JSON
Misc
Packages
- {dir2json} - A utility for converting directories into JSON format and decoding JSON back into directory structures
- Handles a variety of file types within the directory, including text and binary files (e.g., images, PDFs),
- {orjson} - A fast, correct JSON library for Python. It benchmarks as the fastest Python library for JSON and is more correct than the standard json library or other third-party python libraries. It serializes dataclass, datetime, numpy, and UUID instances natively.
- {RcppSimdJson} - Comparable to {yyjsonr} in performance.
- Might be faster than yyjsonr for very large / nested data
- {rlowdb} - A lightweight, file-based JSON database. Inspired by ‘LowDB’ in ‘JavaScript’, it generates an intuitive interface for storing, retrieving, updating, and querying structured data without requiring a full-fledged database system.
- {tibblify} - Rectangle deeply nested lists into a tidy tibble. These lists might come from an API in the form of JSON or from scraping XML.
- {unnest} - A zero-dependency R package for a very fast single-copy and single-pass unnesting of hierarchical data structures.
- {yyjsonr} - A fast JSON parser/serializer, which converts R data to/from JSON and NDJSON. It is around 2x to 10x faster than jsonlite at both reading and writing JSON.
- {dir2json} - A utility for converting directories into JSON format and decoding JSON back into directory structures
Also see
- Big Data >> Larger than Memory
- SQL >> Processing Expressions >> Nested Data
- Databases >> DuckDB >> Misc
- hrbmstr recommends trying duckdb before using the cli tools in “Big Data”
Read from a URL
Example: {RCCPSimdJson} (source)
url <- "https://projects.fivethirtyeight.com/polls/president-general/2024/national/polls.json" polls_raw <- RcppSimdJson::fload(url) dplyr::glimpse(polls_raw)
Don’t parse an JSON response to a string from an API
Responses are binary. It’s more performant to read the binary directly than to parse the response into a string and then read the string
Example: {yyjsonr} (source)
library(httr2) # format request req <- request("https://jsonplaceholder.typicode.com/users") # send request and get response resp <- req_perform(req) # translate binary to json your_json <- yyjsonr::read_json_raw(resp_body_raw(resp))- Faster than the httr2/jsonlite default,
resp_body_json
- Faster than the httr2/jsonlite default,
Tools
{listviewer} allows you to interactively explore and edit json files through the Viewer in the IDE. Docs show how it can be embedded into a Shiny app as well.
Example
library(listviewer) moose <- jsonlite::read_json("path/to/file.json") jsonedit(moose) reactjson(moose)- I’ve also used this a .config file which looked like a json file when I opened in a text editor, so this seems to work on anything json-like.
reactjsonhas a copy button which is nice so that you can paste your edited version into a file.jsoneditseems like it has more features, but I didn’t see a copy button. But there’s a view in which you can manually select everything a copy it via keyboard shortcut.
{xfun::tabset} (Intro) allows you to interactively explore a nested object as a set of nested tabs
Python
json.toolmodulepython -m json.tool /home/trey/Downloads/download.json- Pretty prints a json file from CLI
{jsonlite}
Read
flights <- jsonlite::read_json( "https://tidyverse.r-universe.dev/nycflights13/data/flights/json", simplifyVector = TRUE )Write
jsonlite::stream_out( tibble( day = days, title = titles, sections = sections, md = markdown, urls = urls ), gzfile("/tmp/drops.json.gz") )
{tidyr}
From flattened json to nested json
library(tidyr) items <- list( list(loc = 1, type = "a", val = 3), list(loc = 1, type = "b", v1 = 4, note = "foo" ), list(loc = 2, type = "a", val = 3)) # desired format: nested by "loc" # list( # list(loc = 1, items = list( # list(type = “a”, val = 3), # list(type = “b”, v1 = 4, note = “foo”)), # list(loc=2, items = list( # list(type = “a”, val = 3))) ls_grouped <- tibble(json = items) |> 1 hoist(json, loc = "loc") |> 2 nest(.by = "loc", .key = "items") |> dplyr::mutate(items = purrr::map(items, \(x) as.list(x[[1]]))) |> 3 purrr::transpose() 4json_nested <- tibble(json = items) |> hoist(json, loc = "loc") |> nest(.by = "loc", .key = "items") |> dplyr::mutate(items = purrr::map(items, \(x) as.list(x[[1]]))) |> jsonlite::toJSON() |> jsonlite::prettify()- 1
-
hoistacts likepurrr::pluckfor a list-column, and pulls the loc element out of each list cell and into a column - 2
-
nestperforms a sort ofgroup_splitfunction that gathers all the columns and nests them according to the loc value. The output column, items, is a column of dataframes. - 3
-
transposeconverts the tibble (which has columns loc and items) into a list structure where each element represents one row, effectively giving the desired nested list structure. This implementation oftransposeis different from other examples of its use, but the conversion from a column-wise structure to a row-wise structure is its primary purpose which is essentially what’s happening here. - 4
-
Removing the
transposeline and addingtoJSONcoerces the tibble into a nested json.
Python
- Example: Parse Nested JSON into a dataframe (article)
Raw JSON
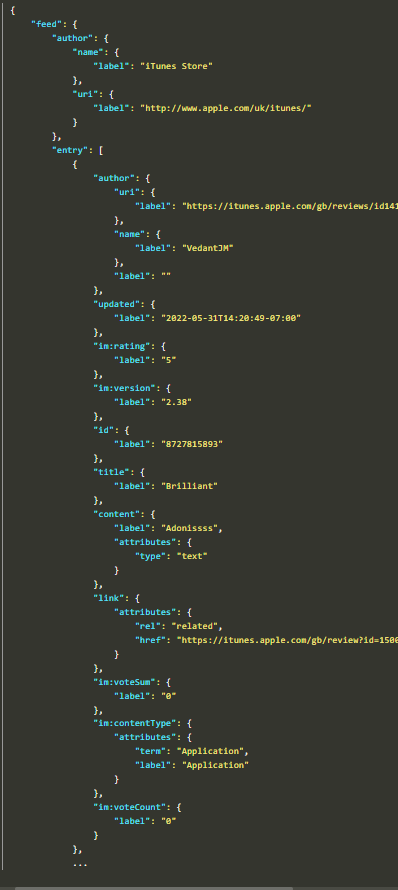
- “entry” has the data we want
- “…” at the end indicates there are multiple objectss inside the element, “entry”
- Probably other root elements other than “feed” as well
Read a json file from a URL using {{requests}} and convert to list
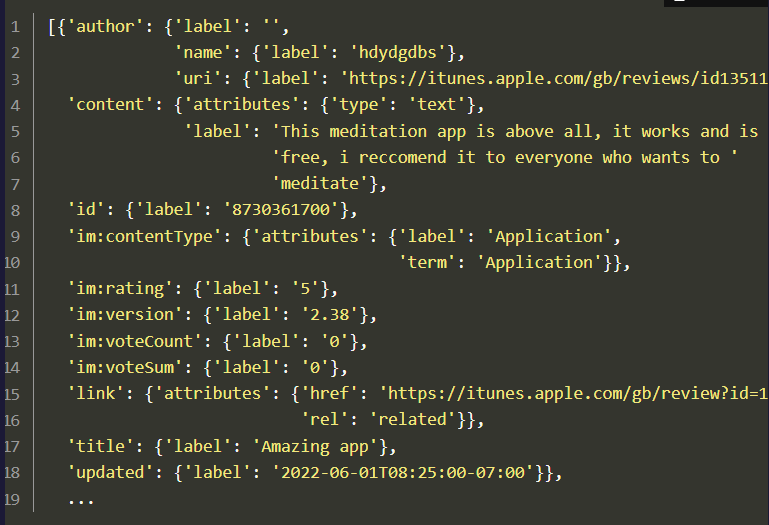
import requests url = "https://itunes.apple.com/gb/rss/customerreviews/id=1500780518/sortBy=mostRecent/json" r = requests.get(url) data = r.json() entries = data["feed"]["entry"]- It looks like the list conversion also ordered the elements alphabetically
- The output list is subsetted by the root element “feed” and the child element “entry”
Get a feel for the final structure you want by hardcoding elements into a df
parsed_data = defaultdict(list) for entry in entries: parsed_data["author_uri"].append(entry["author"]["uri"]["label"]) parsed_data["author_name"].append(entry["author"]["name"]["label"]) parsed_data["author_label"].append(entry["author"]["label"]) parsed_data["content_label"].append(entry["content"]["label"]) parsed_data["content_attributes_type"].append(entry["content"]["attributes"]["type"]) ...Generalize extracting the properties of each object in “entry” with a nested loop
parsed_data = defaultdict(list) for entry in entries: for key, val in entry.items(): for subkey, subval in val.items(): if not isinstance(subval, dict): parsed_data[f"{key}_{subkey}"].append(subval) else: for att_key, att_val in subval.items(): parsed_data[f"{key}_{subkey}_{att_key}"].append(att_val)defaultdictcreates a key from a list element (e.g. “author”) and groups the properties into a list of values where the value may also be a dict.- See Python, General >> Types >> Dictionaries
- For each item in “entry”, it looks at the first key-value pair knowing that value is always a dictionary (object in JSON)
- Then handles two different cases
- First Case: The value dictionary is flat and does not contain another dictionary, only key-value pairs.
- Combine the outer key with the inner key to a column name and take the value as column value for each pair.
- Second Case: Dictionary contains a key-value pair where the value is again a dictionary.
- Assumes at most two levels of nested dictionaries
- Iterates over the key-value pairs of the inner dictionary and again combines the outer key and the most inner key to a column name and take the inner value as column value.
- First Case: The value dictionary is flat and does not contain another dictionary, only key-value pairs.
Recursive function that handles json elements with deeper structures
def recursive_parser(entry: dict, data_dict: dict, col_name: str = "") -> dict: """Recursive parser for a list of nested JSON objects Args: entry (dict): A dictionary representing a single entry (row) of the final data frame. data_dict (dict): Accumulator holding the current parsed data. col_name (str): Accumulator holding the current column name. Defaults to empty string. """ for key, val in entry.items(): extended_col_name = f"{col_name}_{key}" if col_name else key if isinstance(val, dict): recursive_parser(entry[key], data_dict, extended_col_name) else: data_dict[extended_col_name].append(val) parsed_data = defaultdict(list) for entry in entries: recursive_parser(entry, parsed_data, "") df = pd.DataFrame(parsed_data)- Notice the check for a deeper structure with
isinstance. If there is one, then the function is called again. - Function outputs a dict which is coerced into dataframe
- To get rid of “label” in column names:
df.columns = [col if not "label" in col else "_".join(col.split("_")[:-1]) for col in df.columns] objecttypes can be cast into more efficient types:df["im:rating"] = df["im:rating"].astype(int)
- Notice the check for a deeper structure with
DuckDB
- Misc
- Notes from
- Resource
- -json flag says output as json instead of a sql query output
- The output kind of looks like a scrunched up dictionary. So, you can pipe that into a CLI tool like jq (if you have it installed) (e.g.
<query with -json> | jq) to get pretty printing
- The output kind of looks like a scrunched up dictionary. So, you can pipe that into a CLI tool like jq (if you have it installed) (e.g.
- Read JSON from a URL in a query:
from read_json('https://api.github.com/orgs/golang/repos')
- CLI
Example 1
Data: Types of open source licenses used in golang repo
[ { "id": 1914329, "name": "gddo", "license": { "key": "bsd-3-clause", "name": "BSD 3-Clause \"New\" or \"Revised\" License", ... }, ... }, { "id": 11440704, "name": "glog", "license": { "key": "apache-2.0", "name": "Apache License 2.0", ... }, ... }, ... ]Count most common license types used
duckdb -c \ "select license->>'key' as license, count(*) as count \ from 'repos.json' \ group by 1 \ order by count desc" ┌──────────────┬───────┐ │ license │ count │ │ varchar │ int64 │ ├──────────────┼───────┤ │ bsd-3-clause │ 23 │ │ apache-2.0 │ 5 │ │ │ 2 │ └──────────────┴───────┘- The bottom license with count = 2 is
null(i.e. no licence) ->>is used to drill down into a nested json field. (e.g. license to key)
- The bottom license with count = 2 is
- {duckdb}
Example: Reading JSON from a Connection or File (source)
library(duckdb) library(dplyr) con <- dbConnect(duckdb()) dbExecute(con, "INSTALL json; LOAD json; INSTALL httpfs; LOAD httpfs;") dbGetQuery(con, " SELECT id, name, username, email, address.street as street FROM read_json('https://jsonplaceholder.typicode.com/users'); ") |> filter(id < 5)
- {duckplyr}
- Read:
read_json_duckdb
- Read: