Feature Selection
Misc
- Why?
- Reduces chances of overfitting
- Multicollinearity among predictors blows up std.errors in regression
- Lowers computer resources requirements and increase speed
- Packages
- {important} (Intro) - Uses feature importance methods for selection and works within the tidymodels framework
- Incorporates {filtro} scores within the model selection workflow
- Currently supports:
- ANOVA F-test
- Correlation (pearson, spearman)
- Random forest feature importance
- Information gain
- Area under the ROC curve
- Cross tabulation (Chi-squared test and Fisher’s exact test)
- Currently supports:
- Features
- Any performance metrics from the yardstick package can be used.
- Importance can be calculated for either the original columns or at the level of any derived model terms created during feature engineering.
- The computations that loop across permutation iterations and predictors columns are easily parallelized.
- Selection Functions
step_predictors_retain()can filter the predictors using a single conditional statement (e.g., absolute correlation with the outcome > 0.75, etc).step_predictors_best()can retain the most important predictors for the outcome using a single scoring function.step_predictors_desirability()retains the most important predictors for the outcome using multiple scoring functions, blended using desirability functions.
- Incorporates {filtro} scores within the model selection workflow
- {mlr3filters} - Various algorithms for feature selection for {mlr3pipelines} and implemented in {mlr3select}
- {MFSIS} - An implementation of popular screening methods that are commonly employed in ultra-high and high dimensional data.
- {rpc} - Computes the ridge partial correlation coefficients in a high or ultra-high dimensional linear regression problem. An extended Bayesian information criterion is also implemented for variable selection
- {Rdimtools} - Has many algorithms for feature selection
- {important} (Intro) - Uses feature importance methods for selection and works within the tidymodels framework
- Never use stepwise (backwards, forwards, etc.) for selecting variables according to statistical significance (e.g. p-value, or reduce the Akaike Information Criterion, or increase adjusted R-squared, or in fact any other data-driven statistics) for prediction or inferential models.
- See Step Away From Stepwise, Stepwise selection of variables in regression is Evil
- Some real explanatory variables that have causal effects on the dependent variable may happen to not be statistically significant, while nuisance variables may be coincidentally significant. As a result, the model may fit the data well in-sample, but do poorly out-of-sample.
- Stepwise regression is less effective the larger the number of potential explanatory variables.
- False positives go up and estimates are biased away from zero
- From Harrell’s RMS
- The R-squared or even adjusted R-squared values of the end model are biased high.
- The F and Chi-square test statistics of the final model do not have the claimed distribution.
- The standard errors of coefficient estimates are biased low and confidence intervals for effects and predictions are falsely narrow.
- The p values are too small (there are severe multiple comparison problems in addition to problems 2. and 3.) and do not have the proper meaning, and it is difficult to correct for this.
- The regression coefficients are biased high in absolute value and need shrinkage but this is rarely done.
- Variable selection is made arbitrary by collinearity.
- It allows us to not think about the problem.
Basic
- Harrell: Use the full model unless p > m/15 (i.e. number_of_columns > number_of_rows / 15)
- If p > m/15, then use regularized regression (See Regression, Regularized)
- See Harrell’s checklist for other options.
- VIF - Eliminate low variance predictors
- See EDA, General >> Correlation/Association >> Multicollinearity >> Variance Decomposition Proportions
- {collinear::vif_select} - Automatizes multicollinearity filtering in data frames with numeric predictors by combining two methods:
- Preference Order: A method to rank and preserve relevant variables during multicollinearity filtering.
- VIF-based filtering: A recursive algorithm to identify and remove predictors with a VIF above a given threshold.
- Remove Noisy Features - Compare correlation between a variable in training set and same variable in test set
- Best subset
- {lmSubsets}: for linear regression; computes best set of predictors by fitting all subsets; chooses based on metric (AIC, BIC, etc.)
- {leaps::regsubsets} performs best subset selection for regression models using RSS. summary(obj) gives best subset of variables for different sized subsets. nvmax arg can be used set the max size of the subsets.
- Likelihood Ratio Test (LR Test) - For a pair of nested models, the difference in −2ln L values has a χ2 distribution, with degrees of freedom equal to the difference in number of parameters estimated in the models being compared.
- If multicollinearity is a problem
- Reduction methods - PCA, Partial Least Squares (PLS)
- Shrinkage methods - Ridge, SLOPE, Least Angle Regression (LAR)
- ML
- Fuzzy Forests (See below)
- Oblique Forests
- Article on {bonsai} implementation of {aorsf} through {tidymodels}
- Regression, Survival >> ML >> Random Survival Forests >> {aorsf}
Bayesian Model Averaging (BMA)
- Packages
- {badp} - Implements Bayesian model averaging for dynamic panels with weakly exogenous regressors
- {BMS} - Bayesian Model Averaging for linear models with a wide choice of (customizable) priors.
- {bayestestR::bf_inclusion} (Vignette) - Inclusion Bayes Factors for testing predictors across Bayesian models
- Answers the question, “Are the observed data more probable under models with a particular predictor, than they are under models without that particular predictor?”
- {BayesFactor} - A suite of functions for computing various Bayes factors for simple designs, including contingency tables, one- and two-sample designs, one-way designs, general ANOVA designs, and linear regression
- Can be used with {bayestestR::bf_inclusion}. See vignette.
- {FBMS} (Vignette)- Flexible Bayesian Model Selection and Model Averaging
- Implements an efficient Mode Jumping Markov Chain Monte Carlo (MJMCMC) algorithm, designed to improve mixing in multi-modal posterior landscapes within Bayesian generalized linear models
- Provides a genetically modified MJMCMC (GMJMCMC) algorithm that introduces nonlinear feature generation, thereby enabling the estimation of Bayesian generalized nonlinear models (BGNLMs)
- Supports generalized linear and nonlinear models, mixed-effects models, and survival models
- {rmsBMA} - Implements Bayesian model averaging for settings with many candidate regressors relative to the available sample size, including cases where the number of regressors exceeds the number of observations.
- BMA estimates models for all possible combinations of your explanatory variables and constructs a weighted average over all of them.
- Quantities of interest (model parameters or prediction probabilities, for instance) are computed as the mean of the estimates from several candidate models weighted by the posterior probability of each model given the data.
- If your set of explanatory variables has size K, then this means estimating 2K variable combinations and thus 2K models.
- The model weights for this averaging stem from posterior model probabilities that arise from Bayes’ theorem
- Various approximations, such as the WAIC can be used to compute the posterior probability of each model.
- In the frequentist approach, the weights can be proportional to Akaike’s information criterion (AIC) or achieved by minimization of the mean squared error
Others
- Sparse regression and classification via the Pivotal Information Criterion (PIC)
- {picreg}
- PIC is an alternative to the Bayesian Information Criterion (BIC), cross-validation, and Lasso-based tuning.
- The regularization parameter is selected from a pivotal null-distribution statistic, eliminating the need for cross-validation and yielding sharper support recovery.
- Provides Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) optimisation for the L1, Smoothly Clipped Absolute Deviation (SCAD), and Minimax Concave Penalty (MCP) penalties
- Six response distributions: Gaussian, binomial, Poisson, Exponential, Gumbel, and Cox
- Generalized Linear Step-up Procedure (GLSUP)
- {GLSUP}, Paper
- A setwise variable-selection framework that identifies clusters of potential predictors rather than forcing selection of a single variable
- Allows any member of a selected set to serve as a surrogate predictor which supports strong predictive performance while maintaining rigorous FDR control.
- Constructs sets via hierarchical clustering of predictors based on correlation, then tests whether each set contains any non-null effects.
- Competitive Adaptive Reweighted Sampling (CARS)
- {carsAlgo}
- Variable selection from high-dimensional dataset using Partial Least Squares (PLS) regression models
- Iteratively applies the Monte Carlo sub-sampling and exponential variable elimination techniques to identify/select the most informative variables/features subjected to minimal cross-validated RMSE score.
- Posterior Summarization with BART ensembles
- {BartVC} (Paper)
- Variable selection with tree ensembles often hinges on posterior summarization. Uses a VC-measure (Variable Count and its rank variant) with a clustering-based threshold
- When paired with the Dirichlet Additive Regression Tree (DART) , the method attains the best overall balance of recall, precision, and efficiency. (highest F1 score with varying amounts of data noise)
- Can be used with any BART variant, but there are trade-offs between precision, recall, selection stability, and computational efficiency with different BART variants excelling in different criteria.
- Permutation-based methods, especially BART VIP-G.SE ({bartMachine}), demonstrate strong and stable selection performance, ranking second or third in F1 in most settings, but come with a high computational cost.
- Feature Ordering by Conditional Independenc (FOCI)
- {FOCI} - Feature Ordering by Conditional Independence
FOCI::codeccalculates Chatterjee’s \(\xi\) coeffiicient if only two variables are provided
- Ranks a matrix of covariates, \(Z\), given a variable, \(X\), according to their marginal contribution in explaining a response variable \(Y\) from the most to the least significant contribution.
- Process
- Select the covariate (\(X\)) with the highest \(\xi\) estimate with the response (\(Y\)).
- Rank the remaining variables (\(Z\)) are evaluated based on their contribution conditioned on the first variable chosen.
- Continue until all the variables have been ranked or if the estimate provides a negative value.
- {FOCI} - Feature Ordering by Conditional Independence
- Adaptive Iterative Ridge High-dimensional Ordinary Least-squares Projection (Air-HOLP)
- {AirScreen} (Paper) - Feature Screening via Adaptive Iterative Ridge (Air-HOLP for n < p and Air-OLS for n > p)
- High-dimensional Ordinary Least-squares Projection (HOLP) but where the ridge-regularization tuning parameter is selected iteratively and optimally for better feature screening performance
- HOLP measures the joint dependence of features on the response rather than solely learning from the marginal information.
- Coordinate Descent and Local search for Mixed Models
- {glmmsel} - Generalised Linear Mixed Model Selection using L0 regularization
- Supports Gaussian and Binomial families
- {glmmsel} - Generalised Linear Mixed Model Selection using L0 regularization
- Feature Ordering by Integrated R square Dependence (FORD)
- {FORD} (Paper) - Variable selection algorithm based on the new measure of dependence: Integrated R2 Dependence Coefficient (IRDC)
- See Association, General >> Nonlinear >> Integrated R2 Dependence Coefficient (IRDC)
- Sparse Projected Averaged Regression (SPAR)
- {spareg} builds a predictive ensemble of sparse projected regression models for both discrete and continuous data in the GLM framework
- Procedure
- Variables are first screened based on a measure of the utility of each predictor for the response
- The selected variables are then projected to a lower dimensional space (smaller than n) using a random projection matrix
- A GLM is estimated using the projected predictors
- The final coefficients are then obtained by averaging over the marginal models in the ensemble
- SHARP
- Stability-enHanced Approaches using Resampling Procedures
- Facilitates Stability Selection (Supervised) and Consensus Clustering (Unsupervised). Can be used for stability-enhanced clustering, (multi-block) graphical modeling, regression, structural equation modeling, and dimensionality reduction.
- {sharp} (Vignette)
- Supervised: Subsamples data, fits a regularized model, measures feature importance. Repeat many times. The proportion of times a feature is above a threshold is it’s score. Then number of desired features is chosen from the features with the highest scores
- Unsupervised: Similar except instead of feature importance, cluster membership is used.
- Bayesian Adaptive Sampling
- Projection Predictive
- {projpred} (Vehtari)
- It is variable selection for various regression models, and also allows for valid post-selection inference
- Papers and other articles in bkmks >> Features >> Selection >> projpred
- Currently requires {rstanarm} or {brms} models
- Families: gaussian, binomial, poisson. Also categorical and ordinal
- Terms: linear main effects, interactions, multilevel, other additive terms
- Components
- Search: Determines the solution path, i.e., the best submodel for each submodel size (number of predictor terms).
- Evaluation: Determines the predictive performance of the submodels along the solution path
- After model selection, a matrix of projected posterior draws is produced using the reference model and the selected number of features. Then, typical posterior stats for variable effects can be calculated, visualized via {posterior}, {bayesplot}, etc.
- Projected Posterior Distribution - The distribution arising from the deterministic projection of the reference model’s posterior distribution onto the parameter space of the final submodel
- Also see Horseshoe model
- Multi-Layer Group-Lasso
- This approach combines variable aggregation and selection in order to improve interpretability and performance
- {MLGL}
- Goal is to remove redundant variables from a high dim dataset.
- Steps
- A hierarchical clustering procedure provides at each level a partition of the variables into groups.
- The set of groups of variables from the different levels of the hierarchy is given as input to group-Lasso, with weights adapted to the structure of the hierarchy.
- At this step, group-Lasso outputs sets of candidate groups of variables for each value of the regularization parameter
- Ensemble Ranking
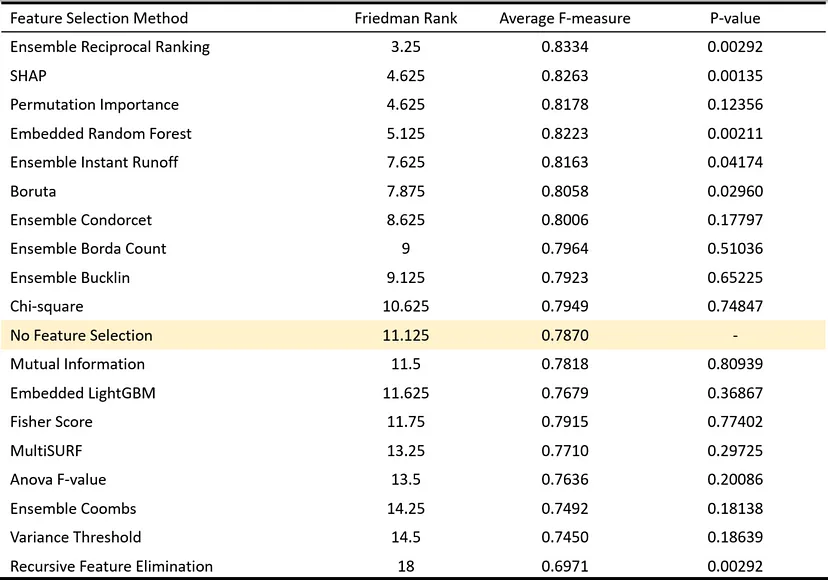
Apply multiple feature selection methods then create an ensemble ranking
-
- Compared 12 individual feature selection methods and the 6 ensemble methods described above in 8 datasets for a classification task
Best performance is Ensemble Reciprocal Ranking
\[r(f) = \frac{1}{\sum_j \frac{1}{r_j(f)}}\]
- \(r(f)\) is the final rank of feature \(f\)
- \(j\) is the the index for the feature selection methods
- Equivalent to the harmonic mean rank
- aka Inverse Rank Position
- Lower is better (I think)
- \(r(f)\) is the final rank of feature \(f\)
Best performance by single method is SHAP
- Boruta
- Built around random forest algorithm Can identify variables involved in non-linear interactions. Slow if dealing with thousands of variables
- {Boruta}
- Multivariable Fractional Polynomials
- Fits polynomial transformations of features with exponents in a range of numbers including fractions
- Includes a pretty intensive statistical model testing procedure
- {mfp}, Explainer
- Component-wise Boosting
- {bounceR}
- Article, Video
- Uses component-wise boosting from {mboost} to score features and selects features with aggregate scores beyond some kind of threshold.
- It’s not well-explained at all and there is only documentation on how to use it. I haven’t watched the video, so that could possibly explain the method better.
- See Algorithms, ML >> Boosting >> XGBoost for details on mboost’s algorithm
- Also has bivariate comparison methods: correlation, zero-variance, and information criteria
- Reversible Jump MCMC (RJMCMC)
- Variable selection in NIMBLE using reversible jump MCMC
- Brief explanation and example
- A general framework for MCMC simulation in which the dimension of the parameter space (i.e., the number of parameters) can vary between iterations of the Markov chain.
- Variable selection in NIMBLE using reversible jump MCMC
- Fuzzy Forests
- Extends Random Forest Feature Selection for Correlated, High-Dimensional Data
- {fuzzyforest}
- Uses recursive feature elimination random forests to select features from separate blocks of correlated features where the correlation within each block of features is high and the correlation between blocks of features is low.
- Then, one final random forest is fit using the surviving features.
- Gain Penalyzed Forests
Uses gain penalization to regularize the random forest algorithm
Think this also works for numeric target variables
Notes from
- Feature Selection via Gain Penalization in Random Forests
- Includes coded example
- Paper
- Feature Selection via Gain Penalization in Random Forests
When determining the next child node to be added to a decision tree, the gain (or the error reduction) of each feature is multiplied by a penalization parameter
\[\mbox{Gain}_R(\boldsymbol{X}_i, t) = \left\{ \begin{array}{lcl} \lambda \Delta(i, t) & i \notin \mathbb{U} \\ \Delta(i,t) & i\in \mathbb{U} \end{array}\right.\]
- \(U\) is the set of indices of the features previously used in the tree
- \(X_i\) is the candidate feature
- \(t\) is the candidate splitting point
- \(\lambda\) is the penalty for each variable, \(\lambda \in (0,1]\) (See below)
- So at each split point, variables that have NOT been chosen at prior split points receive a penalty
Penalty for each variable (the λ shown in the Gain equation above)
\[\lambda = (1-\gamma)\cdot\lambda_0 + \gamma \cdot g(x_i)\]
- \(\lambda_i \in [0,1)\)
- \(\lambda_0 \in [0,1)\) is interpreted as the baseline regularization
- \(\gamma \in [0,1)\) is the mixture parameter
- \(g(x_i)\) is a function of the ith feature
- Should represent relevant information about the feature, based on some characteristic of interest (correlation to the target, for example)
- Introduces “prior knowledge” regarding the importance of each feature into the model
- The data will tell us how strong our assumptions about the penalization are, since even if we try to penalize a truly important feature, its gain will be high enough to overcome the penalization and the feature will get selected by the algorithm
- Examples
- The Mutual Information between each feature and the target variable \(y\)
- Normalized to be between 0 and 1
- The variable importance values obtained from a previously run standard Random Forest, which is what I call a Boosted g(xi)
- Normalized to be between 0 and 1
- Other options, see the paper
- The Mutual Information between each feature and the target variable \(y\)
Steps
- We run a bunch of penalized random forests models with different hyperparameters and record their accuracies and final set of features
- \(\gamma\), \(\lambda_0\) and mtry are hyperparameters that should be tuned
- For each training dataset, select the top-n (e.g. n = 3) fitted models in terms of the accuracies, and run a “new” random forest for each of the feature sets used by them. This is done using all of the training sets so we can evaluate how these features perform in slightly different scenarios
- Finally, get the top-m set of models (here m = 30) from these new ones, check which features were the most used between them and run a final random forest model with this feature set.
- e.g. Select only the 15 most used features from the top 30 models, but both numbers can be changed depending on the situation
- We run a bunch of penalized random forests models with different hyperparameters and record their accuracies and final set of features
- Distance Correlation Forward Selection
- Also see Regression, Regularized >> Misc >> Variable Selection
- “The distance correlation algorithm for variable selection (DC.VS) of Febrero-Bande et al. (2019). This makes use of the correlation distance (Székely et al., 2007; Szekely & Rizzo, 2017) to implement an iterative procedure (forward) deciding in each step which covariate enters the regression model.”
- Starting from the null model, the distance correlation function, dcor.xy, in {fda.usc} is used to choose the next covariate
- Guessing you want large distances between an already chosen variable and the next variable
- Maybe for the first explanatory variable you want a short distance between the it and the outcome variable
- Dunno what the stopping criteria is
- Algorithm discussed in this paper, Variable selection in Functional Additive Regression Models
Multidimensional Feature Selection (MDFS)
Misc
Description
Compares tuples of variables using entropy/information gain (see below for details on the algorithm)
A filter method which means it identifies informative variables before modelling is performed.
- In general, filter methods are usually simplistic and therefore fast, but simplicity can sometimes lead to errors
As of 2019-10-13, implementation only for use with binary outcomes
- For multi-categorical outcomes, vignette suggests either performing the analyses with all pairs of outcome categories, then any variable deemed relevant for one analysis is considered relevant. Instead of doing all-pairs, you can dichotomize variable into pairs of category-other which would be less expensive
- Continuous outcomes have to be discretized
The algorithm explores all k-tuples of variables for k-dimensional analysis
\[x \cup \{x_{m_1}, x_{m_2}, \ldots, x_{m_{k-1}}\}\]
- \(x_i\) is one of the explanatory variables
- The max k is 5
- If it’s GPU-capable, this may not be the case anymore
- For larger values than 5, it becomes computationally expensive and detecting significant differences in conditional entropy becomes less likely.
- For example, 2-dimensional analysis would explore the set of all possible pairs (2-tuples) of variables.
- For each variable, \(x_i\), check whether adding it to the set with another variable, \(x_j\), adds information to the system.
- If there exists such a \(x_j\), then we declare \(x_i\) as 2-weakly relevant.
Steps
- Discretize all variables
- Choose the number of classes, \(c\)
- All variables are coerced into having the same number of classes (even binary? So if you have one binary, then all variables are coerced into binaries?)
- Unless there’s domain knowledge, multiple \(c\) values should be tried.
- Randomly sample (\(c-1\)) integers from a uniform distribution on the interval, (\(2, N\)) where \(N\) is the number of observations.
- The integers will be indexes where the variable is split into c classes
- At first glance it looks like the interval starts at 2 so that each class has minimum of 2 or 3 values (depending if the split happens before or after the integer), but unless there’s some kind of check, two consecutive integers, like 19,20, could still be sampled and then you have a problem. With a large data set, it seems unlikely to happen, but it’d still be possible. So I don’t know why it starts at 2. The vignette isn’t clear about this IMO.
- Sort the variable
- I guess smallest value to largest? Probably doesn’t matter as long as it’s consistent for all variables)
- Split the sorted variable at the indexes given by the randomly sampled integers
- Repeat for each variable
- The outcome variable might have to be done manually by the user prior to starting analysis/
- Choose the number of classes, \(c\)
- Compute conditional entropy for Y given the k-dimension variable set that includes a specific variable and the conditional entropy for the (\(k-1\)) set that excludes that specific variable.
Conditional Entropy for \(Y | X_1, \ldots, X_k\) is
\[H(Y|X_1, \ldots, X_k) = \sum_{d=0} \sum_{i_1 = 1}^c \ldots \sum_{i_k = 1}^c P(y_d | x_{i_1}, \ldots, x_{i_k}) \; \log P(y_d |x_{i_1}, \ldots, x_{i_k})\]
- \(d\) is for the outcome variable category which much be binary
- \(i_1\) is the ith category of the 1st variable
- \(i_k\) is the ith category of the kth variable
- This sequence of summations amounts to taking every permutation of outcome category and every category of every explanatory variable and summing them together.
- See the Algorithms, ML >> Trees >> Decision Trees for further discussion
- The conditional entropy for the (\(k-1\)) set of explanatory variable is calculated similarily
If \(k\) is less than total number of variables, then this process could include many permutations
- Compute the mutual information gain between these two entropies. Then out of all the mutual information values from all the different permutations of the \(k\)-tuple, choose the maximum value
Mutual information is the difference between two conditional entropies. Very similar to the information gain used in trees
\[IG_{\max}^k = N \; \max \{H(Y|X_1, \ldots, X_k) - H(Y|X_1, \ldots, X_{k-1})\}\]
- \(m\) is mth permutation of the \(k\)-tuple
- \(N\) is the number of observations. The reason for it being there is that multiplying the \(IG_{\max}\) by \(N\) makes it a distribution parameter that can be hypothesis tested.
- Hypothesis test this difference (\(IG_{\max}\)) to see if it’s significant
- If the difference is significant, then that variable is k-weakly relevant
- Test statistic for a specific \(\alpha\)-level is from an empirically calculated distribution
- Adjust p-values to control FWER or FDR
- If performing a more complicated model selection process, take the top n variables whose \(IG_{\max}\) was significant and repeat steps
- Guessing this is backwards elimination
- This is a method that’s built for dealing with thousands of variables, so this taking top-n-then-repeat seems to be a way of controlling the amount of time needed to complete the analysis.
- Discretize all variables