{mall} - Text analysis by using rows of a dataframe along with a pre-determined (depending on the function), one-shot prompt. The prompt + row gets sent to an Ollama LLM for the prediction
Also available in Python
Features
Sentiment analysis
Text summarizing
Classify text
Extract one, or several, specific pieces information from the text
Translate text
Verify that something it true about the text (binary)
Custom prompt
{quallmer} - Qualitative Analysis with Large Language Models
Provides a ‘codebook’-based workflow for defining coding instructions and applying them to texts, images, and other data.
Includes built-in ‘codebooks’ for common applications such as sentiment analysis and policy coding, and functions for creating custom ‘codebooks’ for specific research questions.
Computes inter-coder reliability statistics including Krippendorff’s alpha and Fleiss’ kappa along with accuracy, precision, recall, and F1 scores
Provides audit trail functionality for documenting coding workflows for establishing trustworthiness of research
{quallmer.app} - Companion package to ‘quallmer’ providing an interactive ‘shiny’ application for manual coding, reviewing large language model (LLM) generated annotations, and computing inter-rater reliability metrics
{rbm25} - BM25 is a ranking function used by search engines to rank matching documents according to their relevance to a user’s search query.
Cleans and formats ordered text (monologues and dialogues)
Cleans and formats unordered word lists (e.g., bags-of-words)
Computes pairwise semantic distance metrics using numerous chunking options
Finds clustering solutions and creates simple semantic networks from given word list vectors.
{tall} - Shiny app that imports a text and performs a wide range of analyses.
Features a comprehensive workflow, including data cleaning, preprocessing, statistical analysis, and visualization, all integrated for effective text analysis
Automatic Lemmatization and Part-of-Speech (PoS)-Tagging through LLM
Descriptive statistics, concordance analysis and word frequency distributions
Topic Detection through hierarchical clustering, correspondence analysis, network analysis
Written in C++ and provides a source-agnostic streaming API, which allows researchers to perform analysis of collections of documents which are larger than available RAM. Functions are also parallelizable.
Coallocations (phrase learning) for word embeddings and topic modeling
GloVe: word embeddings algorithm
Topic Modeling with LSA and LDA
Document Similarity
{textpress} - A lightweight, versatile NLP package for R, focused on search-centric workflows with minimal dependencies and easy data-frame integration. Uses Huggingface API.
Web Search: Perform search engine queries to retrieve relevant URLs.
Web Scraping: Extract URL content, including some relevant metadata.
Text Processing & Chunking: Segment text into meaningful units, eg, sentences, paragraphs, and larger chunks. Designed to support tasks related to retrieval-augmented generation (RAG).
Corpus Search: Perform keyword, phrase, and pattern-based searches across processed corpora, supporting both traditional in-context search techniques (e.g., KWIC, regex matching) and advanced semantic searches using embeddings.
Embedding Generation: Generate embeddings using the HuggingFace API for enhanced semantic search.
Uses Compressed Sparse Row (CSR) type of sparse matrix
Uses a time series cv folds and scores by precision
Precision because “Amazon would be more concerned about the products with negative reviews rather than positive reviews”
Says random search > grid search with regularized regression
Also fits a model with Tf-idf instead of BoW
Preprocess
Tokenize
Remove stopwords and punctuation
Stem
unigrams and bigrams
Sparse token count matrix
Normalize the matrix
Model with regularized logistic regression
GPT-4
Accepts prompts of 25,000 words (GPT-3 accepted 1500-2000 words)
Allegedly around 1T parameters (GPT-3 had 175B parameters)
Some use cases: translation, q/a, text summaries, writing/getting news, creative writing
Multi-modal training data (i.e. text and audio, pictures, etc.)
Still hallucinates
Terms
Flood Words - Words that are too common in the domain (i.e. noise)
Hypernym - A word with a broad meaning constituting a category into which words with more specific meanings fall
Example: A device can use multiple storage units such as a hard drive or CD
hyponym of storage units: hard drive, cd
hypernym of hard drive/cd: storage units
Hyponym - Opposite of Hypernym; a word of more specific meaning than a general term applicable to it.
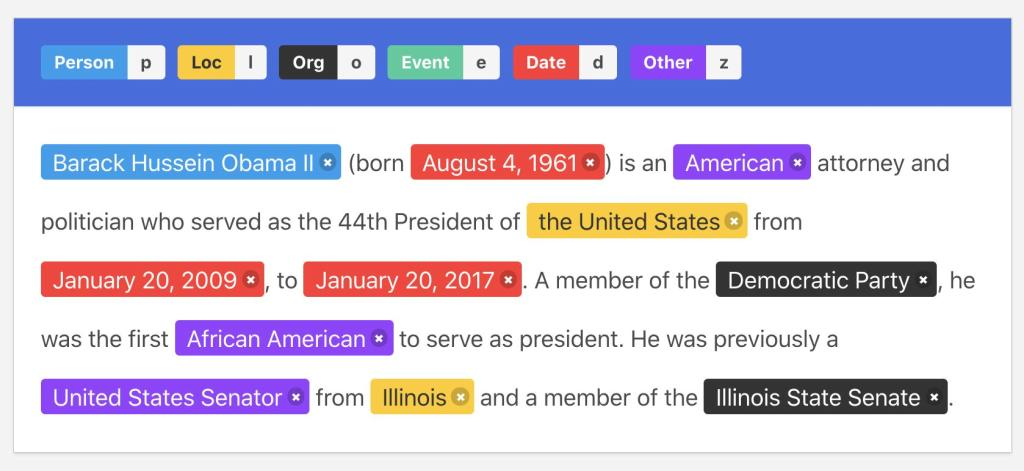
Named Entity Recognition (NER) - A subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Example: An automated NER system will identify the incoming customer request (e.g. installation, maintenance, complaint, and troubleshoot of a particular product) and send it to the respective support desk
aka Named Entity Identification, Entity Chunking, and Entity Extraction
Other use cases: filtering resumés, diagnose patients based on symptoms in healthcare data
Sequence to Sequence (aka String Transduction) - problems where the input and output is text
e.g. Text summarization, Text simplification, Question answering, Chatbots, Machine translation
Spam Words - Words that don’t belong in the domain (i.e. noise)
Hearst Patterns
A set of test patterns that can be employed to extract Hypernyms and Hyponyms from text.
In the table, X is the hypernym and Y is the hyponym
“rhyper” stands for reverse-hyper
Usually, you don’t want to extract all possible hyponyms relations, but only entities in the specific domain
Prompt: Column name; sample of data from that column.
Completion: metadata which is a tag that includes column attributes.
Potential Improvements
Trying other models (‘ada’ used here) to see if this improves performance (though it will cost more)
Model hyperparameter tuning. The log probability cutoff will likely be very important
More prompt engineering to perhaps include column list on the table might provide better context, we well as overlying columns on two-row header tables.
More preprocessing. Not much was done for this article, blindly taking tables extracted from CSV files, so the data is can be a bit messy
GPT-4 resulted in 96% accuracy when predicting category and 89% accuracy when predicting both category and sub-category.
GPT-3.5-turbo for the same prompts, with 96% accuracy versus 66% for category.
Limitations exist due to the maximum number of tokens allowed in prompts affecting the amount of data that can be included in data excerpts, as well as performance and cost challenges — especially if you’re a small non-profit! — at this early stage of commercial generative AI.
Likely related to being an early preview, GPT-4 model performance was very slow, taking 20 seconds per prompt to complete
Note: most of these use a combination of the others to improve their overall performance — a document clustering model might use topic extraction and NER to improve the quality of their clusters.
Recommendation Engines: Bespoke recommendation engines can be fine-tuned to recommend related documentation that may not be within the user’s immediate sphere of interest, but still relevant.
Enables the discovery of “unknown unknowns”.
Topic extraction and Document clustering: generate topics from multiple texts and detect similarities between documents publishing by dozens, sometimes hundred information feeds.
You don’t have the time to read every single document to get a higher view of the main problematics evolving within your multiple information feeds
Named (and unnamed) Entity Extraction and Disambiguation (NER / NED) (see Terms): identifying and categorizing named entities
The extraction part involves locating and tagging entities, while the disambiguation part involves determining the correct identity or meaning of an entity, especially when it can have multiple interpretations or references in a text.
Allow you to build entire NLP logics to keep tracks of meaningful facts about this entity, order it by timeliness and relevance. This will allow you to start building bespoke, expert curated profiles.
Relationship Extraction: identify the nature and type of relationships between different entities, such as individuals, organizations, and locations, and to represent them in a structured format that can be easily analyzed and interpreted.
Generating accurate connections between across thousands of documents will build expert driven, queryable knowledge graphs in a matter of days
Multi-document abstractive summarization: automatically generated a concise and coherent summary of multiple documents on a given topic, by creating new sentences that capture the most important information from the original texts.
Enable users to obtain a concise and coherent summary of the most important information from a large amount of text data.