RStudio Server on your docker image allows you to access an ide connected to the server through a browser. Useful so you can make sure the correct packages are installed.
Serverless computing is a method of providing backend services on an as-used basis.
A serverless provider allows users to write and deploy code without the hassle of worrying about the underlying infrastructure
Charged based on their computation and do not have to reserve and pay for a fixed amount of bandwidth or number of servers, as the service is auto-scaling
e.g. AWS Lambda (i.e. resources only get spun-up when an event is triggered)
RTX 20-series or 30-series GPUs are forbidden from inclusion in data centers
General Recommendations (Oct 2022)
A100 for model training
T4 for inference workloads
K80
Released in 2015, the K80 contained a lot of VRAM for the time (24 GB)
Came before tensor cores and is relatively weak by today’s standards
Only okay for learning purposes
P4
Released in 2016
Value came from its low power consumption
May find it priced higher than its upgraded version (the T4), so recommended to avoid it
T4
Released in 2018
Significant upgrade for inference workloads compared to the P4
Extremely low power consumption, tensor cores, and plenty (16GB) of VRAM
Cheap, so if you have an inference workload, recommended to strongly consider a T4
P100
Big improvement for model training workloads over the K80 when released
Less RAM (16GB) than K80
Way more compute than K80
Can see memory savings from using mixed-precision training
No tensor cores
V100
Huge upgrade over the P100
Same VRAM as P100 many but more CUDA cores
Introduces Tensor Cores
More cost-efficient than the P100
A100
Newest data center GPU
Upgraded tensor cores
Most benchmarks show 3x+ faster training compared to the V100
80GB VRAM
Price tag might be big, but it’s usually worth it over the V100
On-Premises
Cloud
Cons
Storage
Costs per GB of data might seem low, but when you’re dealing with terabytes of data costs add up very quickly.
Retrieval and egress fees
Compute
Variable costs based on CPU and GPU usage often spike during high-performance workloads.
Costs can then explode during usage spikes
Add-Ons for security, monitoring, and data analytics come at a premium
Pros
Make sense if you often face spikes in usage
If planning a geographic expansion or rapidly deploy new services
For “Stead-State Workloads” requiring HPC, cloud compute doesn’t make economic sense
Steady-State workloads are projects that are run near constantly
See Thread for discussion on scenarios, issues, and risks of your data center (DC) in the Cloud vs on-prem.
Examples:
Academia: Where academics are in a queue to run experiments on the a HPC cluster
Weather Forecasting: Forecasts are required nearly in real time, so these models run constantly
Financial transaction processing at a bank: The bank’s systems handle a constant stream of transactions
Inventory management system for a manufacturing plant: The system constantly receives updates on raw materials, production output, and finished goods.
Others: Week or two long analysis runs at hedge funds, genomic analysis jobs, a swath of AI training / fine tuning, Oil and Gas where they are plowing through seismic data constantly
Checklist from moving from cloud to on-prem
Assess Current Cloud Usage: Inventory applications and data volume.
Cost Analysis: Calculate current cloud costs vs. projected on-prem costs.
Select On-Prem Infrastructure: Servers, storage, and networking requirements.
Minimize Data Egress Costs: Use compression and schedule transfers during off-peak hours.
Security Planning: Firewalls, encryption, and access controls for on-prem.
Test and Migrate: Pilot migration for non-critical workloads first.
Monitor and Optimize: Set up monitoring for resources and adjust.
No services for blockchain development, quantum computing, and graph databases in GCP (May 2022)
https://cloud-gpus.com/ - tool for comparing gpu compute prices across vendors
Data centers
Closer the resources are to your business, the less latency
GCP has caught up and surpassed AWS in the number of data centers and regions that are available (May 2022)
Compute
Cheapest vCPU
GCP e2-micro-preemptible with 2 vCPU and 1 GB memory.
48% lower than t4g.nano from AWS
5 times lower than A0 from Azure.
AWS is in-between GCP and Azure in terms of price (i.e. Azure most expensive for cheap vCPUs)
More performant GCP instances usually cost approximately the same as their analogs from other cloud providers
Azure servers cost the same or slightly less than AWS
GCP: dedicated PostgreSQL server
Cheapest instances are 25% lower than the competitors
GPU on-demand availability
Conclusion: Assuming you need on-demand boxes to succeed right when you need them, the consensus seems to clearly point to AWS. If you can stand to wait or be redundant to spawn failures, maybe Google’s hardware acceleration customizability can win the day.
Stats
AWS consistently spawned a new GPU in under 15 seconds (average of 11.4s).
GCP on the other hand took closer to 45 seconds (average of 42.6s).
AWS encountered one valid launch error in these two weeks whereas GCP had 84
Caveats
GCP allows you to attach a GPU to an arbitrary VM as a hardware accelerator - you can separately configure quantity of the CPUs as needed.
AWS only provisions defined VMs that have GPUs attached
Recommendations
Azure
You use the Microsoft Office stack (Word, Teams, OneDrive, SharePoint, etc.) and/or C# programming language.
You head neither for the cheapest servers nor for the most expensive ones — you need something in the middle.
You need a memory-optimized solution rather than a general-purpose or a compute-optimized one.
You read about the current bugs and inconsistencies in Azure, and it does not scare you.
AWS
You are rich.
You have AWS experts in your team.
You build an enterprise-level long-term project.
OR you just want to rent a cheap virtual machine, and you don’t care about all the other facilities.
GCP
You are a start-up company.
You can’t invest much time in learning AWS and dealing with Azure bugs.
You don’t need much flexibility and configuration facilities from the cloud.
You are ready to accept the approaches dictated by the platform.
You need either a general-purpose or a compute-optimized solution, but not a memory-optimized one.
Price Management
Spot instances for cheaper machines
Autoscaling (kubernetes?) to handle peak usage times (spin-up more machines) while saving during slow times (spin down excess machines)
Use opensource project management tools (dvc, airflow, etc)
Google
The Google Kubernetes Engine (GKE) control plane is free, whereas Amazon’s (EKS) costs $0.20 an hour.
AWS
With a well-defined framework of tag keys and values applied across different AWS resources, billing breakdowns by tag prove extremely useful for greater insight on the source of AWS charges — especially if resources are tagged by department, or team, or different layers of organizational granularity.
Reserved Instances - commit to specific configurations for one or three years at reduced cost
Spot Instances - pay significantly lower costs but potential for applications to be interrupted
Will not manage images and snapshots created by other means, and it also excludes instance store-backed images.
EC2 Recycle Bin - serves as a safety net to avoid the accidental deletion of resources — retaining images and snapshots for a configurable time where we may restore them before they are deleted permanently.
Lambda
Cloudwatch - Lambda automatically creates log groups for its functions, unless a group already exists matching the name /aws/lambda/{functionName}. These default groups do not configure a log retention period, leaving logs to accumulate indefinitely and increasing CloudWatch costs.
Explicitly configure groups with matching names and a retention policy to maintain a manageable volume of logs.
Lambda charges based on compute time in GB-seconds, where the duration in seconds is measured from when function code executes until it either returns or otherwise terminates, rounded up to the nearest millisecond. To reduce these times, we desire optimal memory configuration.
Charged for how much data stored, but also which S3 storage classes are utilized.
Standard (default) class is the most expensive, permitting regular access to objects with high availability and short access times.
Infrequent Access (IA) classes offer reduced cost for data which requires limited access (usually once per month)
Archival options via Glacier deliver further cost reductions.
Configuring the lifecycle allows you to automatically transfer data to different storage classes and thereafter permanently delete it, X and Y days respectively after data creation
Kaggle
Free
4-core CPU instances w/30 GB RAM
2-core CPU, 2xT4 GPU w/13GB RAM
T means tensor cores
1 hour spent using 2xT4’s takes the same amount of your quota as a P100 (old free gpu offering)
Means 30-40 hours of free, multi-GPU compute per week
Saturn Cloud
Saturn Cloud Recipes
JSON files that specify your environment
Good for keeping track of server dependencies (e.g. linux libraries)
Dunno about R packages
Google Cloud Platform (GCP)
BigQuery sandbox is Google’s GCP free tier cloud SQL database. It’s free but your data only lasts 60 days at a time.
GCP allows users to run deep learning workloads on TPUs
Since data expires after 60 days, back-up the model coefficients and performance score tables to Google Sheets. Article suggested this is possible through WebUI.
As of Nov.19, regression, logistic regression, and k-nn are the only models available to be run with the sql query editor
50,000 reads, 20,000 writes, 20,000 deletes per day
Functions
1 f1-micro instance per month (Available only in region: us-west1, Iowa: us-central1, South Carolina: us-east1)
30 GB-months HDD
5 GB-months snapshot in select regions
1 GB network egress from North America to all region destinations per month (excluding China and Australia)
Kubernetes
One-click container orchestration via Kubernetes clusters, managed by Google.
No cluster management fee for clusters of all sizes
Each user node is charged at standard Compute Engine pricing
App Engine
28 instance hours per day
5 GB Cloud Storage
Shared memcache
1,000 search operations per day, 10 MB search indexing
100 emails per day
BigQuery
Fully managed, petabyte scale, analytics data warehouse.
1 TB of querying per month
10 GB of storage
Other Stuff
Your free trial credit applies to all GCP resources, with the following exceptions:
You can’t have more than 8 cores (or virtual CPUs) running at the same time.
You can’t add GPUs to your VM instances.
You can’t request a quota increase. For an overview of Compute Engine quotas, see Resource quotas.
You can’t create VM instances that are based on Windows Server images.
You must upgrade to a paid account to use GCP after the free trial ends. To take advantage of the features of a paid account (using GPUs, for example), you can upgrade before the trial ends. When you upgrade, the following conditions apply:
Any remaining, unexpired free trial credit remains in your account.
Your credit card on file is charged for resources you use in excess of what’s covered by any remaining credit.
You can upgrade your account at any time after starting the free trial. The following conditions apply depending on when you upgrade:
If you upgrade before the trial is over, your remaining credit is added to your paid account. You can continue to use the resources you created during the free trial without interruption.
If you upgrade within 30 days of the end of the trial, you can restore the resources you created during the trial.
If you upgrade more than 30 days after the end of the trial, your free trial resources are lost.
includes a 12-month free trial with $300 credit to use with any GCP services and an Always Free benefit, which provides limited access to many common GCP resources
Use to test out, but KEEP EVERYTHING SMALL (data, hardware, etc). Need to upgrade it to see the true benefit. Free tier resources look like my desktop computer. Whatever cash is leftover should transfer to account.
Create a project. “select a project” on top bar \(\rightarrow\) “new project” on top right \(\rightarrow\) choose name (optionally a folder/organization if you have one) \(\rightarrow\) create
Article wasn’t very reliable and went on talk about a python implementation so I stopped here
Tips
App Engine
Don’t use App Engine Standard environments — big brother G wants you to use rather Flex environments, otherwise, they’ll punish you.
Review cost analysis regularly to make sure there are no surprising costs.
Make sure you clean up redundant App Engine application versions to prevent G from robbing you.
Starts azure trial but gives you free sql server developer edition
Won’t be charged until you choose to upgrade.
12 months access to $ services for free
$200 credit for any service for 30 days
At the end of the 30 days, I think the remainder goes into your account after you change to a pay-to-play account
Access to the services that are always free
Azure Kubernetes Service (AKS)
Functions
1,000,000 requests per month
A solution for easily running small pieces of code in the cloud. You can write just the code you need for the problem at hand, without worrying about a whole application or the infrastructure to run it.
Example use case: For handling WebAPI requests and sending the different data and results to where it needs to go.
App Service
10 web, mobile, or API apps
Active Directory B2C (identity)
50,000 authentications per month
Machine Learning Server
Develop and run R and Python models on your platform of choice.
SQL Server 2017 Developer Edition
Build, test, and demostrate applications in a non-production environment.
Other stuff
Blob storage
Object storage solution for the cloud
Optimized for storing massive amounts of unstructured data
Spot Instances (Low Priority VM)
Not time limit on instance usage
No warning on termination by Azure
Tips
If you can’t create a service, because Azure servers are under maintenance for more than a couple of minutes — check out your permissions and registrations under the “Resource providers” panel.
If you see any strange errors on the Azure Portal — just change the filters’ values.
If you use Azure Machine Learning, and your scoring function cannot locate your source code — deliver the code as a Model and add it explicitly to the sys.path in the init function.
If you use Azure Machine Learning, don’t use Batch Endpoints — it looks like they are not ready yet — just use the regular Published Pipelines. In fact, “Batch endpoint” is just a wrapper around a published pipeline.
Don’t include flask in your Azure conda environment specification.
“Each thread is represented as a virtual CPU (vCPU) on the instance. An instance has a default number of CPU cores, which varies according to instance type. For example, an m5.xlarge instance type has two CPU cores and two threads per core by default—four vCPUs in total.”
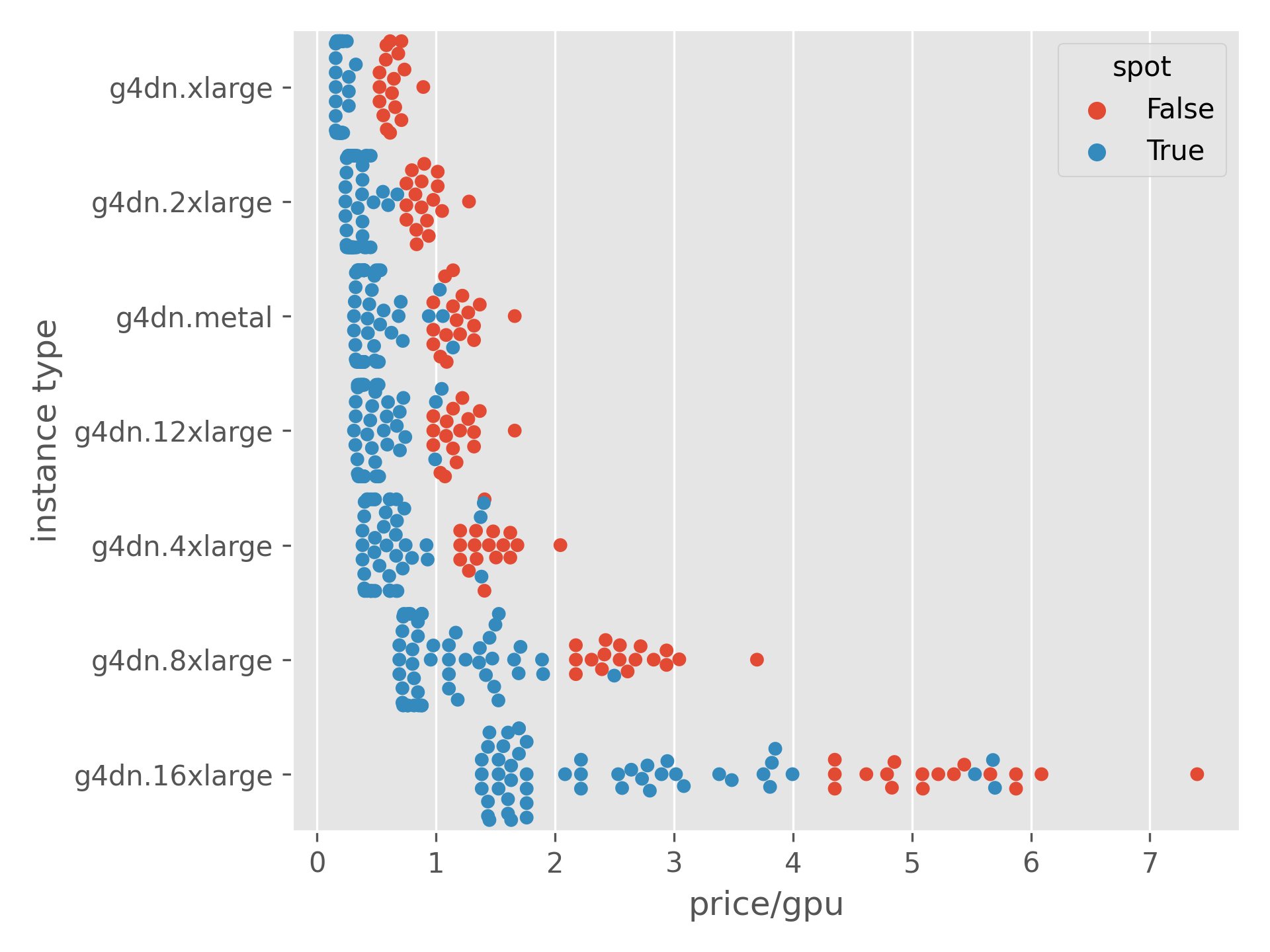
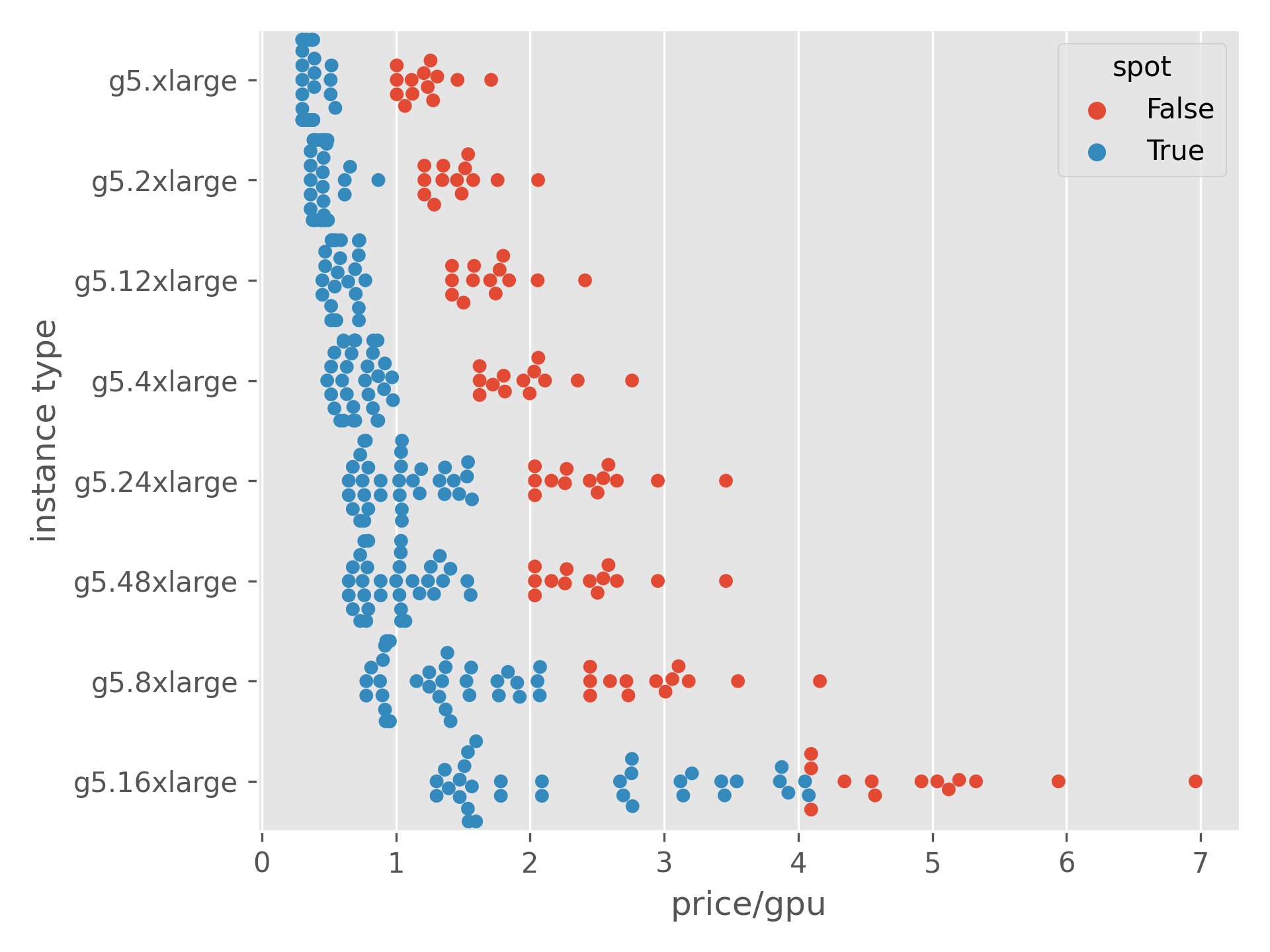
Spot prices from 03/24/2020, all calculations over the previous month
General Purpose
m6g.8xlarge
General Purpose, 32 vcpu, 128 gb
Newer graviton, didn’t see any specs, but supposed to be much better than the xenon 1st gen
m5.8xlarge
Gen Purpose, 32 vcpu, 128 gb
Older 3.1 ghz, xenon
On-Demand $1.54/hr
m5a.8xlarge
Gen Purpose 32 vcpu, 128 gb
2.4 ghz, slower processor speed than m5
m5n.8xlarge
Gen Purpose 32 vcpu, 128 gb
3.1 ghz, xenon specialized for neural networks, ML tasks
n.virg, 71% savings, <5% interruption
ohio, 83% savings, <5% interruption
On-Demand $1.90/hr
Potential spot price = $0.32
m5dn.8xlarge
Same but with 2 ssd hard drives
m4.10xlarge
Gen purpose 40 vcpu, 160 gb
2.4 ghz
Smaller write-up, get the sense these are older processors/instances
Compute Optimized
Requires HVM AMIs that include drivers for ENA (network adaptor) and NVMe (ssd hard drives)
Seems standard on a lot of instances (gen purpose and here), shouldn’ t be an issue
c5.9xlarge
36 vcpu, 72 gb
3.4 ghz
On-Demand $1.53/hr
c5d.9xlarge
Same but with ssd
c5n.9xlarge
36 vcpu, 96 gb
3.0 ghz, built for task needing high throughput for networking
For requesting a spot instance through CLI I think
Looks like you send something that looks like a python dict with max price, type, region, etc. to this API
Spot Blocks
Allows you to set a finite duration that your instance will run for
1 to 6 hrs
No interruption during that time
Typically 30 to 45% cheaper than on-demand and maybe an additional 5% cheaper during non-peak hours for the region
Recommended for batch runs
Strategy
Use regions with largest pools of spot instances
Largest pools
us.east.1 (North Virginia)
eu.west.1 (Ireland)
These regions have most types/most instances available
Typically can go uninterrupted for weeks
Less price fluctuation = more certainty
Smallest pools
eu.central.1 (Frankfort)
ap.south.1 (Mumbai)
ap.southeast.1 (Singapore)
Typically get interrupted within days
Run groups of instances that come from multiple spot pools
To used different compute types, jobs/tasks need to be in containers
Spot pools are instances with same region, type, OS, etc.
Applications running on instances from a least 5 different pools can cut interruptions by up to 80%
Managing/preparing for interruptions
Only use for jobs that are short lived
Development and staging environments, short data processing, proof-of-concept, etc.
Build internal management system that automatically handles interruptions
Look at spot pool historical prices for past 90 days
Looking for least volatile pools
Older generation (e.g. c-family, m-family) tend to be most stable
Use 3rd party platform that manages spot instances and interruptions
Spotinst - Uses ML to choose and manage instances that optimizes price and provide continuous activity for apps that are without a single point of failure.
Uses on-demand as a fall-back.
SLA guarantees 99.9% availability.
Snapshots volumes to migrate data to new instances in case of interruption.
Works with other services and platforms (kubernetes, codedeploy, etc.)
Spot Fleet - aws service, automanages groups of spot instances according to either of the following strategies:
strategy options
Lowest price - lowest price instances
Diversified - spread instances across pools
After receiving 2 min warning,
Take snapshots of AMI and any attached EBS volumes and use them to launch a new instance.
Snapshot of AMI
On EC2 dashboard \(\rightarrow\) left panel \(\rightarrow\) Instances \(\rightarrow\) Instances
Right-Click Instance \(\rightarrow\) Image \(\rightarrow\) Create AMI
Image is in left panel \(\rightarrow\) Images \(\rightarrow\) AMIs
Actually both snapshots might be able to taken in left panel \(\rightarrow\) spot requests
Need to drain and detach instance from elastic load balancer if one is used
If using auto-scaling, need to create an on-demand group and a spot instance group
Kubernetes
After receiving 2 minute interruption warning from AWS:
Detach instance from elastic load balancer (ELB) is one is being used
Mark instance as unschedulable (?)
Prevents new pods (group of containers on an instance that performs a job) from being scheduled on that node
Underlying compute capacity and scheduling of resources of the pods needs to be monitored. Compute capacity and pod resource requirements need to match.