Concepts
Packages
- {BORG} - Automatically detects and enforces valid model evaluation by identifying information reuse between training and evaluation data. Guards against data leakage, look-ahead bias, and invalid cross-validation schemes that inflate performance estimates. Supports temporal, spatial, and grouped evaluation structures
- {broom} supported model classes
- {fastml} - Wrapper around tidymodels for quick iteration. Also includes diagnostic packages (e.g. dalex, naniar)
- {leakr} - Provides utilities to detect common data leakage patterns including train/test contamination, temporal leakage, and data duplication, enhancing model reliability and reproducibility in machine learning workflows
- Generates diagnostic reports and visual summaries to support data validation
- {multiverse} - Makes it easy to specify and execute all combinations of reasonable analyses of a dataset


- {mverse} - Tidy Multiverse Analysis Made Simple
- An extension to {multiverse} that’s adds an extra layer of abstraction. It’s designed to allow piping and takes hints from the ‘tidyverse’ grammar. The package allows users to define and inspect multiverse analysis using familiar syntax in R.
- {rtemis} - Not quite automl but somewhere between mlr3/tidymodels and automl. Has all the main algorithms for regression (including tabnet), classification, and clustering. Uses plotly for visualization (eda and model diagnostics). Has data check function (missingness, character vectors, etc.). The preprocessing function seems a little basic but includes imputing. The imputing function uses a couple packages that include PMM, so not bad. Overall it’s hard to criticize this package too much.
- {tidyAML} - Automated Machine Learning (AutoML) to the tidymodels ecosystem.
Papers
There is only one correct analysis (Lakens et al 2026)
- Criticizes the multiverse approach
Regression Workflow (Paper)
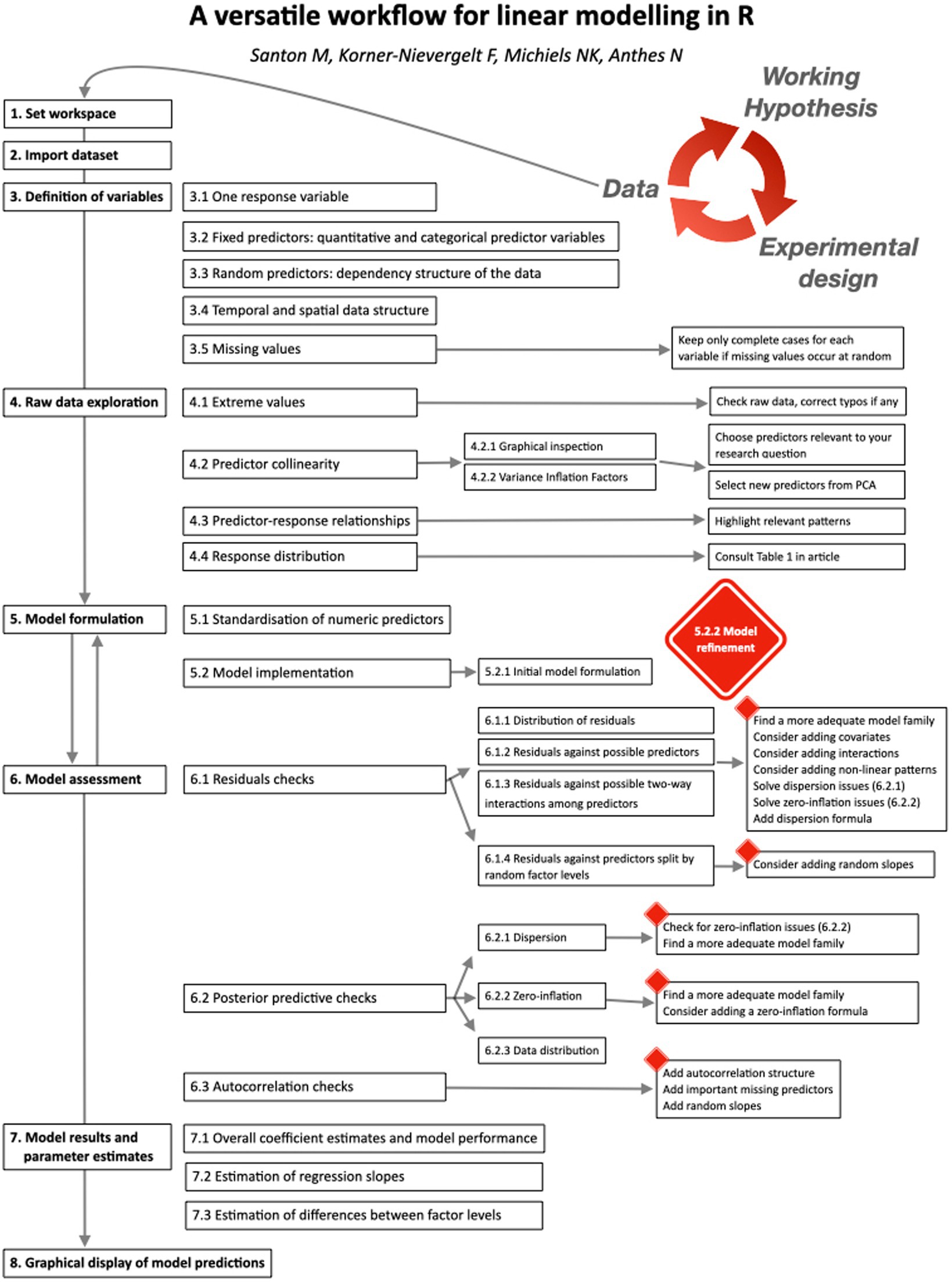
ML Workflow
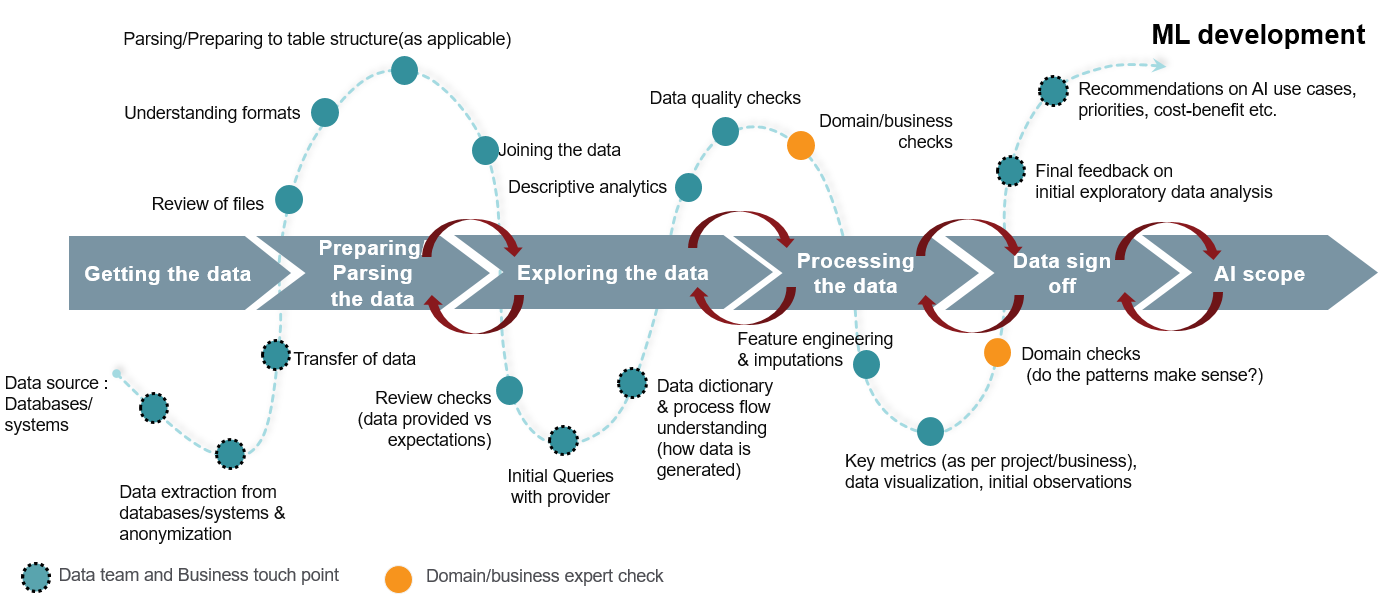
Sources of Data Leakage (article)
- Feature Leakage - Often happens with features that are directly related to the target and exist as a result of the target event. Normally, feature leakage happens because the feature value is updated in a point in time after the target event.
- Always ask: “At the exact moment of prediction, does this specific database row actually contain this value yet?”
- Examples:
- You are trying to predict loan default of a certain customer and one of your features is the number of outbound calls (i.e. calls from the bank) that the customer had in past 30 days. What you don’t know is that in this fictional bank the customer receives outbound calls only after they’ve entered into a default scenario.
- You are trying to predict a certain disease of a patient and are using the number of times the patient went through a specific diagnostic test. However, you later find that this test is only prescribed to people after it’s been determined that they have a high likelihood of having the disease.
- Churn: Imagine you’re predicting which users will cancel their subscription. Your training data has a feature called Last_Login_Date. The database team has set up a trigger that “clears” the login date field the moment a user hits the “Cancel” button. Your model sees a “Null” login date and realizes, “Aha! They canceled!” In the real world, at the exact millisecond the model needs to make a prediction before the user cancels, that field isn’t Null yet. Therefore, the model is looking at the answer from the future.
- Data Splits (See Cross-Validation >> K-Fold >> Misc)
- Distributional statistics used in transformations of the training set should be used in transformations of the validation and test sets. eg. scaling/standardization/normalization.
- Imputation should happen after the train/test split.
- Perform outlier analysis (i.e. if removing rows) only on the training set.
- Subsampling for class imbalance should only be on the training set. (See Classification >> Class Imbalance >> CV)
- Duplicate Rows (See EDA, General >> Preprocessing)
- Checks
- Fit an extremely shallow decision tree and check if one of the features has an enormous difference, in terms of importance, compared to others
- If there is a time stamp, you might be able to determine if certain feature values (indicator or counts) occur very close to the event time (e.g. churn, loan default).
- Feature Leakage - Often happens with features that are directly related to the target and exist as a result of the target event. Normally, feature leakage happens because the feature value is updated in a point in time after the target event.
Make ML model pipelines reusable and reproducible
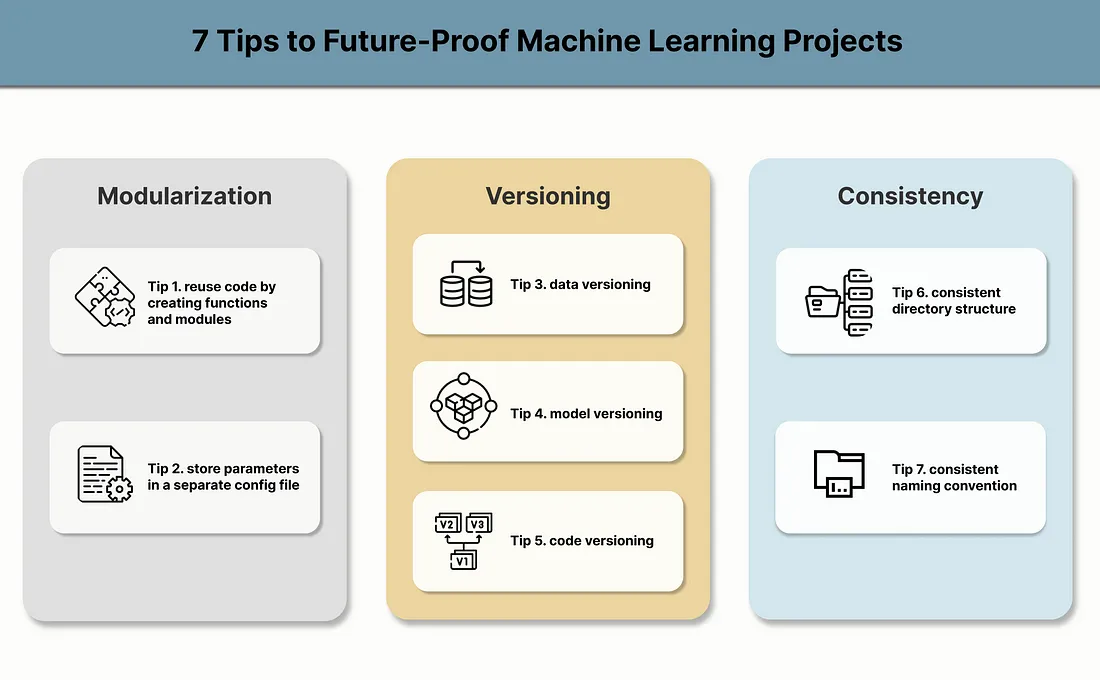
- Notes from 7 Tips to Future-Proof Machine Learning Projects
- Modularization - Useful for debugging and iteration
- Don’t used declarative programming. Create functions/classes for preprocessing, training, tuning, etc., and keep in separate files. You’ll call these functions in the main script
Helper function
## file preprocessing.py ## def data_preparation(data): data = data.drop(['Evaporation', 'Sunshine', 'Cloud3pm', 'Cloud9am'], axis=1) numeric_cols = ['MinTemp', 'MaxTemp', 'Rainfall', 'WindGustSpeed', 'WindSpeed9am'] data[numeric_cols] = data[numeric_cols].fillna(data[numeric_cols].mean()) data['Month'] = pd.to_datetime(data['Date']).dt.month.apply(str) return dataMain script
from preprocessing import data_preparation train_preprocessed = data_preparation(train_data) inference_preprocessed = data_preparation(inference_data)
- Keep parameters in a separate config file
Config file
## parameters.py ## DROP_COLS = ['Evaporation', 'Sunshine', 'Cloud3pm', 'Cloud9am'] NUM_COLS = ['MinTemp', 'MaxTemp', 'Rainfall', 'WindGustSpeed', 'WindSpeed9am']Proprocessing script
## preprocessing.py ## from parameters import DROP_COLS, NUM_COLS def data_preparation(data): data = data.drop(DROP_COLS, axis=1) data[NUM_COLS] = data[NUM_COLS].fillna(data[NUM_COLS].mean()) data['Month'] = pd.to_datetime(data['Date']).dt.month.apply(str) return data
- Don’t used declarative programming. Create functions/classes for preprocessing, training, tuning, etc., and keep in separate files. You’ll call these functions in the main script
- Versioning Code, Data, and Models - Useful for investigating drift
- See tools like DVC, MLFlow, Weights and Biases, etc. for model and data versioning
- Important to save data snapshots throughout the project lifecycle, for example: raw data, processed data, train data, validation data, test data and inference data.
- Github and dbt for code versioning
- See tools like DVC, MLFlow, Weights and Biases, etc. for model and data versioning
- Consistent Structures - Consistency in project structures and naming can reduce human error, improve communication, and just make things easier to find.
Naming examples:
<model-name>-<parameters>-<model-version><model-name>-<data-version>-<use-case>
Example: Reduced project template based on {{cookiecutter}}
├── data │ ├── output <- The output data from the model. │ ├── processed <- The final, canonical data sets for modeling. │ └── raw <- The original, immutable data dump. │ ├── models <- Trained and serialized models, model predictions, or model summaries │ ├── notebooks <- Jupyter notebooks. │ ├── reports <- Generated analysis as HTML, PDF, LaTeX, etc. │ └── figures <- Generated graphics and figures to be used in reporting │ ├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g. │ generated with `pip freeze > requirements.txt` │ ├── code <- Source code for use in this project. ├── __init__.py <- Makes src a Python module │ ├── data <- Scripts to generate and process data │ ├── data_preparation.py │ └── data_preprocessing.py │ ├── models <- Scripts to train models and then use trained models to make │ │ predictions │ ├── inference_model.py │ └── train_model.py │ └── analysis <- Scripts to create exploratory and results oriented visualizations └── analysis.pyExample: (source)
Project Structure
<project-name> |-- data # where data is stored |-- conf # where config files for your pipelines are stored |-- src # all the code to replicate your project is stored here |-- notebooks # all the code for one-off experiments, explorations, etc. are stored here |-- tests # all the tests are stored here |-- pyproject.toml |-- README.md |-- requirements.txtTesting Structure
src |-- pipelines |-- data_processing.py |-- feature_engineering.py |-- model_training.py |-- __init__.py tests |-- pipelines |-- test_data_processing.py |-- test_feature_engineering.py |-- test_model_training.py
Sparse Data Representation
- Also see
- Model Building, tidymodels >> Misc >> Utilizing a sparse matrix
- Mathematics, Linear Algebra >> Misc >> {sparsevctrs}
- Estimates, model performance metrics, etc. are unaffected
- Advantages
- Speed is gained from any specialized model algorithms built for sparse data.
- The amount of memory this object requires decreases dramatically.
- e.g. A dataset as a sparse matrix (transformed via {Matrix}) that’s been saved to a rds file takes up around 1MB compressed, and around 12MB once loaded into R. If it were turned into a dense matrix, it would take up 3GB of memory. (source)
- Example:
c(0, 0, 1, 0, 3, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)- It could be represented sparsely using the 3 values
positions = c(1, 3, 7),values = c(3, 5, 8), andlength = 20.
- It could be represented sparsely using the 3 values
- Also see
Model is performing well on the training set but much worse on the validation/test set

- Andrew Ng calls the validation set the “Dev Set” 🙄
- Test: Random sample the training set and use that as your validation set. Score your model on this new validation set
- “Train-Dev” is the sampled validation set
- Possibilities
- Variance: The data distribution of the training set is the same as the validation/test sets

- The model has been overfit to the training data
- Data Mismatch: The data distribution of the training set is NOT the same as the validation/test sets

- Unlucky and the split was bad
- Something maybe is wrong with the splitting function
- Split ratio needs adjusting. Validation set isn’t getting enough data to be representative.
- Unlucky and the split was bad
- Variance: The data distribution of the training set is the same as the validation/test sets
Model is performing well on the validation/test set but not in the real world
- Investigate the validation/test set and figure out why it’s not reflecting real world data. Then, apply corrections to the dataset.
- e.g. distributions of your validation/tests sets should look like the real world data.
- Change the metric
- Consider weighting cases that your model is performing extremely poorly on.
- Investigate the validation/test set and figure out why it’s not reflecting real world data. Then, apply corrections to the dataset.
Splits
- Harrell: “not appropriate to split data into training and test sets unless n>20,000 because of the luck (or bad luck) of the split.”
- If your dataset is over 1M rows, then having a test set of 200K might be overkill (e.g. ratio of 60/20/20).
- Might be better to use a ratio of 98/1/1 for big data projects and 60/20/20 for smaller data projects
- link
- Shows that simple data splitting does not give valid confidence intervals (even asymptotically) when one refits the model on the whole dataset. Thus, if one wants valid confidence intervals for prediction error, we can only recommend either data splitting without refitting the model (which is viable when one has ample data), or nested CV.
Seeds
Notes from Fine-grained control of RNG seeds in R
Functions can change the state of the RNG
- 1
-
Store the state of the RNG after setting it with
set.seed - 2
-
After calling
samplethe second time, we see it outputs a different permutation. This is because each timesampleis called it changes the state of the RNG. - 3
-
After setting the RNG to it’s original state,
sampleoutputs the orignial permutation
To keep the same seed for a function or chunk of code, wrap it in
withr::with_seedset.seed(1) sample(10) #> [1] 9 4 7 1 2 5 3 10 6 8 sample(10) #> [1] 3 1 5 8 2 6 10 9 4 7 withr::with_seed(1, sample(10) ) #> [1] 9 4 7 1 2 5 3 10 6 8 withr::with_seed(1, { sample(10) sample(10) } ) #> [1] 3 1 5 8 2 6 10 9 4 7- If you wrap a chunk of code, be aware if you call more than one function that uses the RNG, you’re back in the original situation.
with_seeddoes not freeze the RNG state for each function called in the chunk.
- If you wrap a chunk of code, be aware if you call more than one function that uses the RNG, you’re back in the original situation.
Online Learning
- Models that operate on data streams
- Packages
- {river} - Online machine learning
- {deep-river} (JOSS) - Online deep learning
- {DLSSM} - Dynamic Logistic State Space Prediction Model
- Provides a computationally efficient way to update the prediction whenever new data becomes available.
- The model is updated using batch data accumulated at pre-specified time intervals.
- It allows for both time-varying and time-invariant coefficients, and use cubic smoothing splines to model varying coefficients.
- Provides a computationally efficient way to update the prediction whenever new data becomes available.
- Reactive Data Streams - Streams that you don’t have control of.
- e.g. A user visits your website. That’s out of your control. You have no influence on the event. It just happens and you have to react to it.
- Proactive Data Streams - Streams that you have control of.
- e.g. Reading the data from a file. You decide at which speed you want to read the data, in what order, etc.
- The challenge for traditional model training is to ensure the models that you train offline on proactive datasets will perform correctly in production on reactive data streams.
- An online model is trained one sample at a time. It’s a stateful, dynamic object that keeps learning and doesn’t have to revisit past data.
- Online model evaluation involves learning and inference in the same order as what would happen in production. If you know the order in which your data arrives, then you can process it the exact same order. This allows you to replay a production scenario and evaluate your model.
- Online models adapt to concept drift in a seamless manner. As opposed to batch models which have to be retrained from scratch.