Statistical
Misc
- CRAN Task View
- {aggreCAT} - Mathematically Aggregating Expert Judgments (forecast adjustments)
- Forecasts often get adjusted by persons with domain knowledge
- {ardlverse} - Comprehensive Autoregressive Distributed Lag ARDL Modeling Framework: Panel, Bootstrap, Quantile-Nonlinear, and Fourier Extensions
- {bdlnm} - A Bayesian framework for estimating distributed lag linear and non-linear models.
- {bssm} (Paper) - Efficient methods for Bayesian inference of state space models via particle Markov chain Monte Carlo and importance sampling type weighted MCMC.
- Currently Gaussian, Poisson, binomial, negative binomial, and Gamma observation densities with linear-Gaussian state dynamics, as well as general non-linear Gaussian models and discretely observed latent diffusion processes are supported.
- {BTWAR} - Implements the Butterworth-Induced Autoregressive model, where autoregressive coefficients are obtained from analog Butterworth filter prototypes mapped into the discrete-time domain using the Matched Z-Transform
- {dlnm} - Collection of functions for distributed lag linear and non-linear models. Includes penalized models
- {fasster} - Fast Additive Switching of Seasonality, Trend, and Exogenous Regressors
- Combines state space methodology with a switching component in the observation equation to allow flexible modeling of complex seasonal patterns, including time-varying effects and multiple seasonalities.
- {fqardl} - Fourier ARDL Methods: Quantile, Nonlinear, Multi-Threshold & Unit Root Tests
- {forecast} - OG
- {fracARMA} (Paper)- Implements fractional differencing with Autoregressive Moving Average models to analyse long-memory time series data.
- {GACE} - Provides deterministic forecasting for weekly, monthly, quarterly, and yearly time series using the Generalized Adaptive Capped Estimator.
- Looks like a fairly simple model that might be good for a base model
- {kardl} - Implements estimation procedures for Autoregressive Distributed Lag (ARDL or ADL) and Nonlinear ARDL (NARDL) models, which allow researchers to investigate both short- and long-run relationships in time series data under mixed orders of integration.
- Cointegration testing approaches such as the Pesaran-Shin-Smith F and t bounds tests, the Banerjee error correction test, and the restricted ECM test, together with diagnostic tools including Wald tests for asymmetry, ARCH tests, and stability procedures (CUSUM and CUSUMQ)
- {KFAS} (Vignette) - Kalman Filtering and Exponential Family State Space Models
- State space modeling with the observations from an exponential family, namely Gaussian, Poisson, binomial, negative binomial and gamma distributions
- Exponential family state space models such as structural time series, ARIMA models, generalized linear models and generalized linear mixed models
- {narfima} - Methods and tools for forecasting univariate time series using the NARFIMA (Neural AutoRegressive Fractionally Integrated Moving Average) model.
- Combines neural networks with fractional differencing to capture both nonlinear patterns and long-term dependencies.
- {qardlr}: Quantile Autoregressive Distributed Lag Model
- {smooth} (book) - Functions implementing Single Source of Error state space models for purposes of time series analysis and forecasting.
- ADAM (Augmented Dynamic Adaptive Model) is the primary model but also implements Exponential Smoothing, SARIMA, Complex Exponential Smoothing, and Simple Moving Average
- Allows dealing with intermittent demand based on the iETS framework
- {THETASVM} - Combines the distinct strengths of the THETA model and the Support Vector Machine (SVM) model for time series forecasting.
- tidyverts
- {fable} - Provides a collection of commonly used univariate and multivariate time series forecasting models including exponential smoothing via state space models and automatic ARIMA modelling
- {feasts} - Feature Extraction, Diagnostics, And Statistics for Time Series
- {fable.binary} - Models suitable for binary time series.
- {fabletools} - Tools for building modelling packages, with a focus on time series forecasting.
- Allows package developers to extend fable with additional models, without needing to depend on the models supported by fable.
- {tseffects} - Dynamic (Causal) Inferences from Time Series (with Interactions)
- Focuses on Autoregressive Distributed Lag (ADL) and Generalized Error-Correction Model (GECM)
- Tools for recovering those inferences in three forms: causal inferences from ADL models, traditional time series quantities of interest (short- and long-run effects), and dynamic conditional relationships.
- {tsissm} - Linear Innovations State Space Unobserved Components Model
- Sort of an enhanced TBATS model
- Handles missing values, irregular series, and complex seasonalities
- Handles heteroskedacity (i.e. time-varying variance) by modeling the residuals with a GARCH model
- Ensembles forecasts and deals with the dependent residuals with a Gaussian Copula
- {xtpqardl} - Panel Quantile Autoregressive Distributed Lag Model
- Estimation of Panel Quantile Autoregressive Distributed Lag (PQARDL) models that combine panel ARDL methodology with quantile regression.
- Supports Pooled Mean Group (PMG), Mean Group (MG), and Dynamic Fixed Effects (DFE) estimators across multiple quantiles
- {xtcspqardl} - Cross-Sectionally Augmented Panel Quantile ARDL
- Implements the Cross-Sectionally Augmented Panel Quantile Autoregressive Distributed Lag (CS-PQARDL) model and the Quantile Common Correlated Effects Mean Group (QCCEMG) estimator for panel data with cross-sectional dependence
- For intermittent data, see Logistics >> Demand Planning >> Intermittent Demand
- Let the context of the decision making process determine the units of the forecast
- i.e. Don’t forecast on a hourly scale just because you can.
- What can be forecast depends on the predictability of the event:
- How well we understand the factors that contribute to it;
- We have a good idea of the contributing factors: electricity demand is driven largely by temperatures, with smaller effects for calendar variation such as holidays, and economic conditions.
- How much data is available;
- There is usually several years of data on electricity demand available, and many decades of data on weather conditions.
- How similar the future is to the past;
- For short-term forecasting (up to a few weeks), it is safe to assume that demand behaviour will be similar to what has been seen in the past.
- Whether the forecasts can affect the thing we are trying to forecast.
- For most residential users, the price of electricity is not dependent on demand, and so the demand forecasts have little or no effect on consumer behaviour.
- How well we understand the factors that contribute to it;
- Starting a project
- Understand the dgp through eda and talking to domain experts
- How are sales generated? (e.g. online, brick and mortar,…)
- What is the client currently using to forecast?
- Model that you need to beat
- Where does it fail?
- Biased? underfitting or overfitting somewhere
- Missing seasonality?
- What is the loss function?
- Carrying this many items in inventory results in this cost
- If we’re out of stock and lose this many sales, how much does this cost
- What does the client really want?
- How is success measured
- Understand the dgp through eda and talking to domain experts
- Fable models produce different results with NAs in the time series
- In rolling cfr project, steinmetz’s manually calc’d rolling 7-day means and his lagged vars had NAs, models using data with and without NAs had different score
- It is helpful to keep track of and understand what our forecast bias has historically been. Even where we are fortunate enough to show a history of bias in both directions.
- Forecasting shocks is difficult for an algorithm
- Also see
- Logistics, Demand Planning >> Article Notes >> Dealing with Shocks
- Forecasting, Deep Learning >> Misc >> Predictive Adjustment
- It can better to smooth out (expected) shocks (Christmas) in the training data and then add an adjustment to the predictions during the dates of the shocks.
- The smoothed out data will help the algorithm produce more accurate predictions for days when there isn’t an expected shock.
- Examples of shocks that may need training data to have manual adjustments and not be smoothed by an algorithm
- One-Time spikes due to abnormal weather conditions
- One-Off promotions
- A sustained marketing campaign that is indistinguishable from organic growth.
- Also see
- Intermittent(or sporadic) time series (lotsa zeros).
- {thief} has the latest methods while {tsintermittent} has older methods
- Benchmark models
- Naive
- 28-day moving average (i.e. 4 week MA)
Terms
- Weak stationarity (commonly referred to as just stationarity)(aka covariance stationary) - Implies that the mean and the variance of the time series are finite and do not change with time.
- Cointegration - \(x_t\) and \(y_t\) are cointegrated if \(x_t\) and \(y_t\) are \(I(1)\) series and there exists a \(\beta\) such that \(z_t = x_t - \beta y_t\) is an \(I(0)\) series (i.e. stationary).
- Important for understanding stochastic or deterministic trends.
- The differences in the means of the set of cointegrated series remain constant over time, without offering an indication of directionality
- Might have low correlation, and highly correlated series might not be cointegrated at all.
- Can use Error Correction Model (ECM) with differenced data and inserting a error correction term (residuals from a OLS regression)
- Long Memory Time Series - A time series where observations in a data sequence exhibit significant dependence or correlation even across long time intervals. This is in contrast to short memory processes where correlations decay quickly
- Autocorrelation that decays very slowly (typically following a power law) rather than the exponential decay seen in short memory processes
- Measured using the Hurst Exponent (H) (article), where:
- \(H \gt 0.5\) indicates long memory with positive correlation
- \(H = 0.5\) indicates random walk/no memory
- \(H \lt 0.5\) indicates anti-persistent behavior
- {pracma::hurstexp}
- ARIMA can be used for short memory or anti-persistent time series
- ARFIMA (Fractionally Integrated ARMA) allows fractional differencing, enabling it to effectively capture long memory characteristics in time series data
- Nowcasting - The process of estimating the current state of a phenomenon when the data are incomplete due to reporting delays.
- See Economics >> Misc for packages
- Stochastic - No value of a variable is known with certainty. Some values may be more likely than others (probabilistic). Variable gets mapped onto a distribution.
Preprocessing
- Filling in gaps
- Bi-directional forecast method from AutoML for time series: advanced approaches with FEDOT framework
- Steps
- Smooth series prior to the gap
- They used a “Gaussian filter w/sigma = 2” (not sure what that is)
- Create lagged features of the smoothed series
- Forecast using ridge regression where h = length of gap
- Repeat in the opposite direction using the series after the gap
- Use the average of the forecasts to fill the gap in the series.
- Smooth series prior to the gap
- Steps
- Bi-directional forecast method from AutoML for time series: advanced approaches with FEDOT framework
- Log before differencing (SO post)
- Detrend or Difference
- (The goal is to get a stationary series, so if one doesn’t work try the other.)
- Differencing (for unit root processes)(stochastic trend)
- if the process requires differencing to be made stationary, then it is called difference stationary and possesses one or more unit roots.
- Sometimes see charts of roots and a unit circle. I read this in an article about VAR models “process is stationary if all the roots \(z_1, \ldots , z_n\) of the determinant \(\det(\psi(z))\), or \(\det(I − Bz) = 0\), lie outside of the unit circle.”
- One advantage of differencing over detrending to remove trend is that no parameters are estimated in the differencing operation.
- One disadvantage, however, is that differencing does not yield an estimate of the stationary process
- If the goal is to coerce the data to stationarity, then differencing may be more appropriate.
- Differencing is also a viable tool if the trend is fixed
- Random Walking looking series should be differenced and not detrended.
- Backshift operator notation:
- In general: \(\nabla^d = (1 − B)^d\)
- Where \(d\) is the order of differencing
- Fractional differencing is when \(0 \lt d \lt 1\)
- When \(0 \lt d \lt 0.5\), the series is classified as a long term memory series (often used for environmental time series arising in hydrology)
- See Misc >> Packages >> {fracARMA}
- If \(d\) is negative, then its called forward-shift differencing
- Examples:
Identities:
\[ B y_t = y_{t-1} \\ B^2 y_t = y_{t-2} \]
Seasonal Difference:
\[ (1 - B)(1 - B^m) y_t = (1 - B - B^m + B^{m + 1})y_t = y_t - y_{t-1} - y_{t-m} + y_{t-m-1} \]
ARIMA : AR(p)I(d) = MA(q)
\[ (1-\phi_1 B - \cdots - \phi_p B^p)(1-B)^d y_t = c+(1+\theta_1 B + \cdots + \theta_q B^q)\epsilon_t \]
ARIMA(1,1,1)(1,1,1)4 for quarterly data (m = 4)
\[ (1-\phi_1 B)(1-\Phi B^4)(1-B)(1-B^4)y_t = (1+\theta_1 B)(1+\Theta B^4)\epsilon_t \]
- In general: \(\nabla^d = (1 − B)^d\)
- if the process requires differencing to be made stationary, then it is called difference stationary and possesses one or more unit roots.
- Detrending (for trend-stationary processes)(deterministic trend)
- It is possible for a time series to be non-stationary, yet have no unit root and be trend-stationary
- a trend-stationary process is a stochastic process from which an underlying trend (function solely of time) can be removed (detrended), leaving a stationary process.
- If an estimate of the stationary process is essential, then detrending may be more appropriate.
- How is this back-transformed after forecasting?
- maybe look at “forecasting with STL” section in fpp2
- It is possible for a time series to be non-stationary, yet have no unit root and be trend-stationary
- In both unit root and trend-stationary processes, the mean can be growing or decreasing over time; however, in the presence of a shock, trend-stationary processes are mean-reverting (i.e. transitory, the time series will converge again towards the growing mean, which was not affected by the shock) while unit-root processes have a permanent impact on the mean (i.e. no convergence over time).
- Testing
- KPSS test: H0 = Trend-Stationary, Ha = Unit Root.
urca::ur_kpssthe H0 is stationaritytseries::kpss.test(res, null = "Trend")where H0 is “trend-stationarity”
- Dickey-Fuller tests: H0 = Unit Root, Ha = Stationary or Trend-Stationary depending on version
- KPSS-type tests are intended to complement unit root tests, such as the Dickey–Fuller tests. By testing both the unit root hypothesis and the stationarity hypothesis, one can distinguish series that appear to be stationary, series that appear to have a unit root, and series for which the data (or the tests) are not sufficiently informative to be sure whether they are stationary.
- {boundedur} - Unit Root Tests for Bounded Time Series
- {qadf} - Quantile Autoregressive Distributed Lag Unit Root Test
- unitrootests - Comprehensive Unit Root and Stationarity Tests
- KPSS test: H0 = Trend-Stationary, Ha = Unit Root.
- Steps:
- ADF:
- If H0 rejected. The trend (if any) can be represented by a deterministic linear trend.
- If H0 is not rejected then we apply the KPSS test.
- KPSS :
- If H0 rejected then we conclude that there is a unit root and work with the first differences of the data.
- Upon the first differences of the series we can test the significance of other regressors or choose an ARMA model.
- If H0 is not rejected then data doesn’t contain enough information. In this case it may be safer to work with the first differences of the series.
- If H0 rejected then we conclude that there is a unit root and work with the first differences of the data.
- ADF:
- Steps when using an ARIMA:
- Suppose the series is not trending
- If the ADF test (without trend) rejects, then apply model directly
- If the ADF test (without trend) does not reject, then model after taking difference (maybe several times)
- Suppose the series is trending
- If the ADF test (with trend) rejects, then apply model after detrending the series
- If the ADF test (with trend) does not reject, then apply model after taking difference (maybe several times)
- Suppose the series is not trending
Diagnostics
- Testing for significant difference between model forecasts
- Nemenyi test
sutils::nemenyi
- MCB
greybox::rmcb
- Nemenyi test
Algorithms
Misc
- Auto Arima, ETS and Theta are general-purpose methods particularly well-suited for monthly, quarterly and annual data
- TBATS and STL will also handle multiple seasonalities such as arise in daily and weekly data.
- When to try nonlinear models (see Forecasting, Nonlinear)
- Linear prediction methods (e.g. ARIMA) don’t produce adequate predictions
- Chaotic nature of the time series is obvious (e.g. frequent, unexplainable shocks that can’t be explained by noise)
Regression (including ARIMA)
Misc
- Packages
- {fable::ARIMA}, {forecast::auto.arima}
- {arima2} (Paper) - Uses a random-restart algorithm to maximize the likelihood. This algorithm cannot result in models with lower likelihoods than that of
stats::arimafunction. It can obtain higher ones but at the cost of computational effiicency. If the number of restarts is n, then this algorithm will be approximately n-times slower.- Mostly necessary for small datasets (n ≪ 10000), where default parameter initialization strategies may perform poorly
- Double check
auto_arima, for the parameters, (p, d, q), one should pick q to be at least p (link) - Sometimes the error terms are called random shocks.
- If using
lmand there are NAs, make sure to use na.action = NULL else they get removed and therefore dates between variables won’t match-up. Seelmdoc for further details on best practices. - ARIMA models make h-step out predictions by iterating 1-step forward predictions and feeding the intermediate predictions in as if they were actual observations (0 are used for the errors)
- Polynomial Autoregression (AR) models exponentiate the lags. So the design matrix includes the lags and the exponentiated series.
If the polynomial is order 3, then order 2 is also included. So, now, the design matrix would be the lags, the square of each lag, and the cube of each lag
Example:
library(dplyr); library(timetk) # tbl w/polynomial design matrix of order 3 # value is the ts values poly_tbl <- group_tbl %>% tk_augment_lags(.value = value, .lags = 1:4) %>% mutate(across(contains("lag"), .fns = list(~.x^2, ~.x^3), .names = "{.col}_{ifelse(.fn==1, 'quad','cube')}"))- .fn is the item number in the .fns list.
- Squared lag 2 will have the name “value_lag2_quad”
- Packages
Types
- AR: single variable with autoregressive dependent variable terms
- ARMA: same as AR but errors models as a moving average
- ARIMA: same as ARMA but with differencing the timeseries
- SARIMA: same as ARIMA but also with seasonal P, D, Q terms
- ARMAX: same as ARMA but with additional exogenous predictors
- Dynamic Regression: OLS regression with modeled (usually arima) errors
- Distributed Lag Model - A dynamic regression model in which the effect of a regressor \(x\) on \(y\) occurs over time rather than all at once (i.e. lagged explanatory variables)
\[ y_t = \alpha + \beta (L) x_t + u_t = \alpha + \sum_{s=0}^\infty \beta_s x_{t-s} + u_t \]- \(\beta_s\) are the lag weights and collectively comprise the lag distribution.
OLS vs ARIMA
- John Mount
- The fear in using standard regression for time series problems is that the error terms are likely correlated.
- So one can no longer appeal to the Gauss Markov Theorem (i.e. OLS is BLUE) to be assured of good out of sample performance (link)
- The fear in using standard regression for time series problems is that the error terms are likely correlated.
- Ryer and Chan regarding Dynamic Regression vs OLS
- “Regression (with arima errors) coefficient estimate on Price is similar to that from the OLS regression fit earlier, but the standard error of the estimate is about 10% lower than that from the simple OLS regression. This illustrates the general result that the simple OLS estimator is consistent but the associated standard error is generally not trustworthy”
- Hyndman
- “The forecasts from a regression model with autocorrelated errors are still unbiased, and so are not “wrong,” but they will usually have larger prediction intervals than they need to. Therefore we should always look at an ACF plot of the residuals.”
- The estimated coefficients are no longer the best estimates, as some information has been ignored in the calculation;
- Meaning modeling the errors to take into account the autocorrelation
- Any statistical tests associated with the model (e.g., t-tests on the coefficients) will be incorrect.
- Affected by the bloated std errors
- The AICc values of the fitted models are no longer a good guide as to which is the best model for forecasting.
- In most cases, the p-values associated with the coefficients will be too small, and so some predictor variables will appear to be important when they are not. This is known as “spurious regression.”
- Removing measurements to mitigate autocorrelation
- From a paper where precipitation amounts are modeled, “we only keep one [of] every three hourly records of precipitation so as to ensure independency between samples.”
- OLS Assumptions (sans linear relationship) (FPP 3, section 7.1)
- Residuals have mean zero; otherwise the forecasts will be systematically biased.
- Residuals are not autocorrelated; otherwise the forecasts will be inefficient, as there is more information in the data that can be exploited.
- Residuals are unrelated to the predictor variables; otherwise there would be more information that should be included in the systematic part of the model
- (Optional) Residuals are normally distributed with a constant variance in order to easily produce prediction intervals.
- John Mount
Trend (\(\beta\) \(t\)) is modeled by setting the variable \(t\) to just an index variable (i.e. \(t = 1, \ldots, T\)). Modeling quadratic trend would be adding in \(t^2\) to the model formula.
- Hyndman suggests that using splines is a better approach than using t2
- From Steinmitz’s CFR article
- Instead of
trend(like in {forecast}), he’s usingpoly(date, 2)to include a quadratic trend
- Instead of
R2 and Adjusted-R2
- Appropriate for time series (i.e. estimate of the population R2), as long as the data are stationary and weakly dependent
- i.e. The variances of both the errors and the dependent variable do not change over time.
- i.e. If \(y_t\) has a unit root (Integrated of order 1, I(1)) (needs differenced)
- Validating a model’s forecasting performance on the test data is much better than measuring the R2 value on the training data.
- Appropriate for time series (i.e. estimate of the population R2), as long as the data are stationary and weakly dependent
Interpretation of coefficients
\[ y_t = \alpha + \beta_0 x_t + \beta_1 x_{t-1} + \cdots + \beta_s x_{t-s} + \cdots + \beta_q x_{t-q} \]
- If \(x\) increases by one unit today, the change in \(y\) will be \(\beta_0+\beta_1+...+\beta_s\) after \(s\) periods; This quantity is called the \(s\)-period interim multiplier. The total multiplier is equal to the sum of all \(\beta\) s in the model.
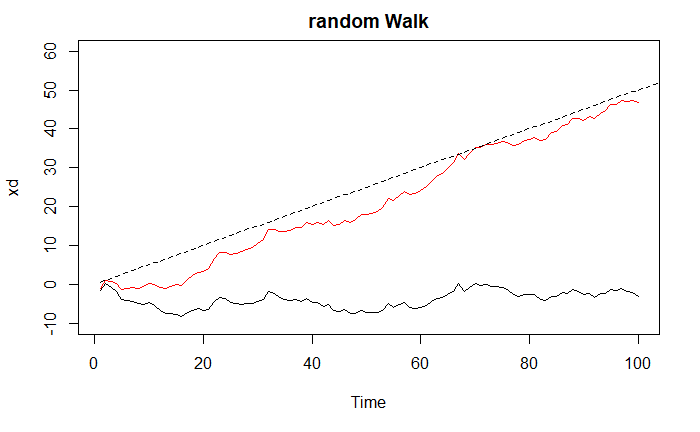
Random Walk
A process integrated to order 1, (an I(1) process) is one where its rate of change is stationary. Brownian motion is a canonical I(1) process because its rate of change is Gaussian white noise, which is stationary. But the random walk itself is not stationary. So the \(t+1\) value of a random walk is just the value at \(t\) plus a number sampled from some bell curve.
Characteristics
- Long periods of apparent trends up or down
- Sudden and unpredictable changes in direction
Also see
- Exploring Random Walks and Brownian Motions with healthyR.ts
- Illustrates using {healthR.ts} functions to simulate Random Walks, Brownian Motion, and Geometric Brownian Motion
- Exploring Random Walks and Brownian Motions with healthyR.ts
A special case of an autoregressive model
\[ y_t = c + \phi_1 y_{t-1} + \cdots + \phi_p y_{t-p} + \epsilon_t \]
- Where \(c=0\), \(p=1\), \(\phi = 1\), and \(\epsilon \sim \mathcal {N}(0, s)\)
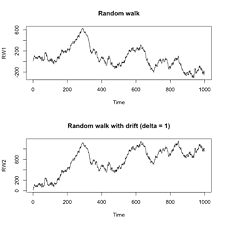
Drift
Feature Random Walk without Drift Random Walk with Drift Steps Purely random, equal probability left/right Biased, one direction slightly more likely Change in value Average change is zero Average change includes a constant drift Path Zig-zag around starting point Zig-zag with upward/downward trend Mean Stays roughly the same Increases/decreases over time depending on drift Variance Increases with time Increases with time Stationarity Non-stationary Non-stationary Examples with and without drift
Prophet
- The basic methodology is an iterative curve-matching routine, where Prophet will then train your data on a bigger period, then predict again and this will repeat until the end point is reached.
- The development team of Prophet claim that its strengths are:
- Working with high-frequency data (hourly, daily, or weekly) with multi-seasonality, such as hour of day, day of week and time of year;
- Special events and bank holidays that are not fixed in the year;
- Allowing for the presence of a reasonable number of missing values or large outliers;
- Accounting for changes in the historical trends and non-linear growth curves in a dataset.
- Further advantages include the ability to train from a moderate sized dataset, without the need for specialist commercial software, and fast start up times for development.
- Disadvantages
- No autoregressive (i.e. lags of target series) features since it’s a curve-fitting algorithm
- Time series decomposition by prophet:
- \(g(t)\): Logistic or linear growth trend with optional linear splines (linear in the exponent for the logistic growth). The library calls the knots “change points.”
- \(s(t)\): Sine and cosine (i.e. Fourier series) for seasonal terms.
- \(h(t)\): Gaussian functions (bell curves) for holiday effects (instead of dummies, to make the effect smoother).
Kalman Filter
Misc
- Notes from How a Kalman filter works, in pictures
- Packages
- {ctsmTMB} - Continuous Time Stochastic Modelling
- The (Continuous-Discrete) Linear Kalman Filter,
lkf. - The (Continuous-Discrete) Extended Kalman Filter,
ekf. - The (Continuous-Discrete) Laplace “Filter”
laplace.
- The (Continuous-Discrete) Linear Kalman Filter,
- {cuthbert} - A JAX library for state-space model inference (filtering, smoothing, static parameter estimation).
- {FKF} (Website) - Fast Kalman Filter Toolbox. Multivariate time series filtering with external time varying inputs
- Fast and flexible implementation of the Kalman filter and smoother, which can deal with NAs
- Written in C and relies fully on linear algebra subroutines contained in BLAS and LAPACK
- Also contains a plot function for the visualization of the state vector and graphical diagnostics of the residuals
- {KFAS} (Vignette) - Kalman Filtering and Exponential Family State Space Models
- {wex} - Compute the Exact Observation Weights for the Kalman Filter and Smoother
- {ctsmTMB} - Continuous Time Stochastic Modelling
- If a dynamic system is linear and with Gaussian noise (inaccurate measurements, etc.), the optimal estimator of the hidden states is the Kalman Filter
- For nonlinear systems, we use the extended Kalman filter, which works by simply linearizing the predictions and measurements about their mean.
- Good for predictions where the measurements of the outcome variable over time can be noisy
- Assumptions
- Gaussian noise
- Markov property
- If you know \(x_{t−1}\), then knowledge of \(x_{t−2},\ldots , x_0\) doesn’t give any more information about \(x_t\) (i.e. not much autocorrelation if at all)
- tl;dr
- A predicted value from a physically-determined autoregression-type equation with 1 lag that gets adjusted for measurement error
- Advantages
- Light on memory (they don’t need to keep any history other than the previous state)
- Very fast, making them well suited for real time problems and embedded systems
- Limitations
- If model states have extremely high dimensions, we have to store a large covariance matrix and conduct intense matrix multiplications.
- If some operator (that I didn’t understand) is nonlinear, then the covariance matrices can’t be calculated
- An ensemble kalman filter gets around this by using Monte-Carlo simulation
- Use cases
- Engineering: common for reducing noise from sensor signals (i.e. smoothing out measurements)
- Detection-based object tracking (computer vision)
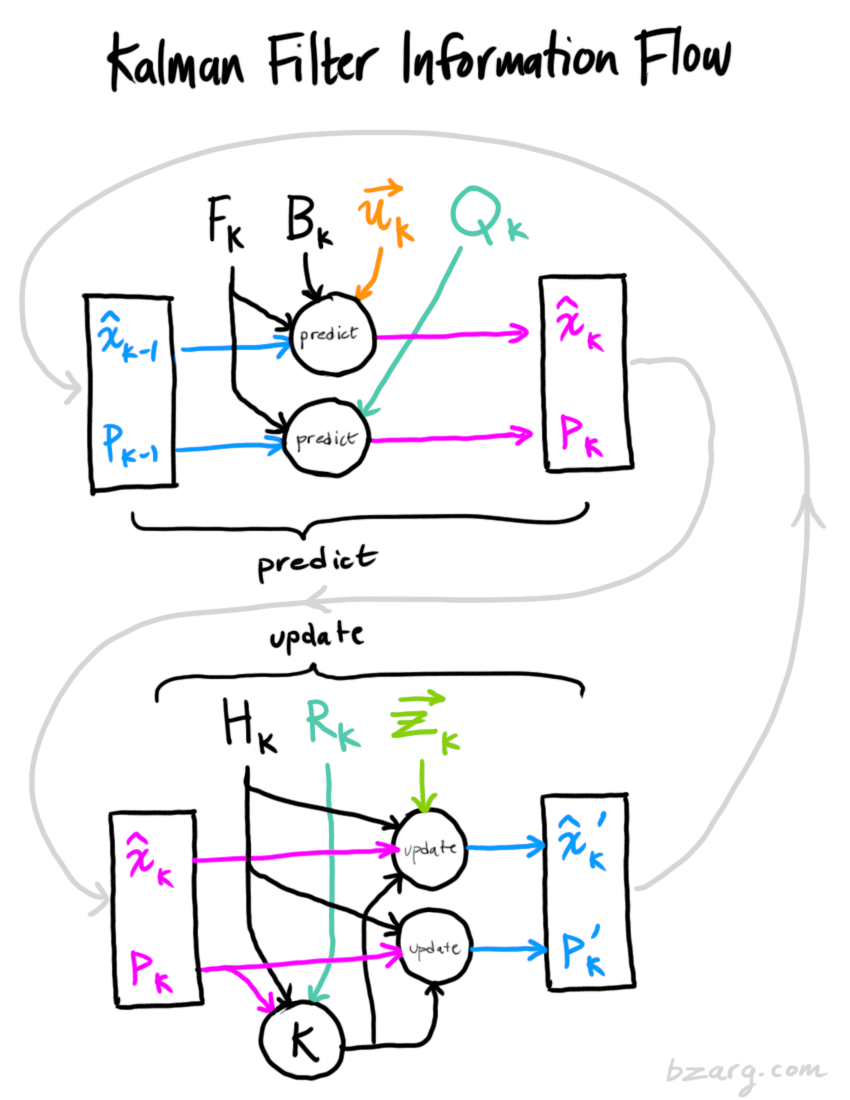
First set of equations
.png)
- Notes
- This set of equations deals physical part of the system. It’s kinda how we typically forecast.
- The \(\hat x_k\) equation is pretty much like a typical auto-regression plus explanatory variables except for the F matrix which may require knowledge of system dynamics
- Wiki shows a term, \(w_k\), added to the end of the \(\hat x_k\) equation. \(w_k\) is the process noise and is assumed to be drawn from a zero mean multivariate normal distribution,
- This set of equations deals physical part of the system. It’s kinda how we typically forecast.
- The new best estimate is a prediction made from previous best estimate, plus a correction for known external influences.
- \(\hat x_k\): The step-ahead predicted “state”; \(\hat x_{k-1}\) is the current “state”
- \(u_k\) (“control” vector): An explanatory variable(s)
- \(F_k\) (“prediction” matrix) and \(B_k\) (“control” matrix) are transformation matrices
- \(F_k\) was based on one of Galileo’s equations of motion in the example so this might be very context specific
- Might need to based on substantial knowledge of the system to create a system of linear equations (i.e. \(F_k\) matrix) that can be used to model the it.
- And the new uncertainty is predicted from the old uncertainty, with some additional uncertainty from the environment.
- \(P_k\) and \(P_{k-1}\) are variance/covariance matrices for the step-ahead predicted state and current state respectively
- \(Q_k\) is the uncertainty term for the variance/covariance matrix of the predicted state distribution
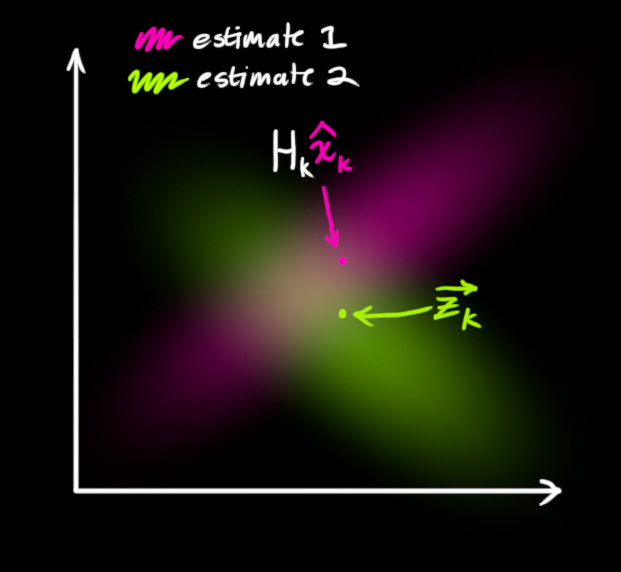
Second Set of Equations
.png)
- Notes
- These equations refine the prediction of the first set of equations by taking into account various sources of measurement error in the observed outcome variable
- The equations do this by finding the intersection, which is itself a distribution, of the transformed prediction distribution, \(μ_0\), and the measurement distribution, \(μ_1\).
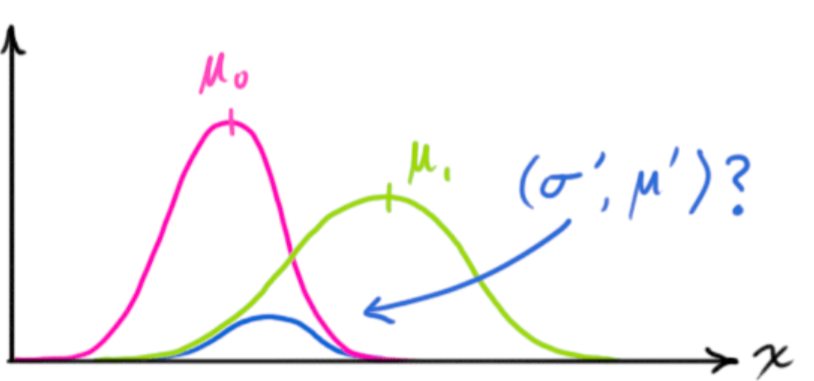
- This mean, \(\mu'\), of this intersection distribution is the predicted value that most likely to be the true value
- \(H_k\) is a transformation matrix that maps the predicted state (result of the first set of equations), \(\hat x_k\) , to the measurement space
- Where \(H_k \cdot \hat x_k\) is the expected measurement (pink area) (i.e. Mean of the distribution of transformed prediction)
- \(\vec z_k\) is the mean of the measurement distribution (green area)
- \(\hat x_k'\) is the intersection of the transformed prediction distribution and the measurement distribution (i.e. the predicted state thats most likely to true)
- \(R_k\) is the uncertainty term for variance/covariance matrix for the measurement distribution
- \(K'\) is called the Kalman Gain
- Didn’t read anything interpretative about the value. Just seems to a mathematical construct that’s part of the derivation.
- In the derivation, it starts out as the ratio of the measurement covariance matrix to the sum of the measurement variance covariance matrix and the transformed prediction variance covariance matrix
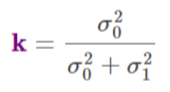
Process
Hyperparameters
- \(Q\) is the process noise covariance
- Controls how sensitive the model will be to process noise.
- \(R\) is the measurement noise variance
- Controls how quickly the model adapts to changes in the hidden state.
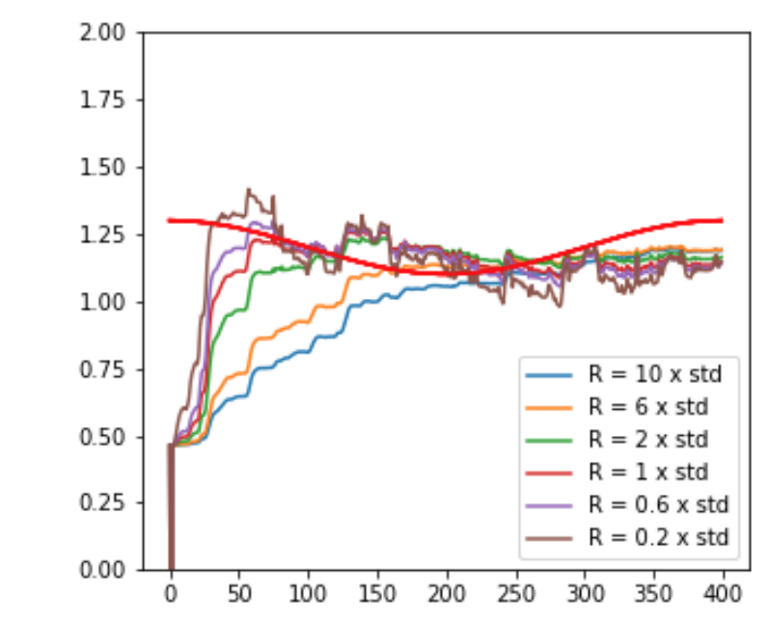
- Guessing “std” is the default value?
- Controls how quickly the model adapts to changes in the hidden state.
Exponential Smoothing
- The general idea is that future values are a weighted average of past values, with the weights decaying exponentially as we go back in time
- Methods
- Simple Exponential Smoothing
- double Exponential Smoothing or Holt’s Method (for time series with a trend)
- Triple Exponential Smoothing or Holt-Winter’s method (for time series with a trend and sesaonality)
TBATS
- Trigonometric seasonality, Box-Cox transformation, ARMA errors, Trend, and Seasonal components
- Can treat non-linear data, solve the autocorrelation problem in residuals since it uses an ARMA model, and it can take into account multiple seasonal periods
- Represents each seasonal period as a trigonometric representation based on Fourier series. This allows the model to fit large seasonal periods and non-integer seasonal periods
Interval Forecasting
- Notes from Video: ISF 2021 Keynote
- Papers
- Interval data is commonly analyzed by modeling the range (difference between interval points)
- Range data doesn’t provide information about the variation of the mean (aka level) over time.
- Range only provides information about the boundaries, where interval analysis provides information about the boundary and the interior of the interval.
- Provides more information than point forecasts.
- Data examples:
- Daily Temperature, Stock Prices: Each day a high and low values are recorded
- Stock Price Volatility, Bid-Ask spread use hi-lo value differences
- Intra-House Inequality: difference between wife and husband earnings
- Urban-Rural income gap
- Interval-Valued Output Growth Rate: China reports it’s targeted growth rate as a range now.
- Diastolic and Systolic blood pressure
- Others: Blood Lipid, White Blood Cell Count, Hemoglobin
- Examples where (generalized) intervals can be modeled instead of differences:
- Stock Volatility
- GARCH models often used to model volitility but Conditional Autoregressive Range (CARR) gives better forecasts
- Because GARCH model is only based on the closing price but the CARR model uses the range (difference).
- Dynamic Interval Modeling
- Use Autoregressive Interval (ARI) model to estimate the parameters using an interval time series (not the range)
- Then take the forecasted left and right values of the interval to forecast the volatility range in a CARR model
- The extra information of the interval data over time (instead of a daily range) yields a more efficient estimation of the parameters
- GARCH models often used to model volitility but Conditional Autoregressive Range (CARR) gives better forecasts
- Capital Asset Pricing Model (CAPM)
Also see Finance, Valuation >> Cost of Capital >> WACC >> Cost of Equity
Standard Equation
\[ R_t - R_{ft} = \alpha + β(R_{mt} - R_{ft}) + \epsilon_t \]
- \(R_t\): Return of Certain Portfolio
- \(R_{ft}\): Risk-Free Interest Fate
- \(R_{mt}\): Return of Market Portfolio
- \(R_t - R_{ft}\): Asset Risk Premium
Interval-based version
\[ Y_t = (\alpha_0 + \beta_0I_0) + \beta X_t + u_t \]
- \(I_0 = [-0.5, 0.5]\)
- \(Y_t = [R_{ft}, R_t]\)
- \(X_t = [R_{ft}, R_{mt}]\)
- The \(R_t - R_{ft}\) can then be calculated by taking the difference of the interval bounds of the interval-based predictions
- Stock Volatility
- Model the center of the interval and the range in a bi-variate VAR model (doesn’t use all points in the interval data)
- Bi-variate Nonlinear Autoregressive Model for center and range
- Has an indicator variable that captures nonlinearity of interval data
- Space-time autoregressive model
- Bi-variate Nonlinear Autoregressive Model for center and range
- Autoregressive Conditional Interval model
The interval version of an ARMA model
- depends on lags and lagged residuals
ACI(p,q):
\[ Y_t = (\alpha_0 + \beta_0 I_0) + \sum_{j=`}^p \beta_jY_{t-j} + \sum_{j=1}^p \gamma_ju_{t-j} + u_t \]
- \(\alpha_0\), \(\beta_0\), \(\beta_j\), \(\gamma_j\) are unknown scalar parameters
- \(I_0 = [-\frac{1}{2},\; \frac{1}{2}]\) is a unit interval
- \(\alpha_0 + \beta_0I_0 = [\frac{\alpha_0 - \beta_0}{2},\: \frac{\alpha_0 + \beta_0}{2}]\) is a constant interval intercept
- \(u_t\) is the interval residuals that satisfies \(\mathbb{E}(u_t\;|\;I_{t-1}) = [0,0]\)
- \(Y_t\) is a random interval variable
Objective function that gets minimized is called \(D_k\) distance
- \(D^2_K [u_t(\theta),0]\)
- \(u_t(\theta)\) is the interval residuals
- \(K\) refers to some kind of kernel function
- It’s a wacky quadratic with constants a,b,c
- Measures the distance between all pairs of points
- The minimization is a two-stage process
- Finds the optimal kernel, \(K\), then uses it to minimize the residuals to estimate the parameters
- \(D^2_K [u_t(\theta),0]\)
- Threshold Autoregressive Interval (TARI)
- Nonlinear ACI model and interval version of TAR(p) model (¯\_(ツ)_/¯)
- 2-Procedure Model
- Basically 2 autoregressive equations with an \(i_1u_t\) or \(i_2u_t\) added on to the end.
- The interval series, \(Y_t\) ,follows one of the equations based on threshold variable \(q_t\) is less than or equal to a threshold parameter, \(\gamma\) or greater than.
- Estimation is similar to ACI model
- For more details, need to research what a TAR model (Terasvirta, Tjostheim, and Granger 2010) is
Count Forecasting
- Misc
- Packages
- {tscount} - Poisson and Negative Binomial likelihood-based methods for model fitting and assessment, prediction, and intervention analysis of count time series following generalized linear models.
- {ZIHINAR1} - Provides tools for estimating Zero-Inflated INAR(1) (ZI-INAR(1)) and Hurdle INAR(1) (H-INAR(1)) models using ‘Stan’
- {ZINARp} - Simulation, exploratory data analysis and Bayesian analysis of the parametric, p-order Integer-valued Autoregressive (INAR(p)) and Zero-inflated p-order Integer-valued Autoregressive (ZINAR(p)) processes with Poisson or zero-inflated Poisson likelihoods.
- {spINAR} (JOSS) - Procedures for simulation, estimation, and bootstrapping INAR models within parametric and semiparametric setups.
- Packages
- Integer-Valued Autoregressive Models (INAR)
- \(\mbox{INAR}(p)\) is an analog to an \(\mbox{AR}(p)\) model
\[ \begin{aligned} &Y_t = \alpha_1 Y_{t-1} + \alpha_2 Y_{t-2} + \cdots + \alpha_p Y_{t-p} + \epsilon_t \\ &\begin{aligned} \text{with} \; &\epsilon \overset{\text{iid}}{\sim} G \;\text{and}\; G \in \mathbb{N}_0 = \{0,1,2,\ldots\} \\ &\alpha_i \in (0,1) \;\text{and}\; \sum_{i=1}^p \alpha_i < 1 \end{aligned} \end{aligned} \] - Binomial Thinning, where \(\circ\) is the binomial thinning operator
\[ \alpha_i \circ Y_{t-i} = \sum_{j=1}^{Y_{t-i}} Z_j^{(t,i)} \;\text{and}\; Z_j^{(t,i)} \sim \mbox{Binomial}(1, \alpha_i) \]
- \(\mbox{INAR}(p)\) is an analog to an \(\mbox{AR}(p)\) model