Stepped Wedge Cluster Design
I doubt this is entirely coherent. I didn’t really understand much about experimental design and mixed effects models at the time. I need to go back through the articles, reorganize the note, and add more.
Misc
- Notes from
- Packages
- {mediateSWCRT} (Paper) - Mediation Analysis in a Stepped Wedge Cluster Randomized Trials
- {steppedwedge} - Analyze Data from Stepped Wedge Cluster Randomized Trials
Description
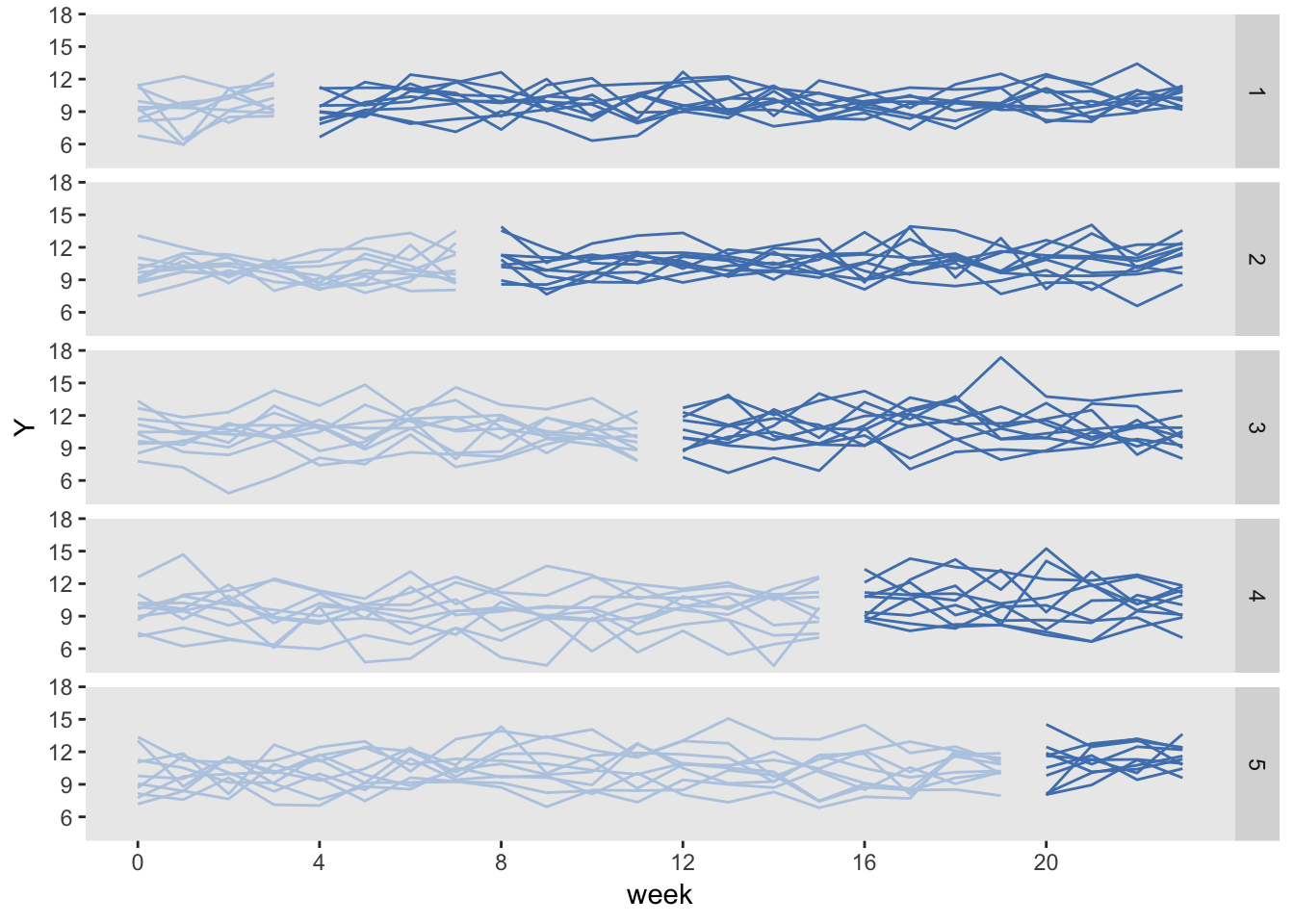
In the example, the study lasts 24 weeks and is conducted using 50 total sites (geographical locations). Each site will include six patients per week [the “per week” just means each site will have 6 total subjects participating each week as part of control or later in the treatment]. That means if we are collecting data for all sites over the entire study period, we will have 24×6×50=7200 outcome measurements.
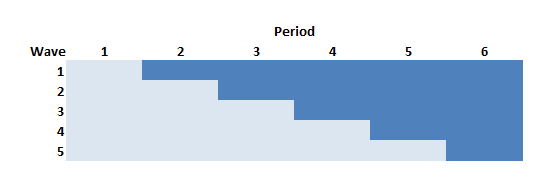
In the stepped-wedge design, all clusters [I think the clusters are the “waves”] in a trial will receive the intervention at some point, but the start of the intervention will be staggered. The amount of time in each state (control or intervention) will differ for each site (or group of sites if there are waves of more than one site starting up at the same time).
In this design (and in the others as well) time is divided into discrete data collection/phase-in periods. In the schematic figure, the light blue sections are periods during which the sites are in a control state, and the darker blue are periods during which the sites are in the intervention state. Each period in this case is 4 weeks long.
Following the Thompson et al. paper, the periods can be characterized as pre-rollout (where no intervention occurs), rollout (where the intervention is introduced over time), and post-rollout (where the all clusters are under intervention). Here, the rollout period includes periods two through five.
Stepped Wedge with Rollout-Only
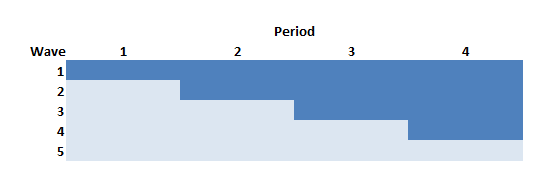
The Thompson et al. paper argued that if we limit the study to the rollout period only (periods 2 through 5 in the example above) but increase the length of the periods (here, from 4 to 6 weeks), we can actually increase power. In this case, there will be one wave of 10 sites that never receives the intervention.
The data generation process is exactly the same as above, except the statement defining the length of periods (6 weeks instead of 4 weeks) and starting point (week 0 vs. week 4) is slightly changed
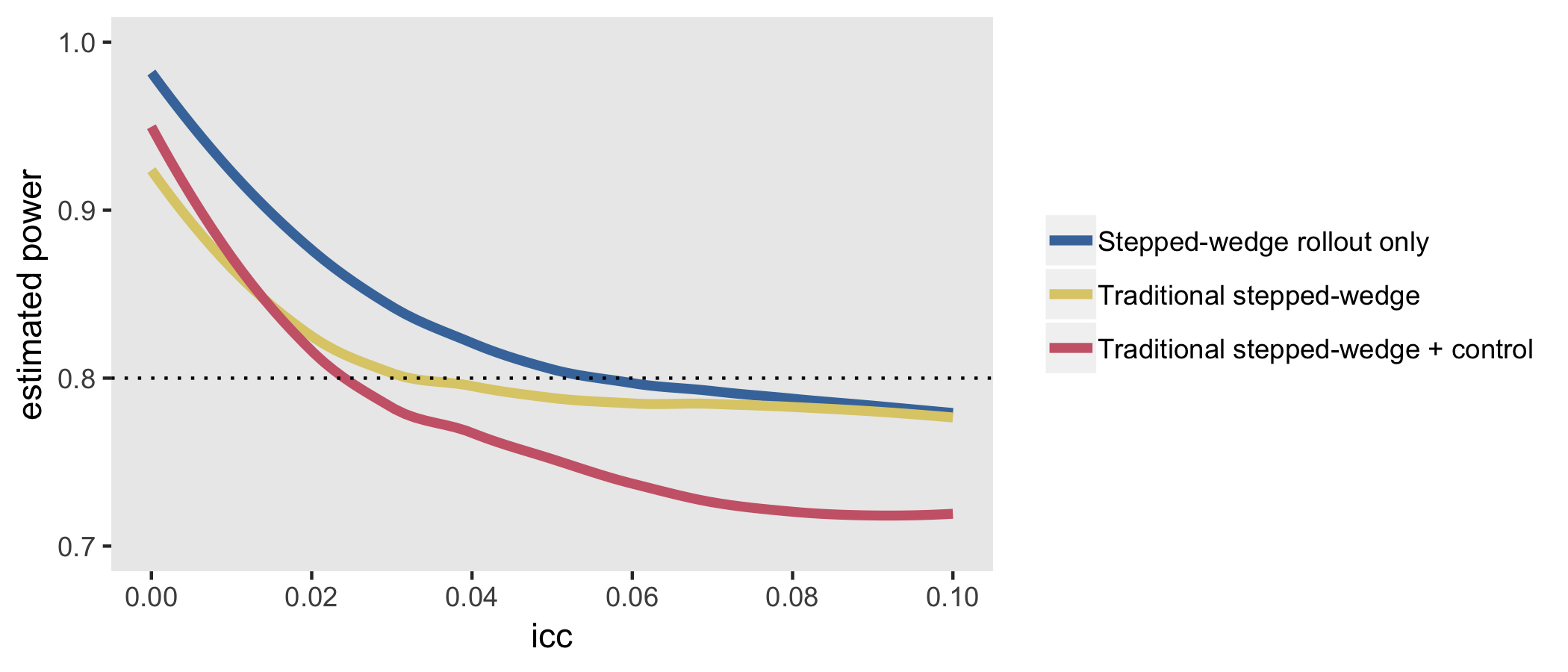
Stepped wedge with rollout maintains power best as the inter-class correlation (ICC) increases between sites
Stepped Wedge vs. Cluster Randomized Trial (CRT)
CRT is a traditional parallel design unlike the stepped design that’s been discussed
The simulations confirm findings that the CRT is more efficient than stepped-wedge designs when the ICC is close to zero, but pales in comparison even with ICCs as low as 0.01.
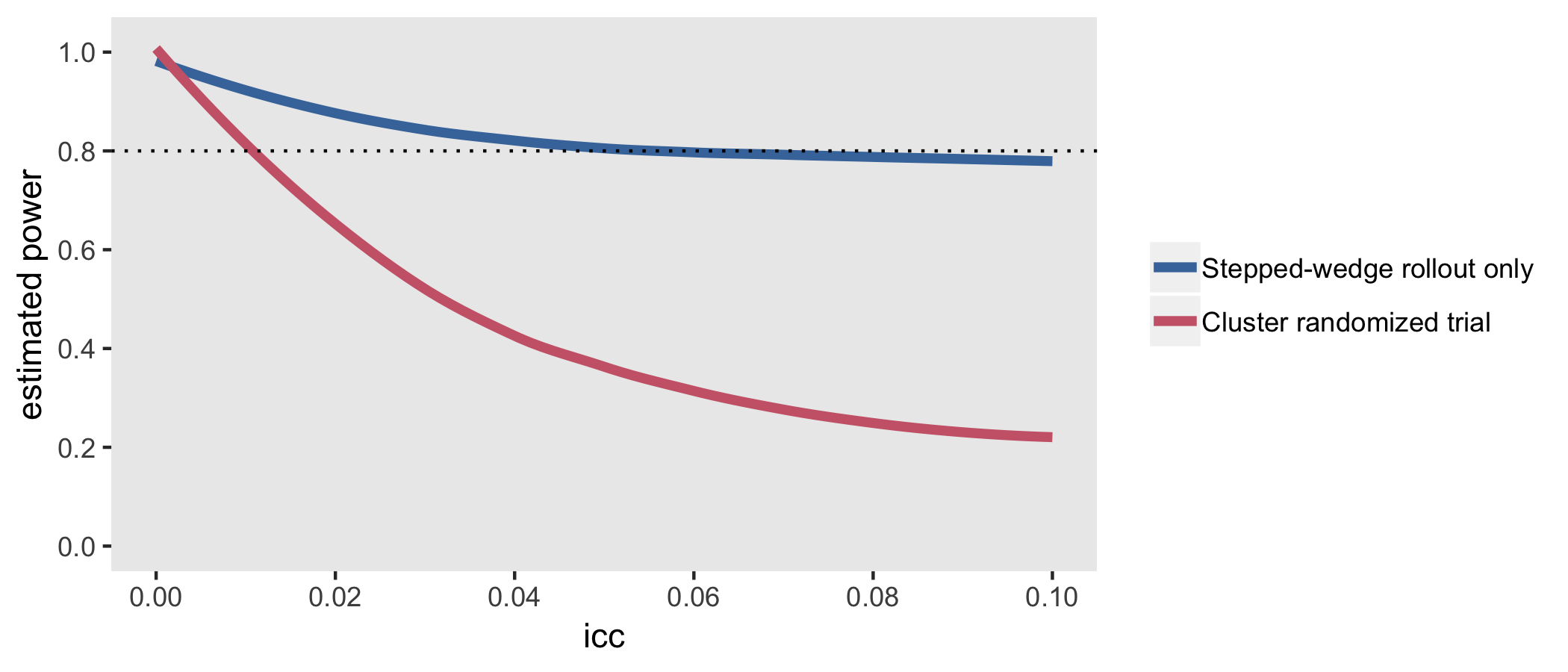
Intra-cluster correlation (ICC) across time periods
- Notes from Planning a stepped-wedge trial? Make sure you know what you’re assuming about intra-cluster correlations
- Moving beyond the parallel design (CRT design above) to the stepped-wedge design, time starts to play a very important role. It is important to ensure that we do not confound treatment and time effects; we have to be careful that we do not attribute the_general_changes over time to the intervention. This is accomplished by introducing a time trend into the model. (Actually, it seems more common to include a time-specific effect [dummy vars for each period I assume] so that each time period has its own effect. However, for simulation purposes, I will assume a linear trend.)
- In the stepped-wedge design, we are essentially estimating within-cluster treatment effects by comparing the cluster with itself pre- and post-intervention. To estimate sample size and precision (or power), it is no longer sufficient to consider a single ICC, because there are now multiple ICC’s - the within-period ICC and the between-period ICC’s. The within-period ICC is what we defined in the parallel design [standard ICC definition in my notebook](since we effectively treated all observations as occurring in the same period.) Now we also need to consider the expected correlation of two individuals in the same cluster in different time periods.
- If we do not properly account for within-period ICC and the between-period ICC’s in either the planning or analysis stages, we run the risk of generating biased estimates.
- Side note: according to the standard ICC equation, we can say that correlation between any two subjects in a cluster increases as the variation between clusters increases
Modeling
Traditional Parallel Clustered Design (e.g. CRT above)
- Notes from Planning a stepped-wedge trial? Make sure you know what you’re assuming about intra-cluster correlations
- Random Effects Model
\[ y_{ic} = \mu + \beta_1 X_c + b_c + e_{ic} \]- \(y_{ic}\) - A continuous outcome for subject \(i\) in cluster \(c\)
- \(X_c\) - A treatment indicator for cluster \(c\) (either 0 or 1)
- \(\mu\) - The grand mean, and
- \(\beta_1\) - The treatment effect
- \(b_c∼ \mathcal{N}(0,\sigma_b^2)\) - Normally distributed group level effect
- \(e_{ic} ∼ N(0, \sigma_e^2)\) - Normally distributed individual-level effect.
- Often referred to as the “error” term, but that doesn’t adequately describe what is really unmeasured individual variation.
- Intra-Cluster Correlation
\[ \text{ICC} = \frac{\sigma_b^2}{\sigma_b^2 + \sigma_e^2} \]
Constant (and equal) ICCs over time
Assumes that the within-period ICC and between-period ICCs are equal and constant throughout the study
Mixed Effects Model
\[ y_{ict} = \mu + \beta_0 t + \beta_1 X_{ct} + b_c + e_{ict} \]- The key differences between this model compared to the parallel design is the time trend and time-dependent treatment indicator. The time trend accounts for the fact that the outcome may change over time regardless of the intervention. And since the cluster will be in both the control and intervention states we need to have an time-dependent intervention indicator.
Within- and Between- Period ICC
\[ \text{ICC}_{tt} = \text{ICC}_{tt'} = \frac{\sigma_b^2}{\sigma_b^2 + \sigma_e^2} \]- Between-period ICC means we are estimating the expected correlation between any two subjects i and j in cluster c, one in time period t and the other in time period \(t'\) where (\(t \ne t′\)). So correlations are being calculated between all pair-wise combinations of the periods. Not just between \(t\) and \(t+1\) but also \(t\) and \(t+2\), etc.
- https://www.rdatagen.net/post/estimating-treatment-effects-and-iccs-for-stepped-wedge-designs/
Example
library(lme4) lmerfit <- lmer(Y ~ period + rx + (1| cluster), data = dx) vars <-as.data.frame(VarCorr(lmerfit))$vcov iccest <- round(vars[1]/(sum(vars)), 3)
Different Within- and Between-Period ICCs
https://www.rdatagen.net/post/varying-intra-cluster-correlations-over-time/
Instead of a single cluster level effect, \(b_c\), we have a vector of correlated cluster/time specific effects, \(b_{ct}\).The vector \(b_c\) has a multivariate normal distribution \(N(0,(σ_b^2)*R)\).These cluster-specific random effects, (\(b_c1, b_c2, …, b_cT\)) replace \(b_c\), and the slightly modified data generating model. I think \(T\) is the number of periods.
Mixed Effects Model
\[ y_{ict} = \mu + \beta_0 t + \beta_1 X_{ct} + b_{ct} + e_{ict} \]How we specify \(r_0\) and \(r\) reflects different assumptions about the between-period intra-cluster correlations.
\[ R = \begin{pmatrix} 1 & r_0r & r_0r^2 & \cdots & r_0r^{T-1} \\ r_0r & 1 & r_0r & \cdots & r_0r^{T-2} \\ r_0r^2 & r_0r & 1 & \cdots & r_0r^{T-3} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ r_0r^{T-1} & r_0r^{T-2} & r_0r^{T-3} & \cdots & 1 \end{pmatrix} \]- See \(b_{ct}\) distribution specification above
Within-Period ICC (Same as before)
\[ \text{ICC}_{tt} = \frac{\sigma_b^2}{\sigma_b^2 + \sigma_e^2} \]Between-Period ICC
\[ \text{ICC}_{tt'} = \frac{\sigma_b^2}{\sigma_b^2 + \sigma_e^2} r_{tt'} \]Case 1: In this first case, the correlation between individuals in the same cluster but different time periods is less than the correlation between individuals in the same cluster and same time period. In other words, \(\text{ICC}_{tt} \ne \text{ICC}_{tt'}\) . What’s described is actually \(\text{ICC}_{tt} \gt \text{ICC}_{tt'}\) but that still follows them being “not equal.” However the between-period correlation is constant, or in other words, \(\text{ICC}_{tt′}\) are constant for all \(t\) and \(t′\).
So the correlation between individuals within-period is different than between-period but the between-period correlation is the equal for each pair of periods. We have these correlations when \(r_0 = \rho\) and \(r = 1\), such that
\[ R = R(\rho,1)= \begin{pmatrix} 1 & \rho & \rho & \cdots & \rho \\ \rho & 1 & \rho & \cdots & \rho \\ \rho & \rho & 1 & \cdots & \rho \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ \rho & \rho & \rho & \cdots & 1 \end{pmatrix} \]
Example
library(lme4) lmerfit <- lmer(Y ~ period + rx + (1| cluster/period) , data = dcs)
The cluster-level period-specific effects are specified in the model as “cluster/period”, which indicates that the period effects are nested within the cluster.
Bayes models for estimation in stepped-wedge trials with non-trivial ICC patterns
Extracting period:cluster variance (\(\sigma_w^2\)), the cluster variance (\(\sigma_v^2\)), and the residual (individual level) variance (\(\sigma_e^2\)) from the model fit allows us to estimate cluster level effects (\(ρ\)), the within-period \(\text{ICC}_{tt}\), and the between-period \(\text{ICC}_{tt'}\). Don’t confuse \(\rho\) with the ICC. \(\rho\) is the correlation between the cluster-level period-specific random effects.
\[ \rho = \frac{\sigma_{\nu}^2}{\sigma_{\nu}^2 + \sigma_{w}^2} \]Example
vs <- as.data.table(VarCorr(lmerfit))$vcov rho <- vs[2]/sum(vs[1:2])
The within-period ICC is the ratio of total cluster variance relative to total variance
\[ \text{ICC}_{tt} = \frac{\sigma_{\nu}^2 + \sigma_{w}^2}{\sigma_{\nu}^2 + \sigma_{w}^2 + \sigma_{e}^2} \]Example
iccw <- sum(vs[1:2])/sum(vs
The between-period \(\text{ICC}_{tt'}\) is really just the within-period \(\text{ICC}_{tt}\) adjusted by \(\rho\)
\[ \text{ICC}_{tt'} = \frac{\sigma_{\nu}^2}{\sigma_{\nu}^2 + \sigma_{w}^2 + \sigma_{e}^2} \](the result of ICC_tt * ρ)
iccb <- vs[2]/sum(vs)Case 2: The correlation between individuals in the same cluster degrades over time [the change from case 1 is time-varying, between-period correlation. \(\text{ICC}_{tt}\) remains not equal to \(\text{ICC}_{tt'}\). Here, the correlation between two individuals in adjacent time periods is stronger than the correlation between individuals in periods further apart. That is \(\text{ICC}_{tt'} \gt \text{ICC}_{tt''}\) if \(|t' - t| < |t'' - t|\). This structure can be created by setting \(r_0 = 1\) and \(r = ρ\),
\[ R = R(1, \rho)= \begin{pmatrix} 1 & \rho & \rho^2 & \cdots & \rho_{T-1} \\ \rho & 1 & \rho & \cdots & \rho_{T-2} \\ \rho^2 & \rho & 1 & \cdots & \rho_{T-3} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ \rho_{T-1} & \rho_{T-2} & \rho_{T-3} & \cdots & 1 \end{pmatrix} \]- Last article linked also models this case using {rstan}