Stochastic Processes
Misc
- Notes from
- Packages
- {msm} - Multi-State Markov and Hidden Markov Models in Continuous Time
- Also see ebook below
- {msm} - Multi-State Markov and Hidden Markov Models in Continuous Time
- Resources
Terms
- Brownian Motion - A continuous process such that its increments for any time scale are drawn from a normal distribution
- Communication Class - consists a set of states that all communicate with one another (e.g. A must be reachable from B and B reachable from A)
- Irreducible - A Markov chain is irreducible if it consists of a single communication class otherwise it’s Reducible
- Limiting Distribution (aka Invariant Distribution) - Describes the long-term probability of being in any state, as well as the proportion of time spent in that state.
\[ \Pi = \begin{matrix} \pi_0 & \pi_1 & \pi_2 \\ \pi_0 & \pi_1 & \pi_2 \\ \pi_0 & \pi_1 & \pi_2 \end{matrix} \]This is like a asymptotic State Probability Distribution or a \(\infty\)-step State Probability Distribution
Can be calc’d by raising a transition matrix to a very large power
matrixpower(printers, 100) #> [,0] [,1] [,2] #> [0,] 0.5882353 0.2941176 0.1176471 #> [1,] 0.5882353 0.2941176 0.1176471 #> [2,] 0.5882353 0.2941176 0.1176471
- Markov Property - A system or variable is said to be Markov when knowing the current state of the process is just as good as knowing the entire history.
- Markov processes are said to be ‘memoryless’ because the history of their states is irrelevant.
- Recurrent States - States that have an infinite number of expected visits
- Absorbing State (Boundary) - (special recurrent case) States that only communicate with themselves. A state in which once it’s entered, you can never leave
- State Probability Distribution - Distribution of the Markov variable \(X_t\) at time, \(t\), and it is denoted by \(\pi_t\)
Notation for \(n\)-states at time, \(t\) (or “step” \(t\) is the same thing)
\[ \pi_t = [P(X_t = 1), P(X_t = 2), P(X_t = 3), \ldots, P(X_t = n)] \]Each element of \(\pi_t\) can be referenced using the notation
\[ \begin{align} &\pi_t = [\pi_{1t}, \pi_{2t}, \pi_{3t}, \ldots, \pi_{jt}, \ldots, \pi_{nt}]\\ &\text{where} \;\; \pi_{jt} = P(X_t = j) \end{align} \]- The sum of \(\pi_{jt}=1\), so that says that the sum of the probabilities for all the states at a given time step must be 1.
- Note that each row in a transition matrix sums to 1.
- The sum of \(\pi_{jt}=1\), so that says that the sum of the probabilities for all the states at a given time step must be 1.
- Transient States - States that have a finite number of expected visits
- Examples:
- State 0 (above) - If state 0 is the starting point, then after the 1st transition, it is no longer a potential destination
- States 1,2,3 (Drunkard below) - Small values or zeros in the limiting distribution
- Examples:
- Transition Matrix
- Row index represents the initial or source state at time \(t\)
- Column index represents the destination state at time (\(t+n\))
- Each Cell is the probability that by starting in source state, \(i\), you end-up in destinations state, \(j\) after \(n\)-steps/time
Transitions
Steps and Time Steps are interchangable in terms of transition matrices, e.g. step n+2 and time, t+2, state probability distributions, etc.
1-Step Transition Matrix
- Example:
Y-Axis - Probabilities of starting with an initial state (e.g. # of printers broken at the beginning of the day)
X-Axis - Probabilities of transitioning to the final (for a 1-step) state (e.g. # of printers broken at the end of that day which will be the initial state of the following day)
\[ \begin{matrix} & 0 & 1 & 2 \\ 0 & 0.7 & 0.3 & 0 \\ 1 & 0.2 & 0.4 & 0.4 \\ 2 & 1 & 0 & 0 \end{matrix} \]- (0,0) says there’s a 70% probability if you start the day with 0 printers broken, then you’ll end the day with 0 printers broken.
- (1,2) says there’s a 40% probability if you start the day with 1 printer broken, then you’ll end the day with 2 printers broken.
- (2,1) says there’s a 100% probability if you start the day with 2 printers broken, then you’ll end the day with 0 printers broken.
- e.g. A repairman is contractually obligated to show up and fix or replace both printers by the end of the day if they break on the same day.
- Example:
2-Step Transition Matrix
- Example: Same scenario as above but there are two steps (2-day interval) in which the transition is from State 0 to State 1, (0,1).
To do that we would need to sum all possible two-step transitions that start at State 0 and end-up in State 1.
\[ \begin{align} \text{Transition}_{\text{2-step}} &= \begin{aligned}[t] &P(X_{n-1} = 0|X_{n-2} = 0) \cdot P(X_n = 1|X_{n-1} = 0) \\ &+ P(X_{n-1} = 1|X_{n-2} = 0) \cdot P(X_n = 1|X_{n-1} = 1) \\ &+ P(X_{n-1} = 2|X_{n-2} = 0) \cdot P(X_n = 1|X_{n-1} = 2) \end{aligned}\\ &= (0.7 \cdot 0.2) + (0.3 \cdot 0.4) + (0 \cdot 0) = 0.33 \end{align} \]First potential 2-step transition says:
- 1st step - The probability of moving to State 0 (\(n-1\)) given you were in State 0 (\(n-2\))
- 2nd step - the probability of moving to State 1 (\(n\)) given you were in State 0 (\(n-1\))
For this example, each 2 step transition will be of the form \(p(x|0) \cdot p(1|x)\)
In general, the probability that the Markov chain will be in State \(j\) at Step \(n\), given that it was in State \(i\) at (\(n-1\))
\[ P_{ij}(X_n = j | X_{n-1} = i) \]
- Example: Same scenario as above but there are two steps (2-day interval) in which the transition is from State 0 to State 1, (0,1).
N-step (in general)
\[ \pi_t = \pi_0 P^t \]
Where
- \(P\) is the trasition matrix and \(t\) is the step (\(t\) is for time step instead of \(N\))
- \(\pi_0\) is like a prior probability vector for each state at \(t = 0\)
- This prior gives us the probabilities for which state we’ll likely start out at.
A little different from other the calculations in the Transitions section. Here \(t\)-step transition matrix is multiplied times a prior
matrixpower(user-defined) performs this calculation for all \(n\)-step transitionsmatrixpower <- function(mat,k) { if (k == 0) return (diag(dim(mat)[1])) # 3x3 identity matrix if (k == 1) return(mat) if (k > 1) return(mat %*% matrixpower(mat, k-1)) } printers <- matrix(c(.7, .2, 1, .3, .4, 0, 0, .4, 0), nrow = 3, ncol = 3) printers #> [,0] [,1] [,2] #> [0,] 0.7 0.3 0.0 #> [1,] 0.2 0.4 0.4 #> [2,] 1.0 0.0 0.0 # 2-step matrixpower(printers, 2) #> [,0] [,1] [,2] #> [0,] 0.55 0.33 0.12 #> [1,] 0.62 0.22 0.16 #> [2,] 0.70 0.30 0.00 # 3-step matrixpower(printers, 3) #> [,0] [,1] [,2] #> [0,] 0.571 0.297 0.132 #> [1,] 0.638 0.274 0.088 #> [2,] 0.550 0.330 0.120- This is just matrix exponentiation and multiplying the square (based on row dim) identity matrix at the end for some reason (probably makes a diff for non-square matrices)
matrixpoweris from Introduction to Stochastic Processes with R by Robert Dobrow- In the 2-step transition output, 0.33 at (0,1) matches the manual calculation above
- There’s a manual change to start indexing from 0, as that’s the typical way of indexing matrices for stochastic processes. R indexing typically starts from 1.
Communication
Communication
- Definition
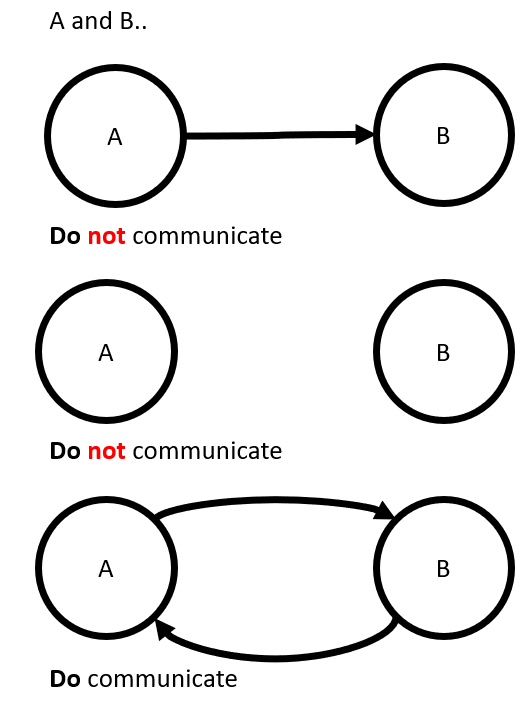
- Definition
Classes
- States in Class \(X\) can communicate (i.e. transition to one another) but Class \(X\) members do not communicate with members of Class \(Y\)
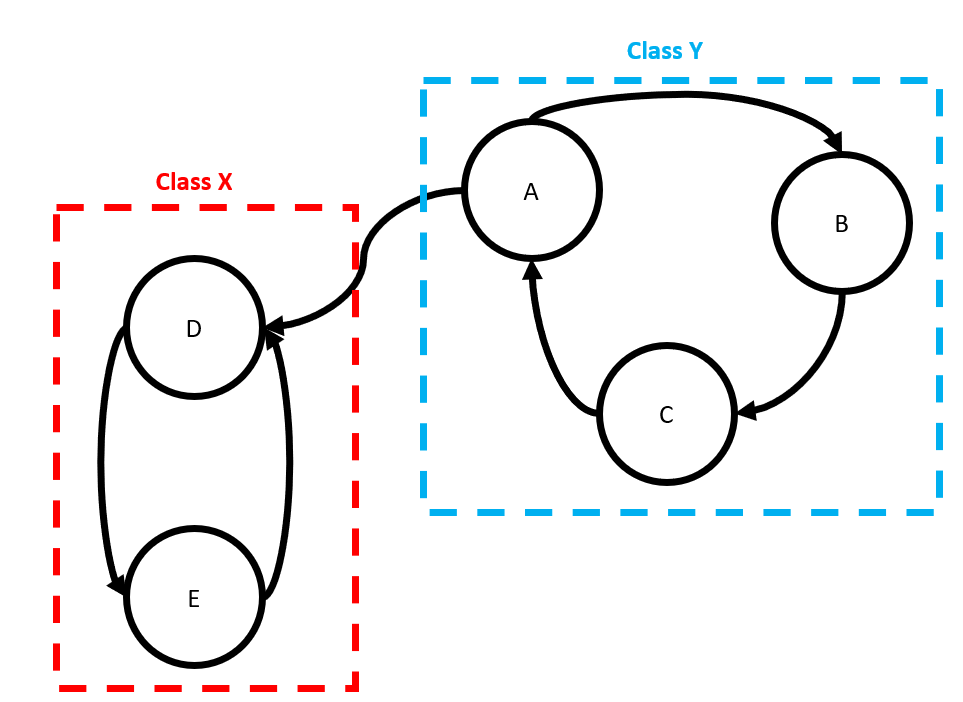
- States in Class \(X\) can communicate (i.e. transition to one another) but Class \(X\) members do not communicate with members of Class \(Y\)
Reducibility
- Irreducible - A Markov chain is irreducible if it consists of a single communication class otherwise it’s reducible.
Example
reducible <- matrix(c(0, 0, 0, 0, 0, .4, .9, .7, 0, 0, 0, .1, .3, 0, 0, .6, 0, 0, .5, .5, 0, 0, 0, .5, .5), nrow = 5, ncol = 5) reducible #> [,0] [,1] [,2] [,3] [,4] #> [0,] 0 0.4 0.0 0.6 0.0 #> [1,] 0 0.9 0.1 0.0 0.0 #> [2,] 0 0.7 0.3 0.0 0.0 #> [3,] 0 0.0 0.0 0.5 0.5 #> [4,] 0 0.0 0.0 0.5 0.5 matrixpower(reducible, 100) #> [,0] [,1] [,2] [,3] [,4] #> [0,] 0 0.350 0.050 0.3 0.3 #> [1,] 0 0.875 0.125 0.0 0.0 #> [2,] 0 0.875 0.125 0.0 0.0 #> [3,] 0 0.000 0.000 0.5 0.5 #> [4,] 0 0.000 0.000 0.5 0.52 Communication Classes
- Loop with States 1 and 2 (see rows 1 and 2)
- Loop with States 3 and 4 (see rows 3 and 4)
Starting at state 0,
- You can transition to either of the 2 classes through State 1 or State 3, but never return to State 0 (i.e. State 0 isn’t part of a class).
Starting in States 1 or 2, you remain in that class indefinitely
Starting in States 3 or 4, you remain in that class indefinitely
- Irreducible - A Markov chain is irreducible if it consists of a single communication class otherwise it’s reducible.
Limiting Distributions
- For a Reducible Chain
- Some or all the values for a column will be different
- Some or all the rows will be different
- The values are different because the starting state matters
- For an Irreducible Chain:
- Each column will have the (essentially) the same value in each row
- Each row will be identical
- The values are the same because the starting state doesn’t matter
- Note that in the example above that each state can (eventually) be reached from State 0.
- For a Reducible Chain
Random Walk
- Transient, Recurrent, and Absorbing States
Example: Drunkard that either makes it home (state 4) or the ocean (state 0)
random_walk <- matrix(c(1, .5, 0, 0, 0, 0, 0, .5, 0, 0, 0, .5, 0, .5, 0, 0, 0, .5, 0, 0, 0, 0, 0, .5, 1), nrow = 5, ncol = 5) #> [,0] [,1] [,2] [,3] [,4] #> [0,] 1.0 0.0 0.0 0.0 0.0 #> [1,] 0.5 0.0 0.5 0.0 0.0 #> [2,] 0.0 0.5 0.0 0.5 0.0 #> [3,] 0.0 0.0 0.5 0.0 0.5 #> [4,] 0.0 0.0 0.0 0.0 1.0 matrixpower(random_walk, 100) #> [,0] [,1] [,2] [,3] [,4] #> [0,] 1.00 0.000000e+00 0.000000e+00 0.000000e+00 0.00 #> [1,] 0.75 4.440892e-16 0.000000e+00 4.440892e-16 0.25 #> [2,] 0.50 0.000000e+00 8.881784e-16 0.000000e+00 0.50 #> [3,] 0.25 4.440892e-16 0.000000e+00 4.440892e-16 0.75 #> [4,] 0.00 0.000000e+00 0.000000e+00 0.000000e+00 1.00- States 0, 4 are absorbing states and states 1,2,3 are transient
- Eventually through probability, there must be a transition to states 0 or 4 where it’s impossible to leave. Therefore the number of visits to 1,2,3 will be finite and by definition, they are transient.
- Limiting distribution - notice the middle states have either very small numbers or zero values, this is a property of transient states.
Hidden Markov Models (HMM)
Misc
- {autoregressivehmm} (Paper) - Fitting HMMs with within-state autoregression in the state-dependent process as well as simulating data from said models.
- {BCT} - Bayesian Context Trees for Discrete Time Series
- Models the posterior distribution over variable-memory Markov models and parameters, allowing for exact Bayesian inference.
- Forecasting is achieved by averaging predictions over all possible models, weighted by their posterior probabilities.
- Functions for prediction, model selection, estimation, segmentation/change-point detection
- Still effective when training sets are small by efficiently using Bayesian model averaging
- Capable of online learning
- {dtms} (Papers) - Discrete-Time Multistate Models
- Tools for processing data, several ways of estimating parametric and nonparametric multistate models, and an extensive set of Markov chain methods which use transition probabilities derived from the multistate model
- {hdMTD} (Paper) - An R Package for High-Dimensional Mixture Transition Distribution Models
- A mixture transition distribution (MTD) model is a subclass of finite-order Markov chains and a parsimonious non-parametric model for categorical time series
- The MTD framework successfully reduces the number of parameters required for estimation, alleviating the complexity associated with high-order dependencies (i.e. long term dependencies, i.e. number of lags?).
- Has a few different methods to find how many relevant lags there are. Then, computes the maximum likelihood estimate (MLE) of the transition probabilities and estimate high-order MTD parameters using the expectation-maximization (EM) algorithm.
- Example uses temperature data that has been categorized into binary data
- {HiddenMarkovModels} - A Julia package for simulation, inference and learning of Hidden Markov Models with discrete states and discrete time.
- {LaMa} (Paper) - Fast numerical maximum likelihood estimation for a variety of latent Markov models, including hidden Markov models, hidden semi-Markov models, state-space models and continuous-time variants
- Provides easy-to-use C++ functions
- Allows you to roll-your-own HMMs. Offers plenty of vignettes for various HMM types
- {MSTest} (Github, Vignette) - Hypothesis Testing for Markov Switching Models that can be used to identify regimes
- Includes model estimation procedures
- Includes datasets and functions that can be used to simulate: autoregressive, vector autoregressive, Markov switching autoregressive, and Markov switching vector autoregressive processes among others
- {MSwM} - Estimation (EM method), inference and diagnostics for Univariate Autoregressive Markov Switching Models for Linear and Generalized Models.
- Distributions for the series include gaussian, Poisson, binomial and gamma cases. The EM algorithm
- {presmoothedTP} - Nonparametric presmoothed estimates of transition probabilities based on logistic, probit, and cauchit distributions
- Package built with survival data applications in mind, but I didn’t see anything that would prevent it being used in other subject areas.
- Notes from A Math Lovers Guide to Hidden Markov Models
- Used to study phenomena in which only a portion of the phenomenon can be directly observed while the rest of it cannot be directly observed, although its effect can be felt on what is observed. The effect of the unobserved portion (“hidden”) can only be estimated.
- Observed portion is modeled using arima, glm, rf, etc.
- Unobserved portion is modeled using Markov process
- Sort of like a latent variable that’s values are states (aka regimes)
- The two models produce a final prediction by calculating an expected value at each step that uses predictions from observed model and probabilities from the unobserved model.
- Use Cases
- Studying human workflows using computer event logs. Part of that is taking a user’s raw event log (keystrokes, URLs visited, etc.) and determining what they were doing at each time (background research, document review, etc.). Sometimes you can guess from one event in isolation, but usually you also need to look at the events before and after to have confidence.
- You have a photograph of a page from a novel, and you want to digitize the text. The photograph is already segmented into images of words. Most of them can be decoded with OCR, but some words are ambiguous because of dirt on the original page (is that “quick” or “quack”?). You want to use the surrounding words to pick the best option.
- You have a sequence of brain scans, taken every second while a person was playing a video game. During the game their avatar moves in and out of buildings, and your goal is to guess whether it is inside or outside using only the brain scans. Any given scan is very ambiguous, but the avatar usually stays inside/outside for many seconds at a time. You expect large spans of time where the avatar is in(out)side, and where the brain scans look slightly more in(out)side on average.
- Components
- An underlying markov chain that describes how likely you are to transition between different states (or stay in the same state). Typically this underlying state is the thing that you’re really interested in. If there are \(k\) states in the HMM then the markov chain consists of:
- \(k\times k\) transition matrix saying how likely you are to transition from a State \(S_a\) to a State \(S_b\)
- \(k\)-length vector saying how likely you are to start off in each of the states.
- A probability model that lets you compute \(Pr[O|S]\) — the probability of seeing observation \(O\) if we assume that the underlying State is \(S\).
- Unlike the markov chain, which has a fixed format, the model for \(Pr[O|S]\) can be arbitrarily complex. In many HMMs though \(Pr[O|S]\) is pretty simple: each State \(S\) is a different loaded die, and the \(Pr[O|S]\) are its probabilities of landing on each side.
- An underlying markov chain that describes how likely you are to transition between different states (or stay in the same state). Typically this underlying state is the thing that you’re really interested in. If there are \(k\) states in the HMM then the markov chain consists of:
- Baum-Welch algorithm
- Specific case of the EM algorithm
- As with the EM algorithm, solutions are only locally optimal
- Meaning you’re results will vary for each model you run (i.e. a non-convex problem)
- As with the EM algorithm, solutions are only locally optimal
- Step summary
- Guess at what the state labels are and train an HMM using those guesses
- The guess is usually about the parameters of the HMM and not actually the states.
- Typically random values from a dirichlet distribution
- The guess is usually about the parameters of the HMM and not actually the states.
- Use the trained HMM to make better guesses at the states, and re-train the HMM on those better guesses
- Uses the Forward-Backward Algorithm
- Continue process until the trained HMM stabilizes.
- Guess at what the state labels are and train an HMM using those guesses
- Forward-Backward Algorithm
- Find the most likely state for each timestep
- Unlike the Viterbi algorithm which computes the mostly likely sequence of states
- In practice, both algorithms only disagree about 5% of the time
- Unlike the Viterbi algorithm which computes the mostly likely sequence of states
- Find the most likely state for each timestep
- Specific case of the EM algorithm
- Mitigating the local optimum issue
- You can simplify your HMM.
- The number of local optima can grow exponentially with the number of parameters in your HMM. If you reduce the parameter size you can reduce the number of local optima there are to fall into.
- Examples
- Using a 2-state rather than a 3-state HMM.
- If your target is multinomial, collapse categories so that the cardinality is smaller.
- Examples
- The number of local optima can grow exponentially with the number of parameters in your HMM. If you reduce the parameter size you can reduce the number of local optima there are to fall into.
- Use business logic or domain expertise to have an initial HMM that is similar to what you expect the ultimate outcome to be.
- Different local optima often have large qualitative differences between each other, so on a gross level the HMM you ultimately converge on is likely to resemble the one you started with.
- Do make sure to have your guess be partly random though — there could be several local optima that are consistent with your business intuitions, and if so you want to know about it.
- Me: Sounds like formulating a prior
- You can simplify your HMM.
Markov Switching Dynamic Regression (MSDR)
- HMM for times series which uses dynamic regression as the observed model.
- Notes from A Worm’s Eye-View of the Markov Switching Dynamic Regression Model
- Basic formula for each time step, \(t\)
\[ y_t = \hat \mu_{tj} + \epsilon_t \quad \text{when} \;s_t = j \]- \(\hat \mu_{tj}\): final prediction for time step, \(t\)
- The j subscript is just saying that the hidden state variable st is part of the final prediction
- \(s_t\): hidden random variable that’s made-up of states (aka regimes) and helps determine the final prediction, \(\hat \mu\)
- Theoretically, a change in value of \(s_t\) impacts the distributional parameters (e.g. mean, variance) of the observed variable, \(y_t\)
- \(s_t\) is “hidden” because we do not know exactly when it changes its regime.
- If we knew which regime was in effect at each time step, we could simply make st a predictor variable.
- Poisson
\[ \hat \mu_{tj} = e^{x_t \cdot \hat\beta_j} \]
- \(\hat \mu_{tj}\): final prediction for time step, \(t\)
- Process
- Fit and get predictions from a dynamic regression model
\[ \begin{bmatrix} \hat y_{t1} & \hat y_{t2} & \cdots &\hat y_{tk} \end{bmatrix} = \begin{bmatrix} 1 & x_{1t} & x_{2t} & \cdots & x_{mt} \end{bmatrix} \cdot \begin{bmatrix} \hat \beta_{01} & \cdots & \hat \beta_{0k} \\ \vdots & \ddots & \vdots \\ \hat \beta_{m1} & \cdots & \hat \beta_{mk} \end{bmatrix} \]- \(m\) predictor variables and \(k\) states (i.e. a complete set of parameters is estimated for each state at each time step)
- Get the final prediction for time step, \(t\), by calculating the expected value
\[ \hat \mu_t = \sum_{j=1}^k \hat y_{tj} \cdot P(s_t = j) \]- \(\hat y\) are the predictions from the observed model
- \(P(s_t = j)\) are the state probabilities
\[ \pi_t = [\pi_{t1} = P(s_t = 1),\; \pi_{t2} = P(s_t = 2)] \]- e.g. 2 -states
- Where each \(\pi_{tj}\) is a row of the transition matrix
- Uses Maximum Likelihood Estimation (MLE) or Expectation Maximization (EM) to maximize the joint probability density.
- Estimated parameters:
- Transition Matrix (for each time step)
- During estimation, cells are allowed to range from \(-\infty\) to \(\infty\), but after it’s completed, they’re normalized to \([0,1]\) (See link)
- Regression Coefficients (for each state)
- Unclear to me how you estimate multiple coefficients with the same data. Maybe the likelihood for a \(\beta\) is maximized for a given (estimated?) transition matrix.
- Residual Variance (for each state)
- Transition Matrix (for each time step)
- Example: Using MLE for a Gaussian distribution
\[ \begin{align} f(;y = y_t|X = x_t; \hat \beta_s) = &P(s_t = 1)\left(\frac{1}{\sigma\sqrt{2\pi}}e^{\frac{1}{2}(\frac{y_t - \hat \mu_{t1}}{\sigma})^2}\right) \\ &+ P(s_t = 2)\left(\frac{1}{\sigma\sqrt{2\pi}}e^{\frac{1}{2}(\frac{y_t - \hat \mu_{t2}}{\sigma})^2}\right) \\ &+ \;\; \cdots \\ &+ P(s_t = k)\left(\frac{1}{\sigma\sqrt{2\pi}}e^{\frac{1}{2}(\frac{y_t - \hat \mu_{tk}}{\sigma})^2}\right) \end{align} \] - Example: For a Poisson DGP
\[ P(y = y_t|\hat \mu_t) = \sum_{j=1}^k P(s_t = j) \frac{e^{\hat \mu_{tj}} \hat \mu_{tj}^{y_t}}{y_t !} \]
- Estimated parameters:
- Fit and get predictions from a dynamic regression model
- Example
- Description
- Dependent variable: Personal Consumption Expenditures % Change Month over Month (M-o-M)
- Independent variable: Consumer Sentiment index % Change Month over Month (M-o-M)
- Model Equation
\[ \begin{align} &\hat \mu_{tj} = \hat \beta_{0j} + \hat \beta_{1j} x_{1t} \\ &\begin{aligned} \text{where} \;\; &\hat \beta_s = \begin{bmatrix} \beta_{00} & \beta_{01} \\ \beta_{10} & \beta_{11} \end{bmatrix} \\ & \epsilon_{ti} \sim \mathcal{N}(0, \sigma_j^2) \end{aligned} \end{align} \]- 2-states
- Observed model is a linear regression
- Model Summary (Python)
.png)
- Transition Matrix probabilities have pvals and CIs
- \(p[0\rightarrow0]\) is cell \(p00\) and \(p[1\rightarrow0]\) is cell p10 in the transition matrix
- unknown_cell_values = (1 - known_cell_values) for each row
- Interpretation
- Variance of States vs Transition Probabilities
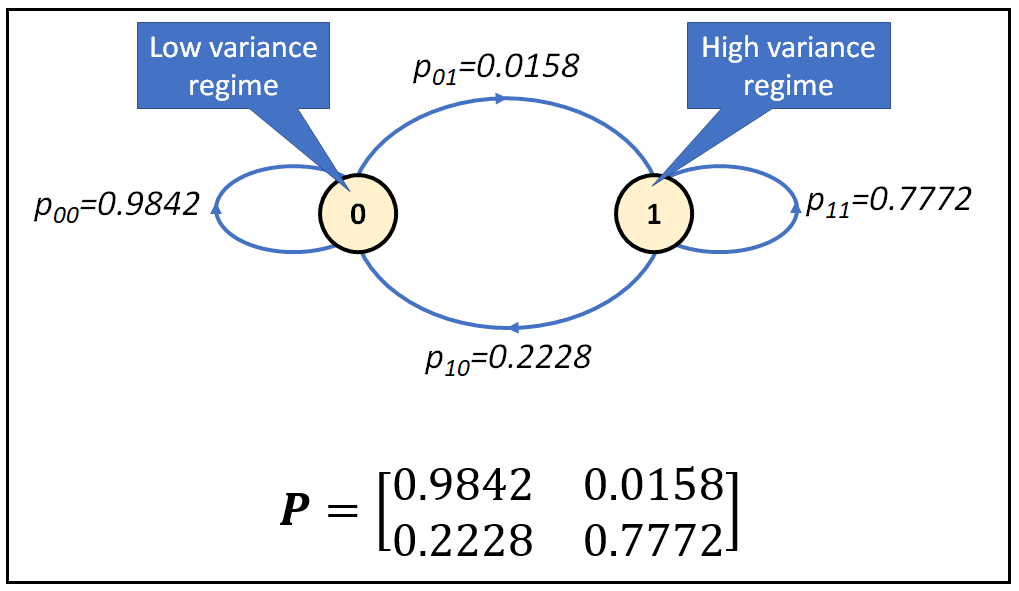
- When Personal Consumption Expenditures are in a low variance regime, they tend to switch to a high variance regime less than 2% of the time.
- When Personal Consumption Expenditures are in a high variance regime, they tend to switch to a low variance regime with roughly 20% probability.
- This variance is “sigma2” in the model summary in the Regime Parameters sections.
- Me: This would be the residual variance which is usually a GOF thing (i.e. variance of the points around the regression line). In finance, variance is a volatility measure and I guess this can be thought of in that way too. I guess it would the volatility around a trend line.
- Smoothed State Probabilities for each time step
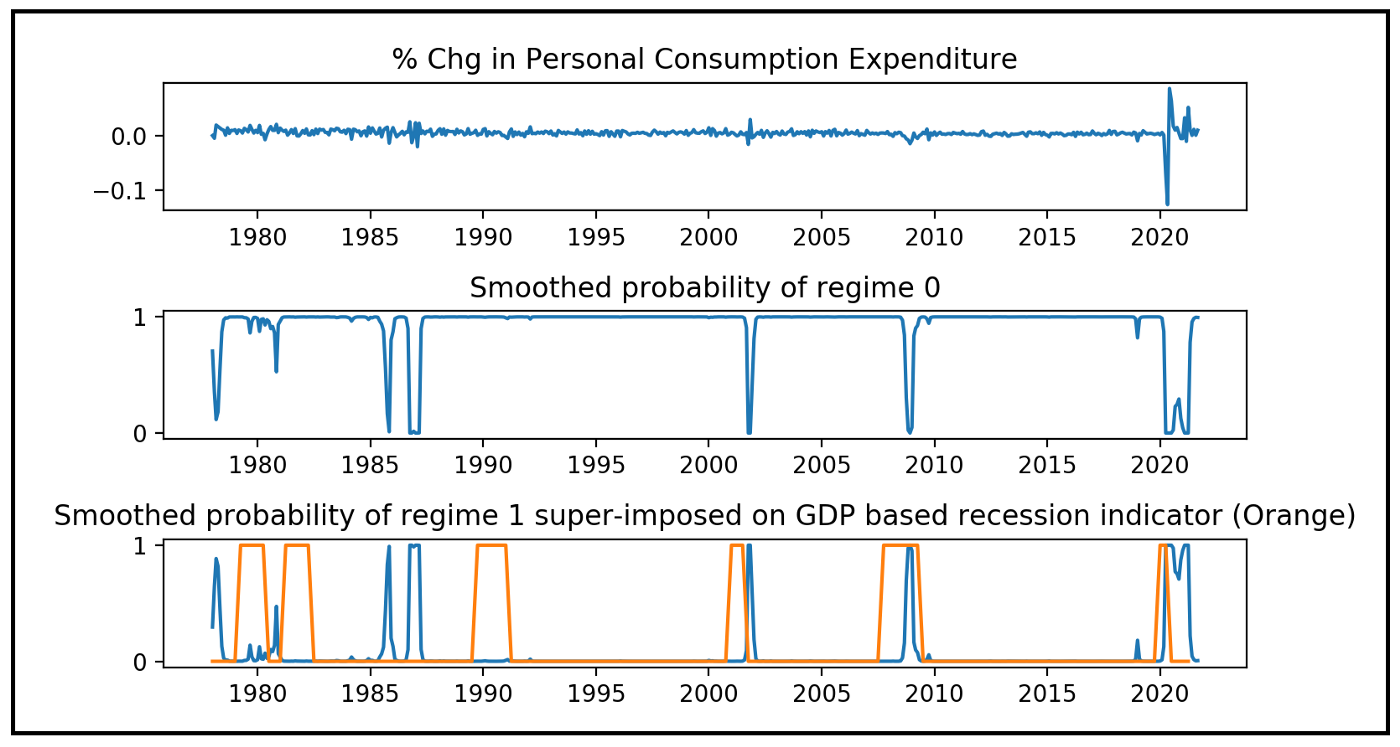
- Bottom two charts’ y-axes are probabilities, so chart 2’s dips in proability are when the hmm is in stage 1 (confirmed by looking at chart 3)
- Accessed via
msdr_model_results.smoothed_marginal_probabilities[0]([1] for state 1) - After 2000, we see that often the Markov state model is in the high variance state towards the end a recession. (bottom chart)
- Variance of States vs Transition Probabilities
- Description
Markov Switching Auto Regression (MSAR)
- Model Equation
\[ y_t = \hat \mu_{ts_t} + \hat \phi (y_{t-1} - \hat \mu_{(t-1)s_{t-1}}) + \epsilon_t \]- Adds a fraction of the residual from the previous step to the MSDR model
Monte Carlo Simulation
- A broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. (wiki)
- Misc
- Notes from
- An Introduction and Step-by-Step Guide to Monte Carlo Simulations
- Examples (1-3 below) in this article look exactly like bootstrapping to me.
- Tidy simulation: Designing robust, reproducible, and scalable Monte Carlo simulations (Github)
- An Introduction and Step-by-Step Guide to Monte Carlo Simulations
- Packages
- {switchboard} - Visualizes an animation of the simulation via a simple dashboard
- Papers
- Using simulation studies to evaluate statistical methods
- A tutorial that outlines the rationale for using simulation studies and offers detailed guidance for design, execution, analysis, reporting and presentation
- Using simulation studies to evaluate statistical methods
- The distribution you’re randomly sample from affects the stability of the simulated distributions you end up with.
- If you’re sampling from a source distribution with no variability, i.e. a constant value, then of course, you sampled distribution will completely stable with no variation.
- If you’re sampling from a source distribution with extreme differences between values (e.g. 0s for most days, then a spike of 50 on a few days), then you can expect your sampled distribution to have a large spread (i.e. large variance).
- Bootstrapping uses the original, initial sample as the population from which to resample, whereas Monte Carlo simulation is based on setting up a data generation process (with known values of the parameters of a known distribution). Where Monte Carlo is used to test drive estimators, bootstrap methods can be used to estimate the variability of a statistic and the shape of its sampling distribution
- Simulations are “in silico” experiments
- Notes from
- Questions
- Aims: What is the research question?
- Data-Generating Mechanism: How is the stochastic data generated?
- Estimand & Method: Which method do we apply to the generated data?
- Performance Measures: Which metric are we interested in comparing and presenting?
- Components
- Simulation Grid: A tidy data frame indicating the settings for each iteration of a simulation.
- Types of Variables: Data Generating and Analysis
- Variables (aka Factors)
- Discrete Values (e.g. sample size or the number of variables)
- Continuous Values (e.g. as standardized effect size or proportion of variation (R2))
- Categorical Values (e.g. distribution type or analysis method)
- For efficiency, encode categoricals as a categorical type (factor (R), categorical, or enum) and not as a string or character
- The iteration number should also be included in creating the simulation grid
- Enables partial results computation: a methodologist can start with computing 5 iterations of the full design by filtering the grid on the iteration number column, or by taking the first 1% of rows.
- Allows preliminary analyses to be done on a subset of the results table, supporting exploratory data analysis, with additional precision added later upon running and storing the remaining iterations.
- Since each row in the simulation grid should represent a single simulation according to the tidy data principles, the full factorial design should be stacked \(N\) times, where \(N\) is the number of iterations.
expand_gridfunctions can carry this out. - Many millions of rows are not uncommon in larger simulations, so storage of the grid in an efficient file format like parquet is recommended where packages with lazy exectuion (duckdb, polars) can be taken advantage of.
- For large grids, it could make sense to retain only the data generation factors in the simulation grid and to relegate the analysis factors to the results table directly
- Generation Function: Takes in parameters from the simulation grid and outputs a simulated dataset – ideally in a tidy format.
- The function is an explicit representation of the theoretical data-generating process. Typically produced using a random variable distribution function
- R: It’s built-in distribution functions, e.g.
rnorm - Python:
numpy.randomandscipy.stats - Julia: The Distributions.jl package
- A random seed should be supplied either globablly or via the Simulation Grid
- Analysis Function: Takes in a generated dataset (and any other output from the data generation function) along with arguments from the simulation grid, and produces the metrics or outcomes of interest which constitute a single row of the results table
- Needs even more attention towards robustness, as errors in statistical models might be probabilistic and data-dependent
- It is in the probabilistic nature of Monte Carlo simulations that even if these edge-cases are very unlikely to happen in any single generated dataset, they are highly likely to happen in the simulation as a whole
- Must be intimately aware of the limitations of the methods under study so that the data-generating process matches the analysis method.
- There should be extensive integration testing of both the data generation function and the analysis function together, for different settings of the simulation factors.
- Issues such as non-convergence or problematic fit can still remain, and even be deemed acceptable by the methodologist; it can be included as one of the outcomes in the simulation
- Results Table: A tidy data frame with one row per simulation setting in the simulation grid, and one or more columns containing the outcomes of interest.
- For Bayesian models, which may need to be inspected or processed further, additional information (convergence, mixing metrics) can be stored on disk with a unique filename, and the file path can be included as an output in the results table
- Choose structured column names, which indicate the analysis setting and the outcome value of interest, separated by strings which are easy to parse.
- Ensures being able to pivot between long and wide column formats
- Example: [outcome] [correction] [value], e.g. changescore_uncorrected_pvalue
- Simulation Grid: A tidy data frame indicating the settings for each iteration of a simulation.
- Optimizations
- Parallelization or distributed
- Writing to a database by inserting to a table after each iteration
- General Process
- Identify all input components of the process and how do they interact e.g., do they sum up or subtract?
- e.g. net benefit = variable benefit - variable cost 1 - variable cost 2
- Define parameters of the distributions.
- Sample from each of the distributions and plug the results based in the process describe by step 1.
- Repeat the process around 10K times or more
- Use the mean or median, etc as the point estimate with quantiles as the CIs. Use the ecdf to ask probabilistic questions.
- Identify all input components of the process and how do they interact e.g., do they sum up or subtract?
- Example 1: Forecast Manufactured Total Output for December
- Using a previous December’s output, you simulate how many total items will likely be produced this December.
- Previous December’s Daily Throughput
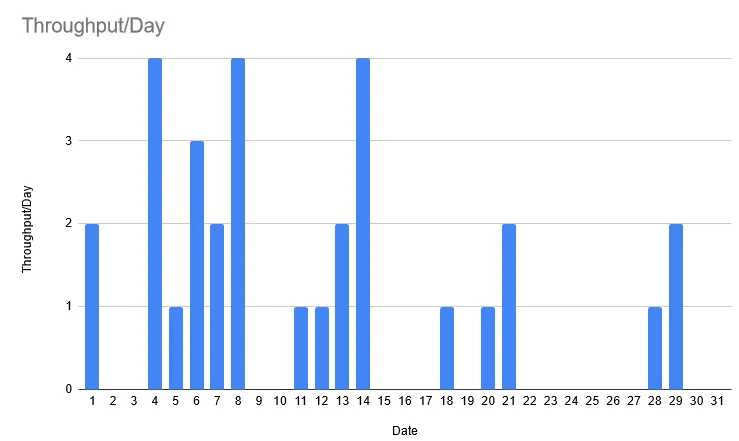
- “Throughput” is the number of items produced
- The throughput on December 4th was 4 items
- Process
- Randomly sample a day in December (1-31)
- On the selected day, record the previous December’s throughput on that day.
- Repeat 31 times
- Sum the 31 recorded throughput values to get the first simulated total throughput for December
- Record the simulated total throughput value
- Repeat around 10K times to get a distribution of total throughput values for December
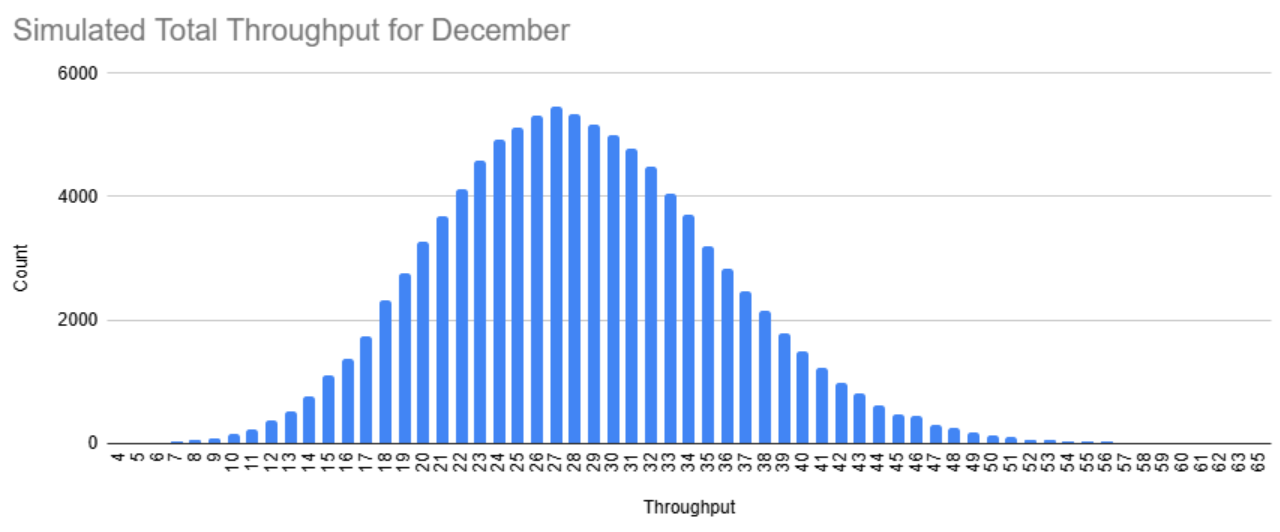
- This example sampled 100K times
- The mean/median of this distribution is your point forecast and quantiles are the CI.
- Example 2: What’s the probability of producing a certain amound of items or more?
- Create an ecdf using the simulated distribution counts
- Technically this should be prettey Normal. So, you could probably get the parameters and use the normal CDF for this.
- Manual Process
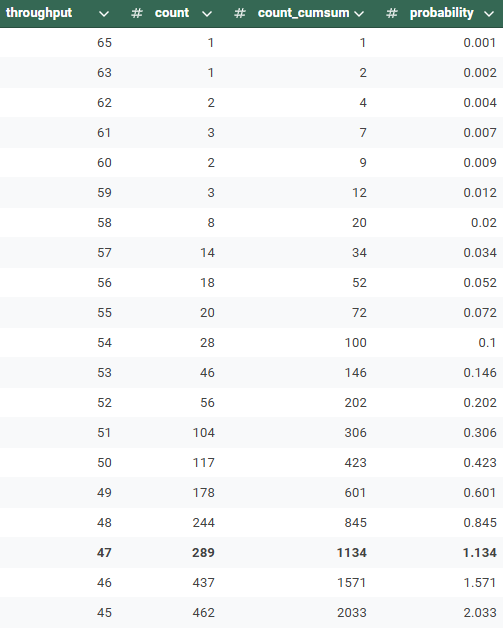
- Order distribution data by simulated total throughput (largest to smallest)
- Create a probability column by taking the cumsum of the counts and dividing by the total counts, which in this case is 100K since there were 100K simulations.
- There is a 1.134% percent chance that the total throughput for this December will be 47 items or greater. (i.e. this around the 99th quantile)
- Example 3: How long will it take to produce 28 items or more?
- Instead of randomly selecting days and their throughputs a fixed number of times (31 days previously), you only randomly select days until the desired throughput threshold has been reached which in this case is 28 items.
- Process
- Randomly sample a day in December (1-31)
- On the selected day, record the previous December’s throughput on that day.
- Repeat until total throughput is at least 28 items
- Record the number of iterations (i.e. days) it took to reach that threshold.
- Repeat around 10K times to get a distribution of iteration (i.e. days) counts
- The mean/median of this distribution is your point forecast and quantiles are the CI
- Example 4: Analyze the treatment effect in a RCT with a binary treatment and two measurement occasions: pre-treatment and post-treatment
Python
import numpy as np import polars as pl import statsmodels.api as sm from polarsgrid import expand_grid from tqdm import tqdm from multiprocessing import Pool # Component 1: the simulation grid grid = expand_grid( sample_size=list(np.arange(4, 20)), effect_size=list(np.arange(0, 1.1, 0.1)), outcome=["post", "change"], correction=[False, True], iteration=list(range(500)), _categorical=True, _row_id=True, ) grid = grid.with_columns(seed=np.random.randint(low=0, high=2**32 // 2, size=len(grid))) grid.write_parquet("processed_data/grid.parquet")- Results in 352000 individual simulations even for this small simulation with 500 repetitions and only four factors.
Base Function
def generate_data(sample_size: int, effect_size: float, seed: int) -> pl.DataFrame: np.random.seed(seed) # sample pre and post variables treated = np.arange(sample_size) < (sample_size // 2) pre = np.random.normal(0, 3, sample_size) post = pre + np.random.normal(0, 0.3, sample_size) post[treated] += effect_size # return a tidy dataframe return pl.DataFrame( { "id": np.arange(sample_size), "treated": treated, "pre": pre, "post": post, } )- pre and post are continuous measures and I’m guessing treated is a logical?(
//2is integer division)
- pre and post are continuous measures and I’m guessing treated is a logical?(
If multiple DGPs need to be tested, then create subfunctions for each DGP and call them in a conditional
def generate_data(process: str, sample_size: int, effect_size: float, seed: int): if process == "a": return generate_a(sample_size, effect_size, seed) if process == "b": return generate_b(sample_size, effect_size, seed) if process == "c": return generate_c(sample_size, effect_size, seed)Depending on the experiment, include argument tests and error handling
def generate_data(num_groups: int, sample_size: int): if num_groups >= sample_size: raise ValueError("Sample size should be larger than groups.")Flexible outputs may be needed depending other required input format of the analysis function, e.g. tuple
def generate_data(N: int, P: int, seed: int): np.random.seed(seed) X = np.random.standard_normal((N, P)) b = np.random.normal(1, 1, P) y = X @ b + np.random.normal(0, 1, N) return X, y, b
def analyze_data( df: pl.DataFrame, outcome: str, correction: bool ) -> tuple[float, float, bool]: # cast treated column to integer, needed for model fitting df = df.with_columns(pl.col.treated.cast(int)) # select columns based on simulation factors endog = df["post"] - df["pre"] if outcome == "change" else df["post"] exog = df.select(["treated", "pre"]) if correction else df.select("treated") # create and fit the model mod = sm.OLS(endog.to_numpy(), sm.add_constant(exog.to_numpy())) res = mod.fit() # return values of interest, including multicollinearity indicator return res.params[1], res.pvalues[1], res.eigenvals[-1] < 1e-10- The eigenvalues serve as an indicator for multicollinearity and can be used to explain the failure of the model for a certain generated dataset or group of parameters
- Formula has the option of using the change score (bad) as the response or the post treatment measurement in a simple OLS regression.
# Define a function which returns one row of the results table def run_simulation(id: int, params: dict): df = generate_data( sample_size=params["sample_size"], effect_size=params["effect_size"], seed=params["seed"], ) est, pval, singular = analyze_data( df=df, outcome=params["outcome"], correction=params["correction"] ) return (id, est, pval, singular) if __name__ == "__main__": with Pool() as p: results_list = p.starmap( run_simulation, tqdm(enumerate(grid.iter_rows(named=True)), total=len(grid)), ) df = pl.DataFrame( results_list, schema={"row_id": int, "estimate": float, "pvalue": float, "singular": bool}, orient="row", ) df.write_parquet("processed_data/results.parquet")Run the simulation in a sliced way using multiprocessing and produce Component 4: the results table
def run_simulation(slice_num: int, slice: pl.DataFrame): results_list = [] # iterate over each row in the slice for row in slice.iter_rows(named=True): df = generate_data( sample_size=row["sample_size"], effect_size=row["effect_size"], seed=row["seed"], ) est, pval, singular = analyze_data( df=df, outcome=row["outcome"], correction=row["correction"] ) results_list.append((est, pval, singular)) # create a dataframe for the results results_slice = pl.DataFrame( results_list, schema={"estimate": float, "pvalue": float, "singular": bool}, orient="row", ) # write the slice to disk in parquet file results_slice.write_parquet(f"processed_data/chunked_output/{slice_num:06}.parquet") if __name__ == "__main__": with Pool() as p: p.starmap( run_simulation, tqdm(enumerate(grid.iter_slices(10000)), total=len(grid) // 10000 + 1), )Calculate Power and Bias
import polars as pl import plotnine as p9 simulation_grid = pl.read_parquet("processed_data/grid.parquet") results_table = pl.read_parquet("processed_data/results.parquet") # results_table = pl.read_parquet("processed_data/chunked_output/*.parquet").with_columns(pl.row_index( "row_id")) analysis_df = simulation_grid.join(results_table, on="row_id", how="left") df_agg = ( # start with the dataframe of grid parameters and results analysis_df # Remove rows with missing data (in case the simulation is not yet done) .drop_nulls() # for each row, compute the bias and whether H0 is rejected .with_columns( bias=pl.col.estimate - pl.col.effect_size, reject=pl.col.pvalue < 0.05 ) # then group by all the simulation factors .group_by( ["sample_size", "effect_size", "outcome", "correction"], maintain_order=True ) # aggregate over iterations, with quantile interval for the bias .agg( bias=pl.col.bias.mean(), bias_lo=pl.col.bias.quantile(0.025), bias_hi=pl.col.bias.quantile(0.975), power=pl.col.reject.mean(), n=pl.len(), ) # then use a normal approximation to compute the CI for the power .with_columns(power_se=(pl.col.power * (1 - pl.col.power) / pl.col.n).sqrt()) .with_columns( power_lo=(pl.col.power - 1.96 * pl.col.power_se).clip(0.0, 1.0), power_hi=(pl.col.power + 1.96 * pl.col.power_se).clip(0.0, 1.0), ) )Plot for Power
plt = ( p9.ggplot( df_agg.filter(pl.col.effect_size.is_in([0.2, 0.5, 0.9])), p9.aes( x="sample_size", y="power", ymin="power_lo", ymax="power_hi", color="outcome", linetype="correction", ), ) + p9.geom_line() + p9.geom_pointrange() + p9.facet_wrap("effect_size", labeller="label_both") + p9.theme_linedraw() ) plt.save("img/power.png", width=10, height=4, dpi=300)Plot for Bias
plt = ( p9.ggplot( df_agg.filter(pl.col.effect_size == 0.5), p9.aes( x="sample_size", y="bias", ymin="bias_lo", ymax="bias_hi", color="outcome", linetype="correction", ), ) + p9.geom_line() + p9.geom_pointrange() + p9.facet_grid(cols="outcome", rows="correction", labeller="label_both") + p9.theme_linedraw() ) plt.save("img/bias.png", width=10, height=7, dpi=300)