Vector Databases
Misc
Vector databases store embeddings and provide fast similarity searches
Packages
Vector search can cost more than LLM API calls (source)
- The computational demands of vector are often one to two orders of magnitude higher than what you’d see in a typical NoSQL database.
Superlinked Comparison (link): Prices, features, etc.
Comparison (link)
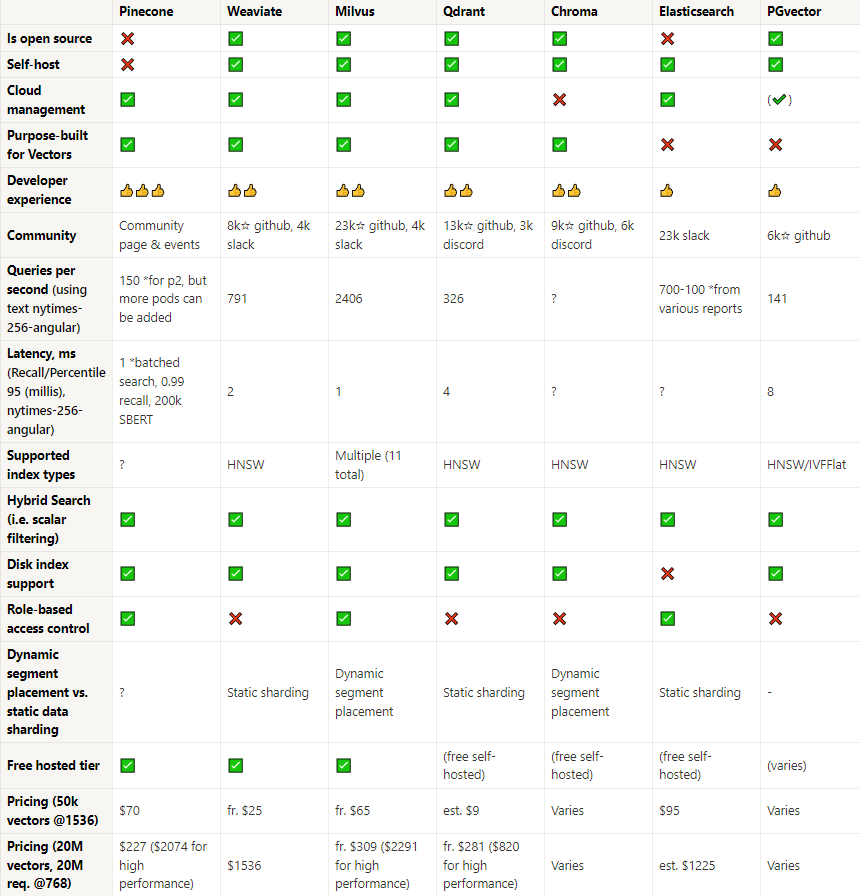
- Open-Source and hosted cloud: If you lean towards open-source solutions, Weviate, Milvus, and Chroma emerge as top contenders. Pinecone, although not open-source, shines with its developer experience and a robust fully hosted solution.
- Performance: When it comes to raw performance in queries per second, Milvus takes the lead, closely followed by Weviate and Qdrant. However, in terms of latency, Pinecone and Milvus both offer impressive sub-2ms results. If nmultiple pods are added for pinecone, then much higher QPS can be reached.
- Community Strength: Milvus boasts the largest community presence, followed by Weviate and Elasticsearch. A strong community often translates to better support, enhancements, and bug fixes.
- Scalability, advanced features and security: Role-based access control, a feature crucial for many enterprise applications, is found in Pinecone, Milvus, and Elasticsearch. On the scaling front, dynamic segment placement is offered by Milvus and Chroma, making them suitable for ever-evolving datasets. If you’re in need of a database with a wide array of index types, Milvus’ support for 11 different types is unmatched. While hybrid search is well-supported across the board, Elasticsearch does fall short in terms of disk index support.
- Pricing: For startups or projects on a budget, Qdrant’s estimated $9 pricing for 50k vectors is hard to beat. On the other end of the spectrum, for larger projects requiring high performance, Pinecone and Milvus offer competitive pricing tiers.
Brands
- Weaviate, FAISS
- Qdrant - open source, free, and easy to use (example)
- Chroma - Can be used as a local in-memory (example)
- Chroma image with built-in support for multiple state-of-the-art embedding models, enabling superior semantic search across PDFs, source code, and documentation with store-optimized chunking strategies
- Pinecone - Data Elixir is using this store for their chatbot; has a free tier
- Postgres with pgvector: Supports exact and approximate nearest neighbor search; L2 distance, inner product, and cosine distance; any language with a Postgres client
- Also see Databases, PostgreSQL >> Extensions >> pgvector and pg_sparse for sparse embeddings (e.g. SPLADE)
- Milvus - An open-source vector database built for GenAI applications. Install with pip, perform high-speed searches, and scale to tens of billions of vectors with minimal performance loss.
- Zilliz - Managed cloud hosting service for Milvus
- Features
- High-performance search and recommendation: If your application needs sub-50ms latency.
- High-volume writes or frequent updates
- Complex query workloads: Support for hybrid search, aggregations, or other advanced querying features.
- Multi-tenant production apps deployments.
- Tiered Storage
- Hot Data Layer (<50ms) – This is where real-time search, recommendations, and targeted ads live. Latency needs to be under 50ms, which means specialized vector databases are still the best option. They’re optimized for both blazing speed and high query throughput.
- Warm Data Layer (50–500ms) – Many RAG-based applications and multi-tenant shared services fall here. These workloads don’t need ultra-low latency, but they do need predictable performance at lower cost. S3 Vectors and Milvus’s tiered storage instances fit this middle ground.
- Cold Data Layer (>500ms) – Historical archives and offline analysis don’t require real-time responses, so latency in the hundreds of milliseconds is acceptable. What matters here is cost efficiency at massive scale. This is where solutions like S3 + Spark/Daft or the Milvus vector data lake shine.
- AWS S3 Vectors
- S3 backed vector storage
- Docs
- Notes from Zilliz article
- Storage runs at just $0.06/GB, roughly 5 times cheaper than most serverless vector solutions.
- For a representative workload—say 400 million vectors plus 10 million queries per month—the bill comes out to about $1,217/month. That’s more than a 10x reduction compared to traditional vector databases.
- Limitations
- Collection size limits: Each S3 table maxes out at 50M vectors, and you can only create up to 10,000 tables.
- Cold queries: Latency comes in at ~500ms for 1M vectors and ~700ms for 10M vectors.
- Hot queries: Latency stays under 200ms at 200 QPS, but pushing beyond that 200 QPS ceiling is tough.
- Write performance: Capped at under 2MB/s. That’s orders of magnitude lower than Milvus (which handles GB/s), though to its credit, writes don’t degrade query performance. Translation: it’s not designed for scenarios with large, frequently changing datasets.
- Recall hovers at 85–90%, and you don’t get knobs to tune it higher. Layer on filters, and recall can drop below 50%
- TopK queries max out at 30. Metadata per record has strict size limits. And you won’t find features like hybrid search, multi-tenancy, or advanced filtering—all of which are must-haves for many production applications.
- Use Cases
- Cold data archiving: Perfect for storing history datasets that are rarely accessed. If you can live with 500ms+ query times, the cost savings are unbeatable.
- Low-QPS RAG queries: Think of small internal tools or chatbots that run only dozens of queries per day, staying under 100 QPS. For these use cases, latency isn’t a dealbreaker.
- Low-cost prototyping: Great for proof-of-concept projects where the goal is to test an idea without spending heavily on infrastructure.