Feature Stores
Misc
Benefits
- Increases Reproducibility
- Easily track the version of the features used in each model and reproduce the model’s results if needed.
- Useful in a collaborative environment where multiple people are working on the same project.
- Discovery and Testing Features Easier
- Having features in a centralized location makes comparing the performance of various features and versions of those features easier.
- Easier to Scale
- It’s easier to share features between ML models which means fewer resources (e.g. development, deployment) will be required. Allowing more models to be added more efficiently and cheaply.
- Increases Reproducibility
Features of a Feature Store
- Designed with ML modelling in mind
- Can handle large amounts of data and perform feature engineering at scale
- Handles versioning of features
- Easy to track which features were used for a particular model, making it simple to reproduce or deploy the model in the future
- Allows for different levels of access control
- A data scientist can work on a feature without worrying about affecting other users which can’t be said about warehouses
- Designed with ML modelling in mind
Best used if you have a substantial number of features that are computationally expensive, frequently improved, and used in many ML models.
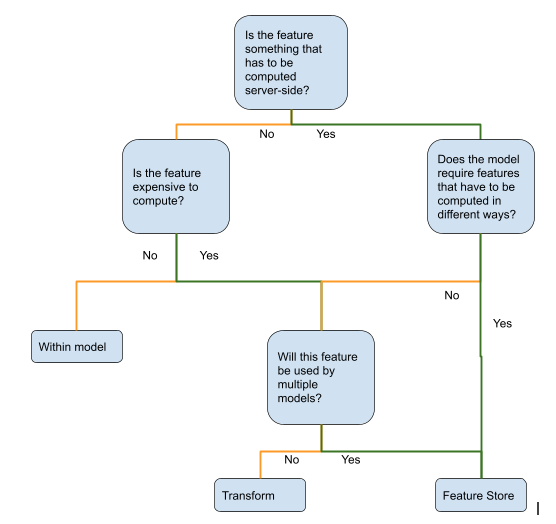
Here “Transform” is referring to something like an AWS lambda function that’s triggered to transform the data
Cases where adding a feature store adds unnecessary complexity:
- Feature value needs to “seen” by the client (e.g. app)
- Not exactly sure why this matters or what “seen” means
- Maybe this is a latency thing?
- Feature is in a data warehouse.
- Feature isn’t time dependent
- So only streaming and not batch serving I think
- Computationally inexpensive
- Feature value needs to “seen” by the client (e.g. app)
Example
- Embedding of a song, artist, and user features in a music streaming service.
- There is a team updating user and song embeddings on a daily basis. Every time the model that consumes this feature, it is retrained — high commercial value use cases will need to re-train periodically — the training code will need to fetch the values of this feature that align with the training labels and the latest version of the embedding algorithm.
- Embedding of a song, artist, and user features in a music streaming service.
Positioning within a pipeline
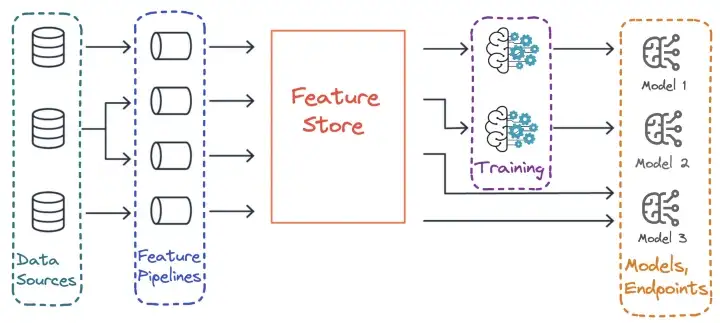
- Looks like something dbt (“Feature Pipelines”) would write to.
- Reminds me of the description of a data mart.
Connectors
- TensorFlow’s TFXI (TensorFlow Extended Input/Output)
- Module allows you to easily read data from Feature store and feed it into your TensorFlow model.
- Supports data preprocessing, so you can do things like normalization and feature selection right within TensorFlow.
- PyTorch’s DataLoader
- Class that allows you to easily read data from Feature store, process, and feed it into your PyTorch model.
- TensorFlow’s TFXI (TensorFlow Extended Input/Output)
Brands
- Google Vertex AI feature store
- Amazon SageMaker Feature Store
- Databricks Feature Store
- HopsWorks Feature Store
- tecton.ai
- site
- cloud agnostic
- bytehub
- Feast
- It is a standalone, open-source feature store that organizations use to store and serve features consistently for offline training and online inference.
- DataRobot
- Algoworks
- Hugging Face: A feature store for natural language processing (NLP) models that allows for easy sharing and management of pre-trained models and features.