Planning
Misc
- Packages
- CRAN Task View: Clinical Trial Design, Monitoring, and Analysis
- {DeclareDesign} - A system for describing research designs in code and simulating them in order to understand their properties (Also see book in Resources)
- {RCTRecruit} - Non-Parametric Recruitment Prediction for Randomized Clinical Trials
- Helps to estimate if the experiment is feasible (i.e. if you can get enough subjects to measure a particular effect size), cost, testing recruitment strategies, etc.
- Resources
- Bayesian Clinical Trial Design Course (Harrell)
- Research Design in the Social Sciences: Declaration, Diagnosis, and RedesignDeclaration, Diagnosis, and Redesign ({DeclareDesign})
- Ch.9, Introduction to Bayes for Evaluating Treatments (Harrell)
- If you’re going to analyzing the results of a test, ask to be involved in the planning stages. This well help insure that the test has usable results.
- Evidence-based Medicine (EBM) - Uses the scientific method to organize and apply current data to improve healthcare decisions. (See source for more details)
- Steps
- Defining a clinically relevant question
- Searching for the best evidence
- Critically appraising the evidence
- Applying the evidence
- Evaluating the performance of EBM
- Steps
- Sources of Bias
- Also see
- Sampling Bias - The probability distribution in the collected dataset deviates from its true natural distribution one would actually observe in the wilderness.
- Spectrum Bias - Whenever a distribution which a model has been trained with changes, e.g. due to spatial or temporal effects, the validity of this model expires. (model drift?)
- Check randomization procedure by testing for pairwise associations between the treatment variable and the adjustment variables. If independence is rejected (pval < 0.05), then randomization failed. (Also see Experiments, A/B Testing >> Terms >> A/A Testing)
- Treatment vs Continuous - 2 Sample t-Tests
- Treatment vs Categorical - Chi-Square Test
- Error

- The false positive rate is closely associated with the “statistical significance” of the observed difference in metric values between the treatment and control groups, which we measure using the p-value.
- FPR typically set to 5% (i.e. falsely conclude that there is a “statistically significant” difference 5% of the time)
- False negatives are closely related to the statistical concept of power, which gives the probability of a true positive given the experimental design and a true effect of a specific size
- Power = 1 - FNR
- The false positive rate is closely associated with the “statistical significance” of the observed difference in metric values between the treatment and control groups, which we measure using the p-value.
- Biostatistical Endpoints (outcome variables)
- From Harrell
- Considerations (Also See hbiostat.org/endpoint)
- Don’t use Y that means different things to different subjects
- E.g.: impact of time to doubling of SCr depends on initial SCr
- Time to recovery must be shorter for minimally diseased pts
- Instead of change from baseline use raw response and covariate adjust for baseline
- Treat longitudinal data as longitudinal
- Don’t use Y that means different things to different subjects
- Bad Endpoints
- Change from baseline and % change
- Time until the first of several types of events
- Especially when some events are recurrent or events have differing severities
- Time to recovery
- Ignores unrecovery, close calls, and can’t handle interrupting events
- Time until a lab value is in a normal or an abnormal range
- Time to doubling of serum creatinine
- Acute kidney injury (standard AKI definitions)
- Ventilator-free days
- Most ratios
- BMI when it doesn’t adequately summarize weight and height
- Not Y=BMI; analyze weight, covariate adjusted for initial weight, height, age
- Traditional two-arm randomized controlled trials are not an optimal choice when multiple experimental arms are available for testing efficacy. In such situations, a multiple-arm trial should be preferred, which allows simultaneous comparison of multiple experimental arms with a common control and provides a substantial efficiency advantage.In multi-arm trials, several arms are monitored in a group sequential fashion, with ineffective arms being dropped out of the study. Therefore, multi-arm trials offer a more efficient, cost-effective, and patient-centered approach to clinical research, with the potential to identify superior treatments more reliably than traditional two-arm trials. ({gsMAMS} vignette)
- Bayesian Dynamic Borrowing (BDB)
- A mathematically rigorous and robust approach to increase efficiency and strengthen evidence by integrating existing trial data into a new clinical trial.
- Papers
- Goals
- Reduce the sample size required to achieve a desired level of confidence for the new study.
- Boost its decision-making power without large increases in sample size.
- Packages
- {BayesFBHborrow} (Vignette) - Bayesian borrowing for time-to-event data from a flexible baseline hazard
- Simulation
- Notes from Modelling Like an Experimentalist
- Contributes to rigor, by ensuring the analysis is comprehensive rather than selective; to reliability, by making it easier to detect mistakes or fragile assumptions; and to credibility, by allowing readers to see that the work has been carried out thoroughly and with due care.
- Good Practices
- Validate With Simulated Truth: Simulate data under a model where the ‘truth’ is known, and then apply the intended analysis. One can verify that the procedure produces unbiased or consistent results.
- Sensitivity Analysis: Vary treatments, parameters, and other modeling decisions systematically to test the robustness of results
- Choices about initial conditions, spatial or temporal resolution, or how data are filtered can be treated as experimental factors.
- Exposes whether the conclusions depend narrowly on assumptions or remain stable across a reasonable range and helps to make both the choices that inevitably are made and their consequences explicit
- Perturbation Techniques: Deliberately break or shuffle connections in models or data pipelines to reveal artefacts, i.e. an intentional disruption meant to show what happens in the absence of a true signal
- Examples include permuting covariates, introducing dummy variables with no intended effect, randomizing network connections or shuffling trait values across taxa
- The goal is to test whether observed patterns/effects still emerge. If they do, the apparent effect is likely an artefact of the pipeline rather than a property of the system.
Considerations
- Metrics
- If using multiple metrics/KPIs, make sure that you and the product manager agree on which metric/KPI should be primary and which should be secondary.
- Where do users get randomized? Can depend on the KPI you’re measuring.
- App or website login - appropriate for product purchasing
- A click on the first screen of the signup flow - appropriate for app subscriptions
- Will you only be testing a subset of your customers?
- Example: Testing changes in one country or platform and apply the learnings from the test before releasing them to our remaining users
- May affect the baseline KPI used to calculate the sample size
- Example: if a new feature is only going to be tested for English users on iOS the conversion rate may be different than the rate for all users on iOS. This also affects the number of users expected to enter the test because more users logged into iOS versus just English users.
- Calculate sample size
- May take months to reach the sample size needed to determine statistical significance of a measured effect
- (Approx) Sample Size
- See Sample Size/Power/MDE
- Issues
- Getting more samples or running an experiment for a longer time to increase the sample size might not always be easy or feasible
- If your sample size is large and therefore test duration is too long, you may need to change the metric/KPI you’re measuring
- Example
- KPI: test whether new feature increased the percentage of new users that returned to the app 30 days after signup.
- This meant the test needed to run an additional 30 days to ensure new users in the control didn’t get exposed to the new feature within the 30-day engagement window we wanted to measure.
- Example
- Does the time of year matter?
- Is there a seasonality aspect to your KPI, customer engagement, etc.?
- If so, the treatment effect may differ depending on when the test is conducted
- Is there a seasonality aspect to your KPI, customer engagement, etc.?
- Monitoring
- Confirm group/cohort proportions
- Example: If you have 3 treatments (aka variants) and 1 control, make sure each group has 25% of the test participants
- Unbalanced groups can result in violations of assumptions for the statistical tests used on the results
- Track KPIs
- Very bad treatments could substantially affect KPIs negatively. So you need to pull the plug if your business starts to tank.
- Confirm group/cohort proportions
Sample Size/Power/MDE
Misc
Packages
- {adsasi} - Adaptive Sample Size Simulator
- The user writes a function that takes as argument a sample size and returns a boolean (for whether or not the trial is a success). The ‘adsasi’ functions will then use it to find the correct sample size empirically.
- The unavoidable mis-specification is obviated by trying sample size values close to the right value, the latter being understood as the value that gives the probability of success the user wants (usually 80 or 90% in biostatistics, corresponding to 20 or 10% type II error).
- {bayespmtools} (Paper) - Performs Bayesian sample size, precision, and value-of-information analysis for external validation of existing multi-variable prediction models (Harrell-supported)
- {BayesPower} - Sample Size and Power Calculation for Bayesian Testing with Bayes Factor
- {gsDesignNB} - Sample Size and Simulation for Negative Binomial Outcomes
- Provides tools for planning and simulating recurrent event trials with overdispersed count endpoints analyzed using negative binomial (or Poisson) rate models
- {gsMAMS} (Vignette): an R package for Designing Multi-Arm Multi-Stage Clinical Trials
- For designing group sequential multi-arm multi-stage (MAMS) trials with continuous, ordinal, and survival outcomes, which is computationally very efficient even for a number of stages greater than 3.
- {GenTwoArmsTrialSize} (Vignette): An R Statistical Software Package to estimate Generalized Two Arms Randomized Clinical Trial Sample Size
- Incorporates four endpoint types, two trial treatment designs, four types of hypothesis tests, as well as considerations for noncompliance and loss of follow-up, providing researchers with the capability to estimate sample sizes across 24 scenarios.
- {mixpower} - A comprehensive, simulation-based toolkit for power and sample-size analysis for linear and generalized linear mixed-effects models
- {pmsesampling} - Provides analytic and simulation tools to estimate the minimum sample size required for achieving a target prediction mean-squared error (PMSE) or a specified proportional PMSE reduction (pPMSEr) in linear regression models.
- {powerbrmsINLA} - Provides tools for Bayesian power analysis and assurance calculations using the statistical frameworks of ‘brms’ and ‘INLA’.
- Includes simulation-based approaches, support for multiple decision rules (direction, threshold, ROPE), sequential designs, and visualization helpers.
- {powergrid} - Evaluate a function across a grid of parameters
- Parallel computing is facilitated.
- Utilities aim at performing analyses of power and sample size, allowing for easy search of minimum n (or min/max of any other parameter) to achieve a desired minimal level of power (or maximum of any other objective)
- {pwrss} - Flexible and comprehensive functions for statistical power and minimum required sample size calculations across a wide range of commonly used hypothesis tests
- Includes means, proportions, correlations, independence, linear, logistic, poisson, mediation, anova, anova mixed effects, ancova, and planned contrasts.
- {samplesizedev} (Paper) - Sample Size Calculations for the Development of Risk Prediction Models that Account for Performance Variability
- {simr} (Slides)- Calculates power for generalized linear mixed models from lme4 using Monte Carlo simulations
- {Spower} - Power Analyses using Monte Carlo Simulations
- Focuses exclusively on Monte Carlo simulation variants of (expected) prospective power analyses, criterion power analyses, compromise power analyses, sensitivity analyses, and prospective/post-hoc power analyses
- Provides stochastic variants of the power analyses subroutines found in the G*Power 3 software
- {WebPower} - Tools for conducting both basic and advanced statistical power analysis including correlation, proportion, t-test, one-way ANOVA, two-way ANOVA, linear regression, logistic regression, Poisson regression, mediation analysis, longitudinal data analysis, structural equation modeling and multilevel modeling
- {adsasi} - Adaptive Sample Size Simulator
Resources
- Power Analysis for Experiments with Clustered Data, Ratio Metrics, and Regression for Covariate Adjustment - A tutorial of the mathematics behind power analysis of clustered data and covariated adjusted effects.
Tools
Underpowered Experiments
“In particular, if your data are noisy relative to the size of the effects you can reasonably expect to find, then it’s a big mistake to use any sort of certainty thresholding (whether that be p-values, confidence intervals, posterior intervals, Bayes factors, or whatever) in your summary and reporting. That would be a disaster—type M and S errors will kill you.
So, if you expect ahead of time that the study will be summarized by statistical significance or some similar thresholding, then I think it’s a bad idea to do the underpowered study. But if you expect ahead of time that the raw data will be reported and that any summaries will be presented without selection, then the underpowered study is fine.” Gelman
Sample Size Justification (See article for more details on each type)
Type of justification When is this justification applicable? Measure entire population A researcher can specify the entire population, it is finite, and it is possible to measure (almost) every entity in the population. Resource constraints Limited resources are the primary reason for the choice of the sample size a researcher can collect. Accuracy The research question focusses on the size of a parameter, and a researcher collects sufficient data to have an estimate with a desired level of accuracy. A-priori power analysis The research question has the aim to test whether certain effect sizes can be statistically rejected with a desired statistical power. Heuristics A researcher decides upon the sample size based on a heuristic, general rule or norm that is described in the literature, or communicated orally. No justification A researcher has no reason to choose a specific sample size, or does not have a clearly specified inferential goal and wants to communicate this honestly. Considerations when deciding on an effect size (See Sample Size Justification >> What is Your Inferential Goal? for more details)
Type of evaluation Which question should a researcher ask? Smallest effect size of interest What is the smallest effect size that is considered theoretically or practically interesting? The minimal statistically detectable effect Given the test and sample size, what is the critical effect size that can be statistically significant? Expected effect size Which effect size is expected based on theoretical predictions or previous research? Width of confidence interval Which effect sizes are excluded based on the expected width of the confidence interval around the effect size? Sensitivity power analysis Across a range of possible effect sizes, which effects does a design have sufficient power to detect when performing a hypothesis test? Distribution of effect sizes in a research area What is the empirical range of effect sizes in a specific research area, in which effects are a priori unlikely to be observed? Power Functions for Tests, ANOVA, Regression (Slides for more details on usage)
Approximate Sample Size
- 80% Power
- Formula
\[ n = \frac{8}{\mbox{Effect Size}^2} \]- You can substitute correlation (?) for effect size
- Difference between means of two groups
\[ n = \frac{32}{\mbox{Effect Size}^2} \] - Using variance
\[ n = \frac{16\sigma^2}{\delta^2} \]- \(\sigma\) is variance of the data (outcome?)
- \(\delta\) is the effect size
- Formula
- 90% Power
\[ n = \frac{11}{\mbox{Effect Size}^2} \] - Bayesian
- From https://www.rdatagen.net/post/2021-06-01-bayesian-power-analysis/
- Bayesian inference is agnostic to any pre-specified sample size and is not really affected by how frequently you look at the data along the way
- A bayesian power analysis to calculate a desired sample size entails using the posterior distribution probability threshold (or another criteria such as the variance of the posterior distribution or the length of the 95% credible interval)
- Minimum Detectable Effect (MDE) is proportional to 1/sqrt(sample_size)
- Example: Gelman (Confirming sample size of 126 has 80% power)
- Assumption: drug (binary treatment) increased survival rate by 25 percentage points (i.e. treatment effect)
- Evidently for a survival model, but Gelman uses standard z-test gaussian power calculation. So, I guess the survival model part doesn’t matter.
- “With 126 people divided evenly in two groups, the standard error of the difference in proportions is bounded above by \(\sqrt{0.5 \cdot 0.5 /63 + 0.5 \cdot 0.5 /63} = 0.089\), so an effect of 0.25 is at least 2.8 standard errors from zero, which is the condition for 80% power for the z-test.”
- SE for the difference in 2 proportions
\[ \text{SE} = \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}} \]- In the example, the experiment is balanced so both the treatment and control groups have an equal number of participants (i.e. 63 in each group which is a 0.5 proportion of the total sample size)
- 0.25 / 0.089 = 2.8 s.d. from 0
- SE for the difference in 2 proportions
- Gelman’s Explanation: “If you have 80% power, then the underlying effect size for the main effect is 2.8 standard errors from zero. That is, the z-score has a mean of 2.8 and standard deviation of 1, and there’s an 80% chance that the z-score exceeds 1.96 (in R,
pnorm(2.8, 1.96, 1, lower.tail = F)= 0.8).”- Explanation of the Explanation: “A two-tail hypothesis with a significance level of 0.05 are assumed. The right-tail critical value is 1.96. The power is the mass of the sampling distribution under the alternative to the right of this decision boundary. Then we want to find a Gaussian with a standard deviation of 1 so that 80% of its mass is to the right of 1.96. Then a mean of 2.8 gives the desired outcome.”
- Also see Notebook pg 95
- Assumption: drug (binary treatment) increased survival rate by 25 percentage points (i.e. treatment effect)
Increasing Power
- Increase the expected magnitude of the effect size by:
- Being bold vs incremental with the hypotheses you test.
- Testing in new areas of the product
- Likely more room for larger improvements in member satisfaction
- Increase sample size
- Allocate more members (or other units) to the test
- Reduce the number of test groups
- There is a tradeoff between the sample size in each test and the number of non-overlapping tests that can be run at the same time.
- Test in groups where the effect is homogenous
- Increases power by effectively lowering the variability of the effect in the test population
- Netflix paper
- Example: Testing a feature that improves latency
- e.g. The delay between a member pressing play and video playback commencing
- Latency effects are likely to substantially differ across devices and types of internet connections
- Solution: Run the test on a set of members that used similar devices with similar web connections
{PUMP}
- Frequentist Multilevel Model Power/Sample Size/MDE Calculation
- Misc
- Factors affecting power
- With at least 1 outcome:
- Design of the study; assumed model (type of regression)
- nbar, J, K: number of levels (e.g. students, schools)
- Unless block size differences are extreme, these should not affect power that much
- T: proportion of units treated
- Number of Covariates
- and their R2 which is the proportion of variance that they explain
- ICC: ratio of variance at a particular level (e.g. student, school) to overall variance
- Unique to multiple outcomes
- Definitions of power
- Choose depends on how we define success
- Types
- Individual: probability of rejecting a particular H0
- the one you learn in stats classes
- 1-Minimal: probability of rejecting at least 1 H0
- D-Minimal: probability of rejecting at least D H0s
- Complete (Strictest): probability of rejecting all H0s
- Individual: probability of rejecting a particular H0
- Note: in the video, the presenter wasn’t aware of any guidelines (e.g. 80% for Individual) for the different types of power definitions
- M: number of outcomes, tests
- rho: correlation between test statistics
- Proportion of outcomes for which there truly are effects
- Multiple Testing Procedure (MTP)
- Definitions of power
- With at least 1 outcome:
- Uses a simulation approach
- Calculate test statistics under alternative hypothesis
- Use these test stats to calculate p-values
- Calculate power using the distribution of p-values
PUMP::pump_power- Options
- Experiment
- Levels: 1, 2, or 3
- Randomization level: 1st , 2nd, or 3rd
- Model
- Intercepts: fixed or random
- Treatment Effects: constant, fixed, or random
- MTP
- Bonferroni: simple, conservative
- Holm: less conservative for larger p-values than Bonferroni
- Benjamini-Hochberg: controls for the false discovery rate (less conservative)
- Westfall-Young
- Permutation-based approach
- Takes into account correlation structure of outcomes
- Computationally intensive
- Not overly conservative
- Romano-Wolf
- See Statistical Concepts >> Null Hypothesis Significance Testing (NHST) >> Romano and Wolf’s correction
- Similar to Westfall-Young but less restrictive
- Experiment
- Example
Description
- Outcome: 3 level categorical
- 2-level Block Design
- “2-level”: students within schools
- “Block Design”: treatment/control randomization of students occurs within each school
Power calculation
library(PUMP) pow <- pump_power( d_m = "d2.1_m2fc", # Choice of design and model MTP = "BF", # Multiple Testing Procedure MDES = rep(0.10, 3), # Assumed Effect Sizes M = 3, # Number of Outcomes J = 10, # Number of Blocks nbar = 275, # Average Number of Units per Block Tbar = 0.50, # Proportion of Units Treated per Block alpha = 0.05, # Significance Level numCovar.1 = 5, # Number of Covariates at Level 1 R2.1 = 0.1, # Assumed R^2 of Level 1 Covariates ICC.2 = 0.05, # Intraclass Correlation rho = 0.4 # Test Statistic Correlation )- d_m is the code for the experimental design (assume these are listed in the documentation)
- MDES is a vector of the treatment effects for each of the 3 levels of the outcome
- See “Factors affecting power” (above) for descriptions of some of these args.
Results
.png)
- See above for descriptions of the types of power (Factors affecting power >> Unique to multiple outcomes >> Definitions of Power)
- None: w/o multi-test correction: 81% power
- BF: w/ Bonferroni (multiply p-values by number of outcomes): 67%
- D1, D2, D3 are individual power for each of the 3 levels of the outcome
- min1, min2 are at least 1, 2 levels of the outcome
- complete is for all 3 levels of the outcome (will always be lowest)
pump_mdes()calculates minimal detectable effect size (MDES)pump_sample()calculates the sample size given target power (e.g. 0.80) and MDESSample Size Types
- K: Number of level 3 units (e.g. school districts)
- J: Number of level 2 units (e.g. schools)
- nbar: Number of level 1 units (e.g. students)
Example
ss <- pump_sample( target_power = 0.8, # Target Power power.definition = "min1", # Power Definition typesample = "J", # Type of Sample Size Procedure tol = 0.01, # Tolerance d_m = "d2.1_ms2fc", # See above for the rest of these MTP = "BF", MDES = 0.1, M = 3, nbar = 350, Tbar = 0.50, alpha = 0.05, numCovar.1 = 5, R2.1 = 0.1, ICC.2 = 0.05, rho = 0.4 )- Results
.png)
- Results
- Observe the sensitivity of power for different design parameter values
Example
pgrid <- update_grid( pow, # vary parameter values rho = seq(0, 0.9, by = 0.1) # compare multiple MTPs MTP = c("BF", "HO", "WY-SS", "BH") ) plot(pgrid, var.vary = "rho")
- Options
- Outputs facetted multi-line plots with
- y = rho, y = power
- Multiple lines by MTP
- Facetted by power definition
Collection
- Record data; don’t calculate or transform it
- If possible, store data as text or in text compatible format. (i.e. .csv, .tsv, or some other delimited file)
- Some other formats add trailing spaces, etc.
- If possible, store data as text or in text compatible format. (i.e. .csv, .tsv, or some other delimited file)
- Back up data
- Multiple places is recommended
- Curate Data Organization
- Clean data with simple organization fosters its use and a shared understanding of procedures and analysis.
- Observations, cases, or units, etc. appear in rows
- Variables appear in columns
- Values for observations on variables appear in the matrix of cells between them
- Nesting structure (i.e. grouping variables) should appear in columns, not rows.
- Beware complicated row, column, or value labels.
- Row, column, or value labels with case sensitive characters, special characters, or whitespace cause problems in analytical software beyond the spreadsheet (they can be a problem within the spreadsheet as well)
- Use lower cases that fully denote the observation, variable, or label, unless data is used as-is.
- Avoid spaces.
- Use underscores rather than periods to indicate white space.
- Avoid special characters — “percent” or “pct” is better than “%.”
- All calculations should occur outside the data repository
- ** Keep an original, un-adulterated copy of the data in a separate sheet or file **
- Carrying calculations, summaries, and analysis within the data structure gets in the way of efficient updating.
- Updating an analysis means merely updating the data set (again in the native form) called by the procedure if scripts and functions are well-documented.
- Automating reporting and analysis is a big deal in both the public and private sectors.
- Do not summarize data during collection (unless the need is pressing)
Post-Experiment Evaluation Checklist
- Did the test run long enough so that the sample size reached?
- Are treatment variants proportioned correctly?
- Did users get exposed to multiple treatment variants and how many?
Decreasing the Sampling Variance of the Treatment Effect
Misc
- Notes from Online Experiments Tricks — Variance Reduction
- Alternative to increasing power
- Winsorize ({DescTools::Winsorize}), dichotomizing, etc. metrics will help decrease the variance significantly, but introduce more bias
- CUPED is widely used and productionalized in tech companies and ML-based methods are often used to incorporate multiple covariates. (see below)
Stratified Sampling
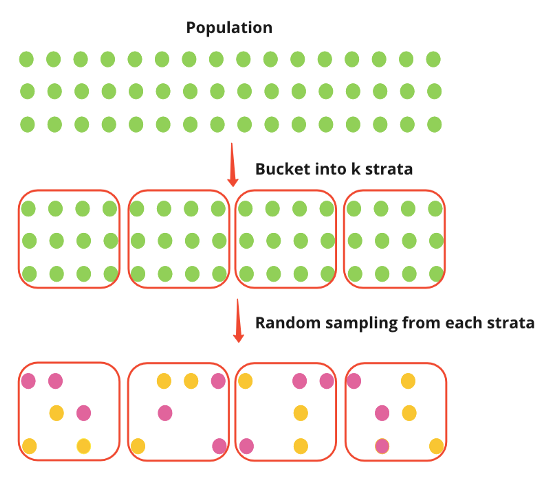
- See Surveys, Sampling Methods >> Probabilistic Sampling Methods >> Stratified Sampling
- Pro - Provides an unbiased estimate of the treatment effect and effectively removes the between-strata variance
- Con - Very hard to implement stratified sampling before experiments
Post-Stratification
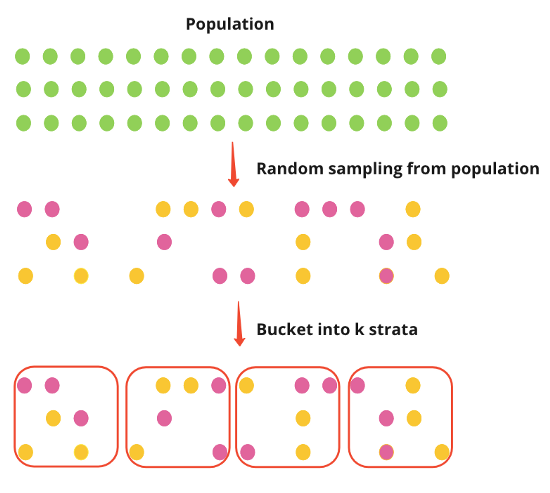
- Post-stratification randomly samples the population first and then places individuals into strata.
- The Effect is measured as a difference in means between treated and untreated
- Steps
- Randomly sample population then allocate individuals into strata
- Randomly assign treatment to all individuals all together
- She didn’t do the assignment per strata which I’m not sure is correct. You could get a long run of 1s for one strata and a long run of zeros for another strata.
- Run experiment
- For each strata
- Calculate mean outcome for treated and mean outcome for untreated
- Calculate the difference in mean outcomes
- Take the mean of the differences for the average treatment effect (ATE)
- Denominator is the number of strata
- In the example, the procedure was simulated multiple times to get an ATE distribution
- I guess you could bootstrap or use {emmeans} to CIs, pvals, etc.
CUPED
- CUPED stands for Controlled-Experiment Using Pre-Experiment Data
- Misc
- This blog post goes through the algebra extending CUPED from one covariate, \(X\), to multiple covariates.
- Also see Understanding CUPED
- This blog post goes through the algebra extending CUPED from one covariate, \(X\), to multiple covariates.
- Optimization
Formula
\[ \begin{aligned} &Y_{\text{cuped}} = Y - \theta X \\ &\mbox{Var}(Y_{\text{cuped}}) = \mbox{Var}(Y) - 2\theta \mbox{Cov}(X, Y) + \theta^2\mbox{Var}(X) \end{aligned} \]
To minimize \(\mbox{Var}(Y_{\text{cuped}})\), we choose
\[ \theta = \frac{\mbox{Cov}(X, Y)}{\mbox{Var}(X)} \]Then \(\mbox{Var}(Y_{\text{cuped}})_{\text{min}} = \mbox{Var}(Y)(1-\mbox{Corr}(X,Y))\)
- \(Y\) is the outcome variable
- \(X\) is pre-experiment values of the outcome variable
- So, you’d need as many pre-experiment values as observed values during the experiment.
- …and potentially the same individuals? Probably not necessary but desirable.
- When no pre-experiment values of the outcome variable exist, a variable highly correlated to the outcome variable that’s NOT RELATED TO THE EXPERIMENT can be used.
- Like an instrument from an IV model.
- Can use ML to construct the control variate. (see CUPAC below)
- So, you’d need as many pre-experiment values as observed values during the experiment.
- Steps
- Randomly assign treatment to individuals
- Perform experiment
- Calculate \(\theta\) (eq.3)
- Calculate \(Y_{\text{cuped}}\) (eq.1)
- Calculate the effect size by taking the difference between the treated \(Y_{\text{cuped}}\) mean and the untreated \(Y_{\text{cuped}}\) mean
Variance-Weighted Estimators
- Variance is reduced by calculating a weighted variance based on the variance of an individual’s pre-experiment data
\[ \begin{aligned} &Y_i = \alpha + \delta_i Z_i + \epsilon_i \\ &\quad \text{where} \; \epsilon_i \sim \mathcal{N}(0, \sigma_i^2)\\ &\mbox{Var}(\hat \delta) = \sum_{i} w_i^2 \mbox{Var}(\delta_i) = \sum_{i} w_i^2 \sigma_i^2 \end{aligned} \]- \(Y\) is the outcome variable
- \(Z\) is the treatment indicator
- \(\delta\) is the treatment effect
- \(\sigma_i^2\) is the pre-experiment variance of individual \(i\)’s data
- Alternative ways of estimating the variance include ML models and using Empirical Bayes estimators (Paper)
- Steps
- Calculate individual variances, \(\sigma_i^2\)
- Bucket individuals into \(k\) strata based on their variances
- Calculate the mean of each strata’s variance, stratak_mean_variance
- Randomly assign treatment to individuals
- Perform experiment
- For each strata
- Calculate the effect for each strata by taking the difference between the treated mean \(Y\) and untreated mean \(Y\)
- Calculate strata weight
\[ w_k = \frac{1}{\text{strata}_k \_\text{mean\_variance}} \] - Calculate weighted effect for strata \(k\), \(\delta_{w,k} = \delta_k w_k\)
- Calculate variance weighted treatment effect by adding all the weighted effects and dividing it by the sum of the weights
\[ \delta_w = \frac{\sum\delta_{w,k}}{\sum w_k} \]
- Pros and Cons
- The variance-weighted estimator models individual pre-experiment variance as weight and it can be used as a nice extension to other methods such as CUPED.
- I guess you just calculate (\(k \cdot Y_{\text{cuped}}\)) and then do the weighting procedure. \(\theta\) and \(X\) shouldn’t be affected — just some grouped calculations.
- It works well when there is a highly skewed variance between users and when the pre-treatment variance is a good indicator of the post-treatment variance.
- Not sure what exactly is meant by “highly skewed variance between users.” Most users have high or most users have low variance for the pre-experiment data?
- When the variance of the pre-treatment variance is low or when the pre- and post-experiment variances are not consistent, the variance-weighted estimator might not work.
- The variance-weighted estimator is not unbiased. Managing bias is important for this method.
- The variance-weighted estimator models individual pre-experiment variance as weight and it can be used as a nice extension to other methods such as CUPED.
CUPAC
- Control Using Predictions As Covariates
- ML extension of CUPED (Paper)
- Assuming we have pre-experiment metrics, X1, X2, X3, and X4. Essentially, what this method does is to use some machine learning model to predict Y using X1, X2, X3, and X4. And then, we can use the predicted value as the control covariate in CUPED.
MLRATE
- Machine Learning Regression-Adjusted Treatment Effect Estimator
- Also see
- Does the same thing as CUPAC to get the control covariate, but instead using the CUPED equation with θ to get Ycuped, it estimates Ycuped using OLS regression.
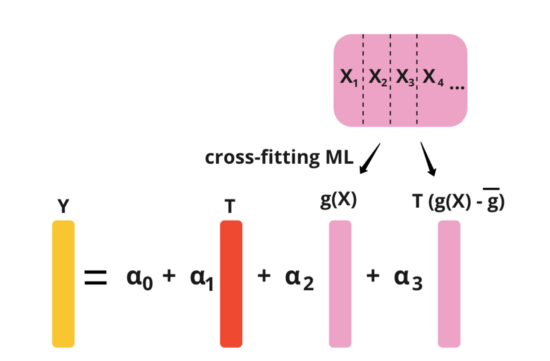
- See Introducing MLRATE article for more details