Netflix articles in bkmks)
- Uses Segmented Regression to examine the effects of the intervention
- Each segment has its own slope and intercept, and we compare the two segmented regression models to derive the effects
- Examine whether the outcome variable returns to the baseline after taking away the treatment condition
- Misc
- Packages
- {gpss} - Gaussian Processes for Social Science
- {multipleITScontrol} - Provides tools to perform interrupted-time series through a generalised least squares (GLS) framework on linear outcomes.
- Allows for multiple interventions and a control with ARMA (autoregressive and moving-average) correction.
- Notes from: A Practitioner’s Guide To Interrupted Time Series
- Packages
- Strengths
- To control for long-term time trends in the data. ITS presents a long-term analytical framework with more extended periods, which better explain any data trends.
- To account for individual-level bias and to evaluate the outcome variable at the population level. Individual-level data may introduce bias, but not with population data. Honestly, this is both a blessing and a curse. We will elaborate more on the latter aspect in the following part.
- To evaluate both intended and unintended consequences of interventions. We can easily enlarge analysis and incorporate more outcome variables with minimum or no adaptations.
- To conduct stratified analyses of subpopulations of individuals and to derive different causal effects. This is critical. We can divide the total population into different sub-groups according to various criteria and examine how each sub-group may behave differently. Social groups are different, and grouping them together may dilute or hide critical information, as positive and negative effects mix together and cancel out (see Harper and Bruckner for examples).
- To provide clear and interpretable visual results. Visual inspections are always welcome and should be treated seriously (See my other post for more explanations).
- Limitations
- Multiple rounds of data entries. A minimum of 8 periods before and 8 after an intervention to evaluate the changes. So, we need a total of 16 data entries, which may not be possible all the time. I think Penfold and Zhang (2013) are being cautious about the number of data entries. It’s still possible to apply ITS with few rounds of data entry. Just the causal power may not as robust as the one with multiple rounds.
- Time lag. It takes some unknown time for a program to achieve intended results, which makes it difficult to pinpoint the causal effects of several events that coincide. Let’s say the transportation department in the U.S. adopt three policies within a two-year timespan to curb highway speeding. Playing God, we somehow know it would take 1 yr for Policy A to have any effect, 1.5 ys for Policy B, and 3 yrs for Policy C. In the meantime, it becomes impossible to separate the intertwined effects using ITS.
- Inference Level. It’s population-level data, so we can’t make inferences about each individual.
- Power and Sample Size Considerations
- Number of time points in each before- and after- segment
- Recommendations range from 3 time points per segment to 50 time points per segment
- Average sample size per time point
- Frequency of time points (e.g. weekly, monthly, yearly, etc.)
- Location of intervention (e.g. midway, 1/3, 2/3, etc.)
- As long as there are sufficient time points per segment and each time point is supported by a large enough sample size, there is not much difference in the study power of an early or late intervention
- Expected effect size
- Slope change: a gradual change in gradient (or slope) of trend
- Level change: an instant change in level (i.e. mean)
- Number of time points in each before- and after- segment
Regression Discontinuity Design (RDD)
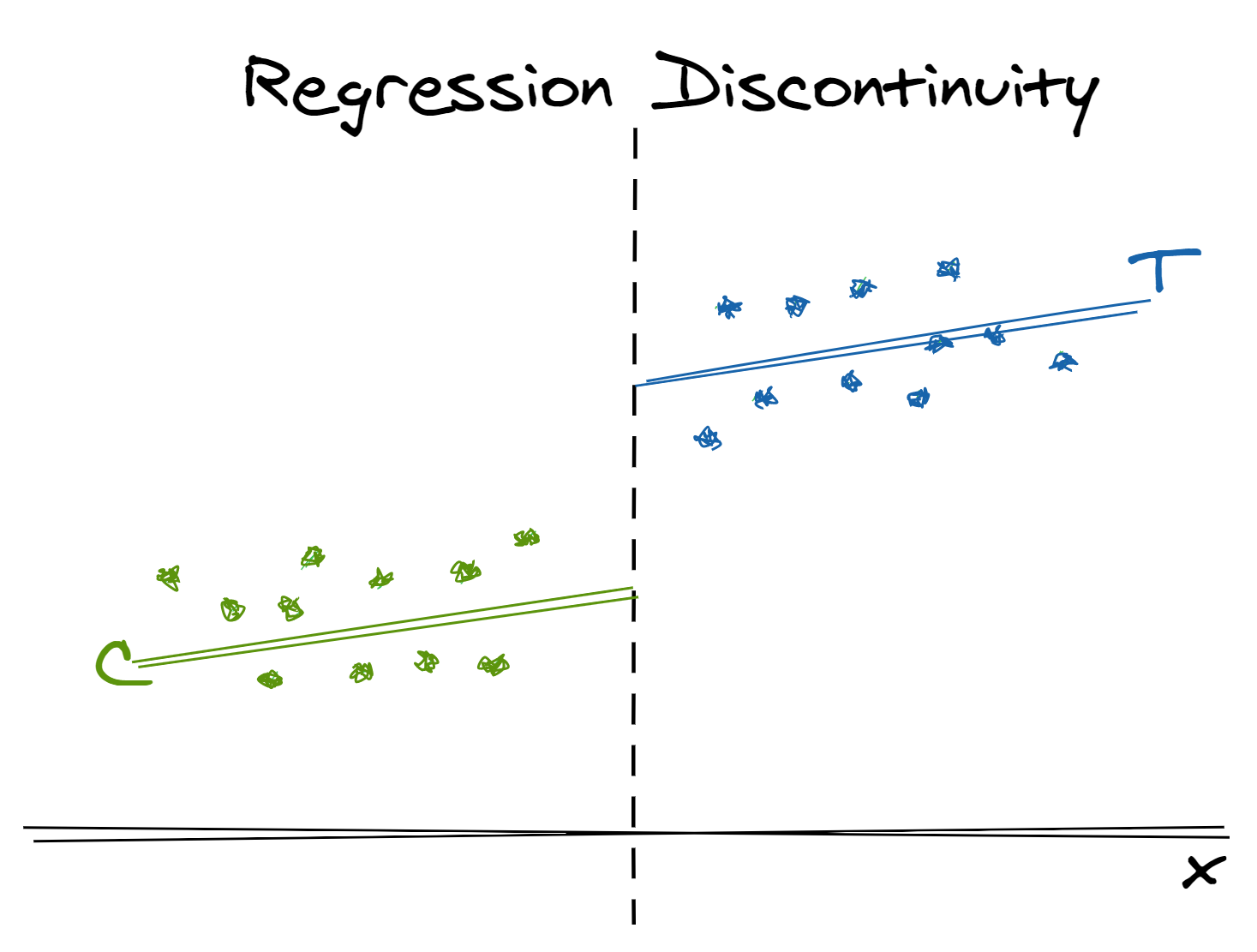
- RDDs generate asymptotically unbiased estimates of the effect of an intervention if:
- The relationship between the outcome and running variable is modeled appropriately
- Don’t use a particular curve to justify the discontinuity. Gelman prefers reasonable nonlinear curves but don’t go crazy with it so that it maximizes the effect.
- The forcing variable was not manipulated (either behaviorally or mechanically) to influence assignment to the intervention group.
- e.g. if the running variable is a test score and the threshold is a particular test score, is there evidence of some sort of cheating to where assignment of students around the threshold isn’t random? (see bullet under step 1 below)
- The relationship between the outcome and running variable is modeled appropriately
- Misc
- Packages
- {eqtesting} - Equivalence Testing Functions that provide statistically significant evidence that running variable (RV) manipulation around a cutoff is bounded beneath practically negligible levels.
- Testing for endogenous running variable (RV) manipulation around treatment cutoffs is common for using RDD, but with other tests, there’s often a misinterpretation of statistically insignificant RV manipulation as evidence of negligible RV manipulation.
- {MIRDD} - Diagnostic Tool by Multiple Imputation for Regression Discontinuity Designs
- {mrddGlobal} - Global Testing for Multivariate Regression Discontinuity Designs
- Tests whether there exist non-zero treatment effects along the boundary of the treated region
- Tests whether there exist discontinuities in the joint density of the running variables along the boundary of the treated region
- {rdd} - Provides the tools to undertake estimation in Regression Discontinuity Designs. Both sharp and fuzzy designs supported
- {rdhte} - Heterogeneous Treatment Effects in Regression Discontinuity Designs
- {gpss} - Gaussian Processes for Social Science
- {eqtesting} - Equivalence Testing Functions that provide statistically significant evidence that running variable (RV) manipulation around a cutoff is bounded beneath practically negligible levels.
- Gelman: The big mistakes seem to come from:
- Unregularized regression on the forcing variable which randomly give you wild jumpy curves that pollute the estimate of the discontinuity
- Not adjusting for other important pre-treatment predictors
- Taking statistically significant estimates and treating them as meaningful, without looking at the model that’s been fit.
- Usecases
- Lee study of the incumbency effect
- We want to know if a party holding a House seat gives that party an advantage in the next election. But candidates who win (the incumbent) tend to better than challengers from the same party. To overcome this, Lee used an RDD with the Democratic share of the two-party vote in the last election as the forcing variable for Democratic incumbency in the current election. Thee key idea is that, in close elections, seats where a Democratic candidate won will have similar characteristics to districts where a Democratic candidate lost.
- Lee study of the incumbency effect
- Lakeland recommends using Bayesian estimation and Chebyshev Polynomials
- Packages
- Types
- Sharp RDD:
- The threshold separates the treatment and control group exactly
- Fuzzy RDD:
- The threshold influences the probability of being treated
- This is in fact an instrumental variable approach (estimating a LATE)
- Sharp RDD:
- Terms
- Forcing or Assignment or Running Variable:
- Used to assign units to the intervention group and comparison group on either side of a fixed threshold (Cutoff Score).
- May or may not be related to the potential outcomes but we assume that relationship is smooth, so that changes in the outcome around the threshold can be interpreted as a causal effect.
- Bandwidth - The number of points selected on each side of the cutoff
- Should be wide enough to include a sufficient number of observations and obtain precise estimates. It should also be narrow enough to compare similar units and reduce selection bias.
- Current best practice for defining the “neighborhood” of the threshold is to use weights based on a triangular kernel and an “optimal” bandwidth proposed by Imbens and Kalyanaraman (2012). The optimal bandwidth is derived for the simple RDD model with no covariates, though the authors comment that inclusion of additional covariates should not greatly affect the result unless the covariates are strongly correlated with the outcome, conditional on the running variable.
- Forcing or Assignment or Running Variable:
- Steps
- Find and include adjustment variables for differences between the treatment and control groups. Avoid only adjusting for one pre-treatment variable.
- Those individuals on both sides of the cut-off point, should be very similar (i.e. it’s more or less random that they’re on one side of the cutoff and not the other). Therefore have something close to a random allocation into treatment and control group
- i.e if the cutoff is a test score of 71, then, characteristically, students scoring a 70 should be very similar to students scoring a 72.
- Including covariates shouldn’t affect the LATE very much but should help lower the std errors some.
- If there is a large effect then the function is probably creating interaction terms with treatment and the covariates. (see bkmk)
- Those individuals on both sides of the cut-off point, should be very similar (i.e. it’s more or less random that they’re on one side of the cutoff and not the other). Therefore have something close to a random allocation into treatment and control group
- Fit a regression line (or curve) for the intervention group and similarly for the comparison group,
- The difference in these regression lines at the threshold value of the forcing variable is the estimate of the effect of the intervention (i.e. Local Average Treatment Effect (LATE)).
- Find and include adjustment variables for differences between the treatment and control groups. Avoid only adjusting for one pre-treatment variable.
- Example: Corruption
From
Do businesspeople who win elected office in Russia use their positions to help their former firms?
Variables:
- Outcome:
- Log total revenue of the candidate’s former firm
- Profit margin: net profit/total revenue during last year of term if member won election or if the member lost, the last year of the hypothetical term if they had won.
- Treatment: electoral victory or not (1/0)
- Running: Vote margin (difference between former firm member/current candidate and their opponent
- negative if former firm member lost, positive if they won
- Cutoff = 0
- Outcome:
Assumptions
- Check for manipulation of the running variable
Examine the balance along a range of covariates between winning and losing candidates in close elections (i.e. around the threshold).
- If no significant imbalance is detected, then there’s no evidence that electoral manipulation favors a specific type of candidate or firm
- Is there any coordination among firms and their candidates?
- If so, we’d expect to see a sharing of the spoils after the election. Therefore, some conspicuous number of firm’s revenue or profit margin should increase even though they lost.
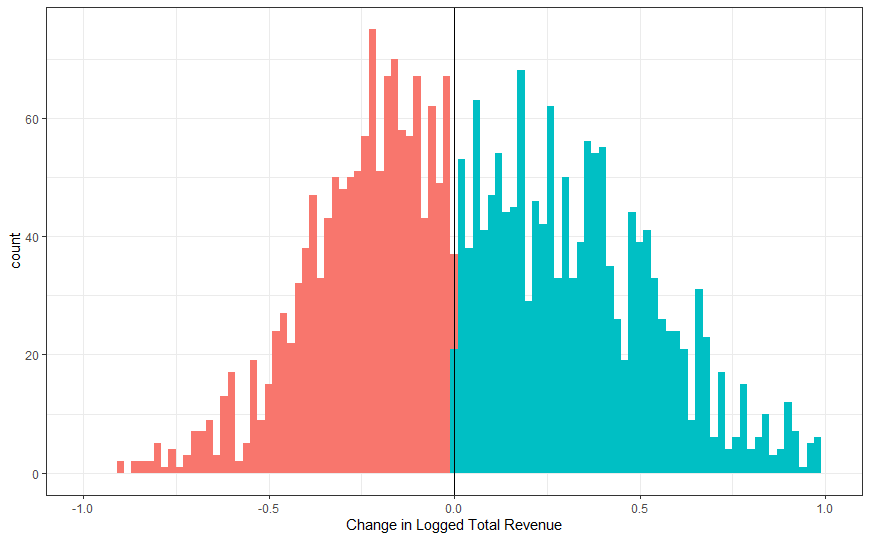
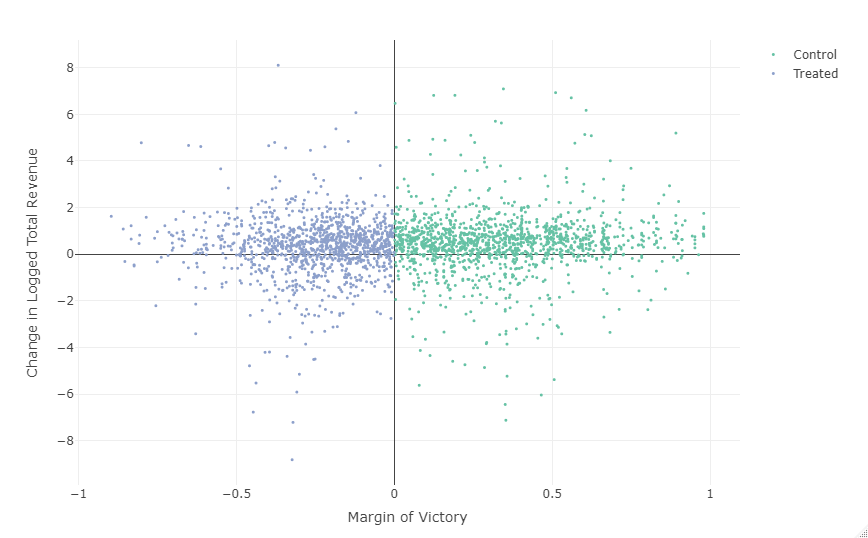
- The splits looks pretty even around the cutoff between treated (winners) and control (losers)
- If so, we’d expect to see a sharing of the spoils after the election. Therefore, some conspicuous number of firm’s revenue or profit margin should increase even though they lost.
Density Test: assess the validity of the assumption of continuity around the threshold.
library(rddensity) summary(rddensity(X = cons$margin, vce="jackknife")) #> Manipulation testing using local polynomial density estimation. #> Number of obs = 2806 #> Model = unrestricted #> Kernel = triangular #> BW method = estimated #> VCE method = jackknife #> c = 0 Left of c Right of c #> Number of obs 1332 1474 #> Eff. Number of obs 448 409 #> Order est. (p) 2 2 #> Order bias (q) 3 3 #> BW est. (h) 0.157 0.172 #> Method T P > |T| #> Robust -1.7975 0.0723- Have to check out docs + referenced papers to get a detailed idea of whats happening, but the p-value is what’s important
- X is the running variable
- pval > 0.05 says not enough evidence to reject null where H0: there’s continuity around the cutoff (i.e. no manipulation)
- Check for manipulation of the running variable
Fit the RDD
library(rdrobust) fit <- rdrobust(cons$fullturnover.e.l.d, cons$margin, c = 0, all=TRUE) summary(fit) BW est. (h) 0.138 0.138 BW bias (b) 0.260 0.260 ============================================================================= Method Coef. Std. Err. z P>|z| [ 95% C.I. ] ============================================================================= Conventional 0.548 0.197 2.777 0.005 [0.161 , 0.934] Bias-Corrected 0.619 0.197 3.136 0.002 [0.232 , 1.005] Robust 0.619 0.225 2.746 0.006 [0.177 , 1.060] =============================================================================- Outcome: cons$fullturnover.e.l.d
- Running: cons$margin
- c is the cutoff (default = 0)
- all = TRUE says to report three different methods for std.errors
- Conventional RD estimates with conventional standard errors.
- Bias-corrected estimates with conventional standard errors.
- Bias-corrected estimates with robust standard errors.
- BW est (for Conventional estimate), BW bias (for bias-corrected estimate) are the bandwidths used
rdbwselectcan be used to calculate diffferent bandwidths and then specified inrdrobustwith h and b args.- If 2 numbers are provided for an arg, then it specifies different bandwidths for before and after the cutoff
- There are a quite a few different methods available (see manual for details)
- default “mserd”: one common MSE-optimal bandwidth selector for the RD treatment effect estimator
- p and q args specify the order of polynomial to be used to fit the Conventional model and Bias-corrected model respectively (default = 2 , quadratic)
- Interpretation
- The LATE is 0.548 with a pval = 0.005.
- There is enough evidence to reject the claim that when a businessperson from a company barely wins an election to a state legislature, there is no effect to the firm’s revenue.
- The revenue of the firm in the next year will be 0.548 larger than if the businessperson didn’t win the election
Potential covariates in this dataset: dummy for foreign ownership, a dummy for state ownership, and logged total fixed assets in the year prior to taking office (baseline feature), categorical financial sector of the firm.
Sensitivity Checks
- Adjust the bandwidth and polynomial orders
- if your effect is no longer significant or looks substantially different, then your result is too sensitive and not very credible.
Robustness Checks
- Test other values of the cutoff variable.
- There shouldn’t be a significant effect or one that is similar in strength to the effect when the original cutoff was used.
- Example: Sometimes a rdd isn’t the answer
- Might be worth following this precedure and use the results as a check on the rdd or as a alternative after an rdd doesn’t show convincing results
- From Gelman critique, “Air Filters, Pollution, and Student Achievement”:
- Description:
- Aliso Canyon gas leak leads many schools to install air filters. RDD study shows test scores went up after the filters were installed. What follows is how Gelman would have conducted the study.
.png)
- Aliso Canyon gas leak leads many schools to install air filters. RDD study shows test scores went up after the filters were installed. What follows is how Gelman would have conducted the study.
- Steps
- Compare outcomes in schools in the area with and without air filters
- Fit a regression
- data has one row per school
- outcome being average post-test score per school
- predictors: average pre-test score per school
- indicator: air filters installed
- Fit a regression
- Make a scatterplot of post-test vs. pre-test with one point per school, displaying treated schools as open circles and control schools as dots.
- Make a separate estimate and graph for each grade level if you’d like, but I’m guessing that averages will give you all the information you need.
- Make plots of pre-test scores, post-test scores, and regression residuals on a map, using color intensities. I don’t know that this will reveal much either, but who knows. I’d also include the schools in the neighborhood that were not part of the agreement
- (Optional) fit a multilevel model using data from individual students (random effect)—why not, it’s easy enough to do—but I don’t think it will really get you much of anything beyond the analysis of school-level averages.
- Compare outcomes in schools in the area with and without air filters
Propensity Score Matching
- A Propensity Score is the probability of being assigned to a certain treatment, conditional on pre-treatment (or baseline) characteristics
Misc
- Also see Survey, Analysis >> Weights >> Types >> Inverse Probability Weights
- Packages
- {MatchIt}: propensity score methods
- Also non-parametric: nearest neighbor matching, optimal pair matching, optimal full matching, genetic matching, exact matching, coarsened exact matching, cardinality matching, and subclassification
- {MatchThem}
- Provides essential tools for the pre-processing techniques of matching and weighting multiply imputed datasets.
- Vignette
- {nbpMatching} - Functions for Optimal Non-Bipartite Matching. Reweighted Mahalanobis Distance Matching
- A “bipartite” matching utilizes two separate groups, e.g. smokers being matched to nonsmokers or cases being matched to controls.
- A “non-bipartite” matching creates mates from one big group
- 100 hospitals being randomized for a two-arm cluster randomized trial
- 5000 children who have been exposed to various levels of secondhand smoke and are being paired to form a greater exposure vs. lesser exposure comparison.
- Others
- {twang}, {Matching}, {optmatch}, {CBPS}, {ebal}, {WeightIt}, {designmatch}, {sbw}, and {cem}
- Viz
- {cobalt}: balance tables and plots using output from above packages
- {MatchIt}: propensity score methods
- Notes from
- Twitter thread
- slack::kris used “coarsened exact matching” in his project. No idea what this is. Need to check it out.
- Paper: Choosing the Estimand When Matching or Weighting in Observational Studies
- How to choose an estimand based on your question (and how that maps to particular weighting / matching choices)
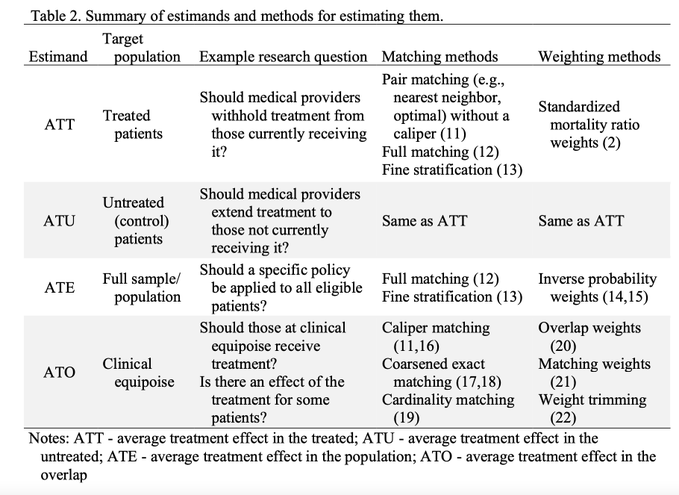
- How to choose an estimand based on your question (and how that maps to particular weighting / matching choices)
BBR Chapter 17.2 to 17.8
Biostatistics for Biomedical Research (Harrell) Ch.17.2 - 17.8: Modeling for Observational Treatment Comparisons
Adjusting for Confounders
- Use of the Propensity Score (PS) allows one to aggressively adjust for measured potential confounders
- Doing an adjusted analysis where the adjustment variable is the PS simultaneously adjusts for all the variables in the score insofar as confounding is concerned (but not with regard to outcome heterogeneity)
- Stratifying for PS does not remove all the measured confounding
But adjusting only for PS is inadequate.
- To get proper conditioning so that the treatment effect can generalize to a population with a different covariate mix, one must condition on important prognostic factors
- Non-collapsibility of hazard and odds ratios is not addressed by PS adjustment
- Adjusting only for PS can hide interactions with treatment
PS is not necessary if the effective sample size (e.g. number of outcome events) > 5p where p is the number of measured covariates
When judging covariate balance (as after PS matching) it is not sufficient to examine the mean covariate value in the treatment groups
Treatment Effects
- Eliminate units in intervals of PS where there is no overlap between treatment A and treatment B, or include an interaction between treatment and a baseline characteristic
- Example: Including an interaction between age and treatment and there were no units greater than 70 years old receiving treatment B
- Then, the B:A difference for age greater than 70 would have an extremely wide confidence interval as it depends on extrapolation. So the estimates that are based on extrapolation are not misleading; they are just not informative.
- Example: Including an interaction between age and treatment and there were no units greater than 70 years old receiving treatment B
- Eliminate units in intervals of PS where there is no overlap between treatment A and treatment B, or include an interaction between treatment and a baseline characteristic
Types
- Pairs Matching
- Throws away data –> low power
- Units get discarded that have characteristics which are the same as another unit and has already been matched (i.e. units that have the same information)
- Throws away data –> low power
- Inverse Probability Weighting
- a high variance/low power approach like matching
- Also see Survey, Analysis >> Weights >> Types >> Inverse Probability Weights
- Pairs Matching
Modeling
\[\begin{align} Y =\:\: &\operatorname{treat} + \log \frac{\text{PS}}{1-\text{PS}} \\ &+ \text{nonlinear functions of}\: \log \frac{\text{PS}}{1-\text{PS}} \\ &+ \text{important prognostic variables} \end{align}\]
- In biostatistics, a prognostic factor or variable is a patient characteristic that can predict that patient’s eventual response to an intervention
- Prognostic variables need to be in model even though they are also in the PS, to account for subject outcome heterogeneity (susceptibility bias)
- If outcome is binary and you can afford to ignore prognostic variables, use nonparametric regression, Y ~ PS, and fit a model to each treatment group’s data
- Nonparametric Regression - does not assume linearity; only assumes smoothness, Y ~ X where X is continuous
- e.g. moving avg, loess, other smoothers, etc.
- See BBR Ch 8.7 for details, examples (no binary outcome examples)
- Checking functional form in logistic regression using loess plots
- Shows a binary outcome used in a loess model
- Plotting these two curves with PS on x-axis and looking at vertical distances between curves is an excellent way to adjust for PS continuously without assuming a model
- Guessing the average distance between the curves is the treatment effect (?)
- Nonparametric Regression - does not assume linearity; only assumes smoothness, Y ~ X where X is continuous
Psuedo-Distributions After Weighting According to the Type of Estimand
- {cobalt} (not on CRAN) can be used to produce the balance plots below using output from various propensity scoring packages (see above)
- Shows how weights derived from propensity scores makes treatment and control groups comparable
- Light green and light blue show psuedo-counts that are added to the groups after applying weights
- No Estimand
- Mirrored histogram of propensity scores for treatment (top) and control (bottom) groups
- No groups are upweighted (or equivalently, for both groups, weights = 1)
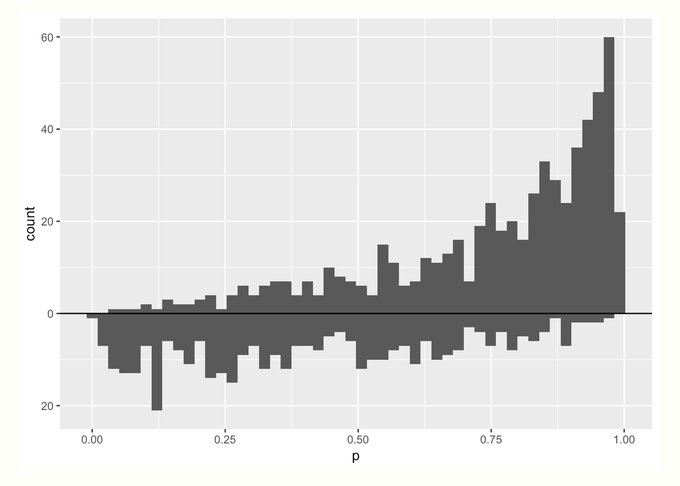
- x-axis is the propensity score
- y-axis is the count of people with that score
- More mass on the *right* in the treatment group (top) means that more people in that group had a higher probability of receiving treatment (duh)
- More mass in the treatment group than the control group means more people received the treatment than control
- Average Treatment Effect (ATE)
- Target: whole population
- Treated and Control groups are upweighted
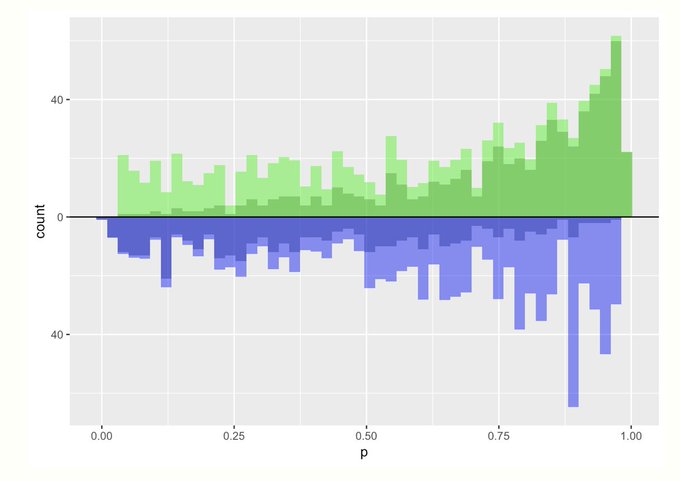
- Light green and light blue show psuedo-counts that are added to the groups after applying weights
- Both groups now similar (i.e. comparable)
- individual \(\text{unit}_i\) weights
- \(\text{treatment\_weight}_i = \frac{1}{\text{propensity\_score}_i}\)
- \(\text{control\_weight}_i = \frac{1}{1 - \text{propensity\_score}_i}\)
- Potential Issues
- Weights are unbounded
- Really small propensity scores for the Treatment group (or really large ones for control) could have an oversized effect on the analysis.
- Can lead to finite sample bias // variance issues
- Weights are unbounded
- Average Treatment Effect on the Treated (ATT)
- Target: treatment group
- Control group is upweighted
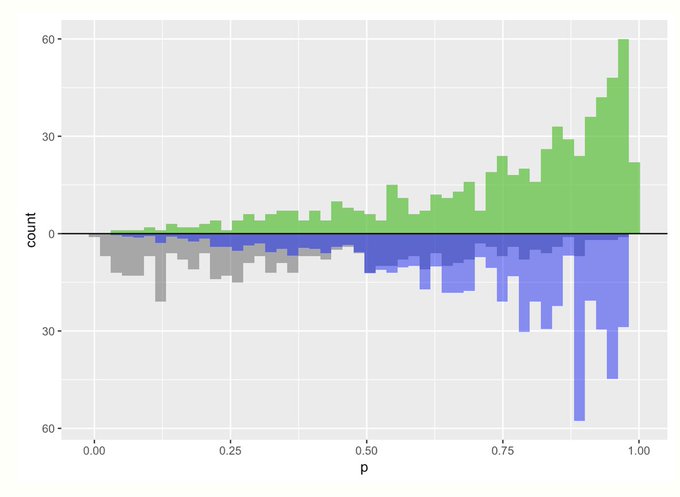
- Individual \(\text{unit}_i\) weights
- \(\text{treatment\_weight}_i = 1\)
- \({\text{control\_weight}_i} = \frac{\text{propensity\_score}_i}{1 - \text{propensity\_score}_i}\)
- Individual \(\text{unit}_i\) weights
- Potential Issues
- Extremely unbalanced groups
- In this example, there are much more treated units than control units \(\rightarrow\) control group must be substantially upweighted to become comparable
- Can lead to instability
- Extremely unbalanced groups
- Average Treatment Among Overlap Population (ATO)
- Target: Clinical equipoise
- The assumption that there is not one ‘better’ intervention present (for either the control or experimental group) during the design of a randomized controlled trial (RCT). A true state of equipoise exists when one has no good basis for a choice between two or more care options.
- See Notes from >> Paper for more details
- Treated is downweighted
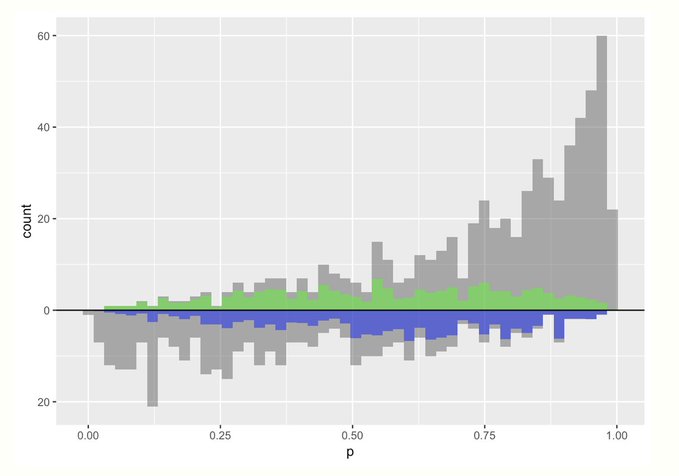
- Individual \(\text{unit}_i\) weights
- \(\text{treatment\_weight}_i = 1 - \text{propensity\_score}_i\)
- \(\text{control\_weight}_i = \text{propensity\_score}_i\)
- Individual \(\text{unit}_i\) weights
- Weights are bounded by 0 and 1, so they have nice variance properties
- Target: Clinical equipoise