dbt
Overview
- A SQL orchestrator with dependency management, a testing framework, and documentation generator
- Forks
- opendbt - Extend dbt with plugins, local docs and custom adapters — fast, safe, and developer-friendly. It builds upon dbt-core, adding valuable features without changing dbt-core code.
- Alternatives (due to FiveTran merger)
- Alternative Stack (Thread from Portable dude)
- Portable for ingestion (1500+ integrations, predictable pricing)
- Coalesce.io or Coginiti for transformation
- Portable for reverse ETL (coming very very soon — happy to demo it for you)
- Streamkap for streaming and change data capture sources
- Orchestra for data orchestration
- Features
- Seamless integration across other tools in your data stack
- Developer-friendly experience for data transformation
- Modular design that promotes code reusability and maintainability
- Comprehensive testing framework to ensure robust data quality
- Built for data modeling
- Models are like sql queries
- Modularizes SQL code and makes it reusable across “models”
.png)
- Running the orders model also runs the base_orders model and base_payments model (i.e. dependencies for orders)
- Base models are in the staging layer and output views which means they’ll have the most up-to-date data for models in the intermediate and mart layers (final output).
- base_orders and base_payments are independent in that they can also be used in other models
- Creates more dependable code because you’re using the same logic in all your models
- Running the orders model also runs the base_orders model and base_payments model (i.e. dependencies for orders)
- You can schedule running sets of models by tagging them (e.g. #daily, #weekly)
- Version Control
- Snapshots provide a mechanism for versioning datasets
- Within every yaml file is an option to include the version
- Package add-ons that allow you to interact with spark, snowflake, duckdb, redshift, etc.
- Documentation for every step of the way
.yml files can be used to generate a website (localhost:8080) around all of your dbt documentation.
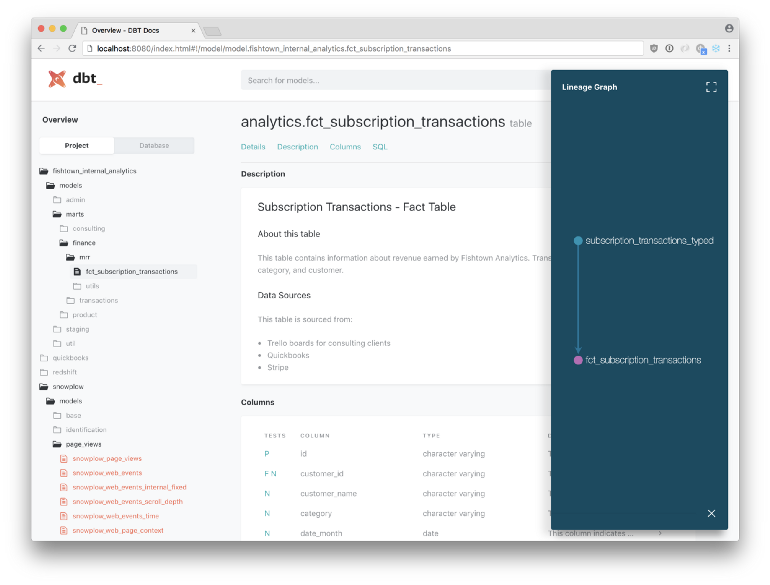
dbt docs generate dbt docs serve
Misc
List of available DB Adaptors
- Runs on Python, so adaptors are installed via pip
Notes from
Resources
- Overview of all DBT Products Docs
- DBT-Core Quickstart Docs
- Shows you how to set up a project locally, connect to a BigQuery warehouse, build and document models
- Create a Local dbt Project
- Uses docker containers to set up a local dbt project and a local postgres db to play around with
Development Workflow
- Mock out a design in a spreadsheet so you know you’re aligned with stakeholders on output goals.
- Write the SQL to generate that final output, and identify what tables are involved.
- Write SQL code for basic transformations (staging/base models) in the staging layer which directly source the tables
- Write models in the intermediate layer and/or mart layer using the more complex SQL code which source the models in the staging layer
- The final output (materializations) will be the output of the models in the mart layer
- Finally, with a functioning model running in dbt:
- Start refactoring and optimizing the mart
- Add tests and data validation
Model Running Workflow
dbt deps dbt seed dbt snapshot dbt run dbt run-operation {{ macro_name }} dbt testCommon Errors (source)
Issue Example Resolution Duplicate Model Names Two models both called “customers” Rename one model or reorganize project Missing Dependencies { ref('sales') }for non-existent modelEnsure referenced model exists Missing Sources { source('raw'.'sales') }List sources in sources.yml Incorrect Database Setup Wrong schema or database in config Update dbt_project.yml or profile settings Syntax or SQL Errors Forgotten comma or unbalanced parentheses Check SQL syntax Missing Configs No materialization specified Add config block Missing Package Dependency Unrecognized macro Include in packages.yml, run dbt depsMissing Macro Undefined macro Define in macros/ directory Circular References Model A references Model B, which references Model A Remove or refactor references Style Guide Components
- Naming conventions (the case to use and tense of the column names)
- SQL best practices (commenting code, CTEs, subqueries, etc.)
- Documentation standards for your models
- Data types of date, timestamp, and currency columns
- Timezone standards for all dates
Castor - tool that takes your project and autofills much of the documentation
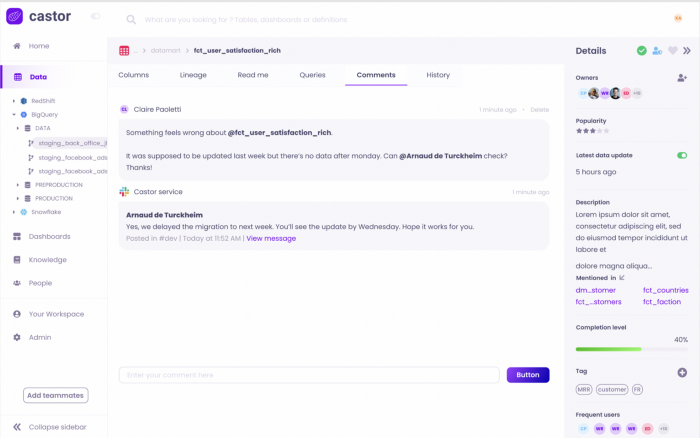
- Has a free tier
- Very helpful if you have the same column name in multiple datasets, you don’t have to keep defining it
- Tribal Knowledge
- When a dataset is discussed in a team slack channel, Castor pulls the comments and adds them to the documentation of the dataset
Lightdash - BI tool for dbt projects - free tier for self hosting
DBT-Cloud
- Thread from experienced DBT-Core user
- Likes the extra features if you have the money. Nice for teams with a mix of technical and not-so technical people — enhances collaboration.
- Thread from experienced DBT-Core user
Set-Up
- Docs
- Within a python virtual environment
Create:
python3 -m venv dbt-venvActivate:
source dbt-venv/bin/activate- Should be able to see a
(dbt-venv)prefix in every line on the terminal
- Should be able to see a
Install dbt-core:
pip install dbt-core- Specific version:
pip install dbt-core==1.3.0 - Confirm installation by checking version:
dbt --version
- Specific version:
Install plugins
pip install dbt-bigquery pip install dbt-spark # etc...
- Basic set-up: Article
- Example uses postgres adaptor
- Connections
- Docs
- Example: DBT-Core Quickstart Guide (See Misc >> Resources)
Connection to BigQuery in
profiles.yml(See Project Files)jaffle_shop: # this needs to match the profile in your dbt_project.yml file target: dev outputs: dev: type: bigquery method: service-account keyfile: /Users/BBaggins/.dbt/dbt-tutorial-project-331118.json # replace this with the full path to your keyfile project: grand-highway-265418 # Replace this with your project id dataset: dbt_bbagins # Replace this with dbt_your_name, e.g. dbt_bilbo threads: 1 timeout_seconds: 300 location: US priority: interactiveCheck connection
dbt debug #> Connection test: OK connection ok
- Environments
- dev - Your local development environment; configured in a
profiles.ymlfile on your computer.- While making changes with target: dev, your objects will be built in your development target without affecting production queries made by your end users
- prod - The production deployment of your dbt project, like in dbt Cloud, Airflow, etc.
- Once you are confident in your changes and set target: dev, you can deploy the code to production. Running models in this enviroment will affect end user queries.
- See continuous integration for details on using Github, Gitlab with dbt
- dev - Your local development environment; configured in a
- Schemas
- Use different schemas within one database to separate your environments
- If you have multiple dbt users writing code, it often makes sense for each user to have their own development environment.
- Set your dev target schema to be
dbt_<username>. User credentials should also differ across targets so that each dbt user is using their own data warehouse user.
- Set your dev target schema to be
- Custom Schemas (Docs)
- Allows you to build models across multiple schemas and group similar models together
- Avoids dbt users creating models in the same schema and overwriting each other’s work
- Use Cases
- Group models based on the business unit using the model, creating schemas such as core, marketing, finance and support.
- Hide intermediate models in a staging (database) schema, and only present models that should be queried by an end user in an analytics (database) schema (aka production).
- By default, dbt generates the schema name for a model by appending the custom schema to the target schema.
- Ensures that objects created in your data warehouse don’t collide with one another.
- To create a custom macro that overrides this default, see docs
- Set-Up
Inside
dbt_project.yml# models in `models/marketing/ will be built in the "*_marketing" schema models: my_project: marketing: +schema: marketingInside Model
{{ config(schema='marketing') }} select ...
Commands
Notes from dbt cheatsheet
Core
Basic Operations
pip install dbt-core dbt-duckdb # Install the dbt you have installed and adapter(s) pip install --upgrade dbt-core dbt-duckdb # Upgrade the version of dbt you have installed dbt --version # Get the version of dbt dbt init project_name # Setup a new project called project_name dbt debug # Check your dbt setup pip install sqlfluff sqlfluff-templater-dbt # Install SQL linter dbt deps # Install or update any dept packages in packages.yml dbt clean # Remove packages and target folder. Run dbt deps after dbt clean # A utility function that deletes all folders specified in the clean-targets list dbt docs generate # Create the documentation dbt serve --port 8081 # Open the documentation page on port 8081 dbt run-operation my_macro # Run a macro manually. Useful for execution sql that does not build a table dbt show --select my_dbt_model # Show the first 5 rows from the model dbt show --inline "select * from {{ ref('my_dbt_model') }}" limit 10 # Show the first 5 rows from the sql query dbt source freshness --select source:my_source # Show if the source table meets the freshness settings dbt parse # Quick check of the code integrity without connecting to the database dbt list --select tag:staging # List the models that are in the selection dbt test --store-failures # Store the failure records for tests in a tableRunning or Building
dbt build # Run/seed/test/snapshot all your dbt models dbt run # Test all your dbt model tests dbt test # Test all your dbt model tests dbt run --select my_dbt_model # Runs a specific model .sql is optional dbt run -s my_dbt_model another_dbt_model.sql # Runs the models .sql is optional. -s is the same as --select dbt compile -s my_dbt_model another_dbt_model.sql # Compile the models .sql is optional. -s is the same as --select dbt run --select models\risk360\staging # Runs all models in a specific directory dbt run --select tag:nightly # Run models with the "nightly" tag dbt run --vars 'run_date : "2021123"' # Set a variable at run time dbt run --select tag:staging # Run everything tagged as staging dbt run --select +my_dbt_model # Run everything up to and including my_dbt_model dbt run --select my_dbt_model+ # Run everything from my_dbt_model and onwards dbt run --select my_dbt_model+1 # Run my_dbt_model and one level of onward dependencies dbt run --select +my_dbt_model+ # Run everything that is needed for my_dbt_model and everything that uses it dbt run -s my_dbt_model # Runs a specific model .sql is optional -s and --select are the same dbt run -s my_dbt_model --target dev # Runs a specific model against target dev dbt run -s my_dbt_model -t dev # Runs a specific model against target dev -t and --target are the same dbt run --select my_dbt_model --dry_run # Compiles against the DB my_dbt_model but without running the code dbt run --select my_dbt_model --dry_run --empty # Compiles against the DB my_dbt_model but without running the code and avoids using any source data dbt parse # Check your project without connecting to the database dbt source freshness # Run the freshness tests on your sources dbt seed # Run all your dbt seeds dbt snapshot # Run all your dbt snapshots dbt snapshot --select my_snapshot # Run selected dbt snapshots dbt retry # Rerun only the failed or skipped items from the last run. Use after fixing an issue dbt run --select my_dbt_model --full-refresh # Refresh incremental models fully dbt run --select tag:staging --exclude my_dbt_model # Run everything tagged as staging excluding my_dbt_model dbt run --select config.materialized:view # select only view materializations
Project Files
Project Templates
- Style Guide
- More detailed: link
- Example Starter Project
.png)
- Style Guide
profiles.yml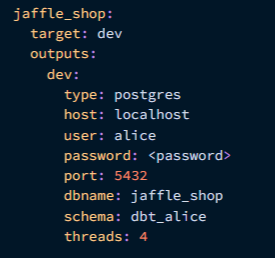
- Not included in project directory
- Only have to worry about this file if you set up dbt locally.
- Docs
- Created by
dbt initin~/.dbt/ - Contents
- database connection, database credentials that dbt will use to connect to the data warehouse
- If you work on multiple projects locally, the different project names (configured in the
dbt_project.ymlfile) will allow you to set up various profiles for other projects. - Where you set the target (i.e. branch) (e.g. dev or prod)
- When you use dbt from the CLI, it looks in dbt_project.yml for a name in profile: ‘name’. Then, it looks for that name in profiles.yml in order to find all the information it needs to connect to the database/warehouse and do work.
- You’ll have one profile name/info for each warehouse that you use
- Target
- dev target: An analyst using dbt locally will have this set as the default.
- prod target: Creates the objects in your production schema.
- However, since it’s often desirable to perform production runs on a schedule, it is recommended that you deploy your dbt project to a separate machine other than your local machine.
- Most dbt users only have a dev target in their profile on their local machine.
- Components
- type: The type of data warehouse you are connecting to
- Warehouse credentials: Get these from your database administrator if you don’t already have them. Remember that user credentials are very sensitive information that should not be shared.
- schema: The default schema that dbt will build objects in.
- threads: The number of threads the dbt project will run on.
dbt_project.yml- Docs
- Main configuration file for your project
- Basic Set-Up
- Fill in your project name and profile name
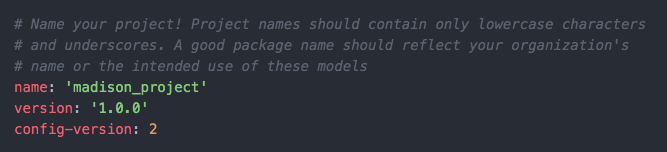
- Add variables and models
- Fill in your project name and profile name
- All available configurations that can be included in this file
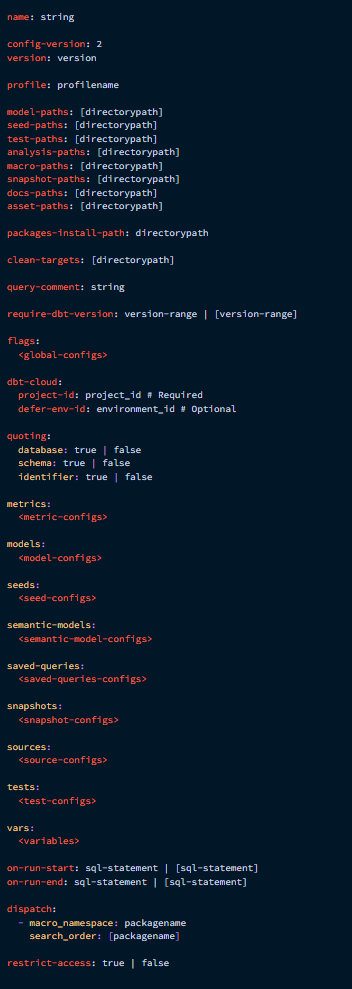
packages.yml- Docs
- List of external dbt packages you want to use in your project
- After adding the packages to packages.yml, run
dbt depsto install the packages. - Packages get installed in the
dbt_packagesdirectory — by default this directory is ignored by git, to avoid duplicating the source code for the package. - When you update a version or revision in your
packages.ymlfile, it isn’t automatically updated in your dbt project. You should rundbt depsto update the package. You may also need to run a full refresh of the models in this package. - Examples
Specific Version
packages: - package: dbt-labs/dbt_utils version: 0.7.3Range of Versions
packages: - package: calogica/dbt_expectations version: [">=0.7.0", "<0.8.0"]
dependencies.yml- Docs
- Designed for the dbt Mesh and cross-project reference workflow
- Can contain both types of dependencies: “package” and “project” dependencies
- If your dbt project doesn’t require the use of Jinja within the package specifications, you can simply rename your existing
packages.ymltodependencies.yml. - However, if your project’s package specifications use Jinja, particularly for scenarios like adding an environment variable or a Git token method in a private Git package specification, you should continue using the
packages.ymlfile name.
Directories
Example: Source
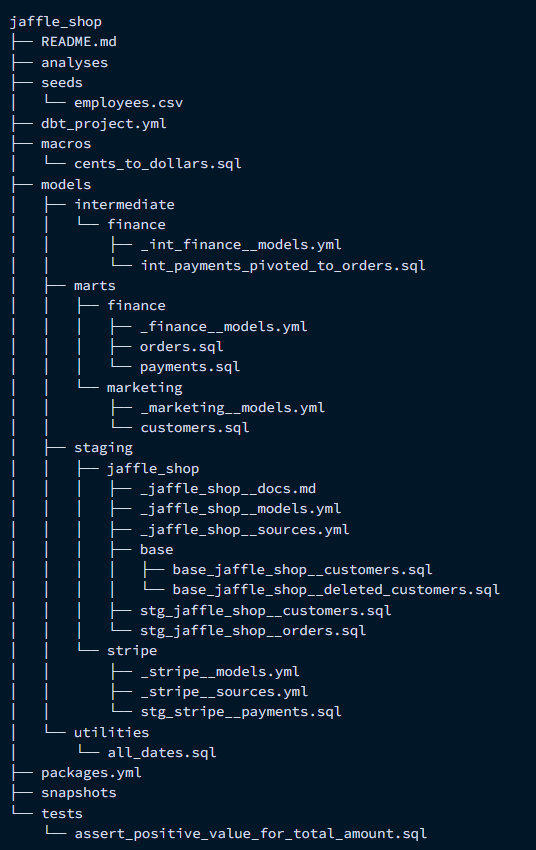
Models
- Sources (i.e. data sources) are defined in
src_<source>.ymlfiles in your models directory- .yml files contain definitions and tests (Docs)
- .doc files contain source documentation
- Models (i.e. sql queries) are defined
stg_<source>.yml- .yml files contain definitions and tests (Docs)
Example:
models: - name: your_model_name config: materialized: incremental unique_key: primary_key_name
- .doc files contain source documentation
- The actual models are the .sql files
- .yml files contain definitions and tests (Docs)
- Example
.png)
- Staging:
- Different data sources will have separate folders underneath staging (e.g. stripe).
- Marts:
- Use cases or departments have different folders underneath marts (e.g. core or marketing)
- Staging:
- Sources (i.e. data sources) are defined in
Macros
Seeds
- Docs
- Seeds are csv files that you add to your dbt project to be uploaded to your data warehouse.
- Uploaded into your data warehouse using the
dbt seedcommand
- Uploaded into your data warehouse using the
- Best suited to static data which changes infrequently.
- Use Cases:
- A list of unique codes or employee ids that you may need in your analysis but is not present in your current data.
- A list of mappings of country codes to country names
- A list of test emails to exclude from analysis
- Use Cases:
- Referenced in downstream models the same way as referencing models — by using the
reffunction
Snapshots
Captures of the state of a table at a particular time
build a slowly changing dimension (SCD) table for sources that do not support change data capture (CDC)
Example
- Every time the status of an order change, your system overrides it with the new information. In this case, there we cannot know what historical statuses that an order had.
- Daily snapshots of this table builds a history and allows you to track order statuses
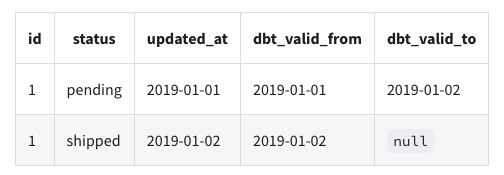
Example: (source)
{% snapshot user_snapshots %} {{ config( target_schema='snapshots', unique_key='id', strategy='timestamp', updated_at='updated_at' ) }} SELECT id, name, email, updated_at FROM {{ source('raw_data', 'users') }} {% endsnapshot %}
Components
Materializations
- Misc
- The manner in which the data is represented, i.e. the outputs of the models
- Docs
- Start with models as views, when they take too long to query, make them tables, when the tables take too long to build, make them incremental.
- View
Default materialization when there is no specification in the configuration
Just like Standard Views, i.e. a saved SQL query (See SQL >> Views)
Always reflects the most up-to-date version of the input data
Cost nothing to build since they’re just queries, but have to be processed every time they’re ran.
- Slower to return results than a table of the same data.
- Can cost more over time, especially if they contain intensive transformations and are queried often.
Best for
- Building a model that stitches lots of other models together (Don’t want to worry about freshness of ever table involved).
- Small datasets with minimally intensive logic that you want near realtime access to
Example
{{ config( materialized='view' ) }} SELECT col1, col2 FROM {{ ref('my_model') }}
- Table
Stores the literal rows and columns on disk (i.e. materialized view)
Ideal for models that get queried regularly
Reflects the most recent run on the source data that was available
Best for sources for BI products and other frontend apps (e.g. like a mart that services a popular dashboard)
Example
{{ config( materialized='table' ) }} SELECT col1, col2 FROM {{ ref('my_model') }}
- Incremental
Builds a table in pieces over time — only adding and updating new or changed records which makes them efficient.
Builds more quickly than a regular table of the same logic.
Typically used on very large datasets, so building the initial table on the full dataset is time consuming and equivalent to the table materialization.
Adds complexity and requires deeper consideration of layering and timing.
- See “Late arriving facts” section of the Docs
Can drift from source data over time since you’re not processing all of the source data. Extra effort is required to capture changes to historical data.
- See “Long-term considerations” section of the Docs
Best for — same as tables, but for larger datasets.
Can break down when processing “petabytes of data while supporting 100+ developers simultaneously working across 2,500+ models.” See Discord article
- “devs frequently needed to modify the same tables, but with dbt’s default behavior, they would constantly overwrite each other’s test tables. Having 100+ developers in the same “kitchen”, of course, created confusion and a suboptimal experience for fellow devs who couldn’t reliably test their changes.”
- “using dbt’s
is_incremental()macro became a major bottleneck. Using this macro in BigQuery is suboptimal since it requires a full table scan to determine the latest timestamp from dbt’s previous run, which can be costly and slow at scale. Our developers were regularly waiting over 20 minutes for compilations, severely limiting productivity and creating a frustrating development experience.”
Requirements
- A filter to select just the new or updated records
- A conditional block that wraps the filter and only applies it when we want it
- A configuration that tells dbt to build incrementally and helps apply the conditional filter when needed
What happens underneath inside the data warehouse
- When there are records that already exist within the table but have a new field value:
- Option 1:
delete + insertdeletes these records and replaces them with an updated version of that record. - Option 2:
mergecombines the insert, update, and delete statements into one. Instead of deleting changed records, it will replace the old field values with the new ones. - Option 3:
insert + overwriteapplies to the same records as the other strategies, but overwrites all fields of an existing record rather than just the ones that have changed
- Option 1:
- When there are records that already exist within the table but have a new field value:
Example
{{ config( materialized='incremental', incremental_strategy='merge', unique_key=['col1','col2'] ) }} SELECT col1, col2, col3, updated_at FROM {{ ref('my_model') }} {% if is_incremental() %} WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }}) {% endif %}
- Ephemeral
- Creates a CTE
- More difficult to troubleshoot, as they’re interpolated into the models that
refthem, rather than existing on their own in a way that you can view the output of. - Use Cases
- Very light-weight transformations that are early on in your DAG
- Should only used in one or two downstream models
- For a materialization that does not need to be queried directly
- Macros called using
dbt run-operationcannotref()ephemeral materializations
- Macros called using
- Doesn’t support model contracts
- Set-Up
In practice, you want to set materializations at the folder level, and use individual model configs to override those as needed.
In
dbt_project.ymlA + is used to indicate a materialization
Example: models
models: jaffle_shop: marketing: +materialized: view paid_ads: google: +materialized: table- All models in the marketing and paid_ads folders are views while models in the google folder are tables
In Model files
Example: Table (or View)
{{ config( materialized='table' ) }} select ...Example: Incremental
- 1
- unique_key specifies the field that allows dbt to find a record from the previous run (old data) with the same unique id as the new data in order to update that record instead of adding it as a separate row.
- 2
-
An if-else conditional that uses
is_incremental(macro) to check if the systematic conditions necessary for an incremental model are met (See below) - 3
- The conditional block containing the filter that finds the latest updated_at date, so dbt knows whether the source data has new records that need to be added or not.
{ this }means filter from “this” materializationis_incremental(macro) checks:- materialized =‘incremental’
- There is an existing table for this model in the warehouse to add to/update
--full-refreshflag was not passed (docs)- Overrides the incremental materialization and builds the table from scratch again
- Useful if the table drifts from the source table over time.
Variables
Defined in the
project.ymland used in modelsExample: Assigning States to Regions
vars: state_lookup: Northeast: - CT - ME Midwest: - IL - IN
Using the variables in a model
{# Option 1 #} SELECT state, CASE {% for k, v in var("state_lookup").items() %} WHEN state in ({% for t in v %}'{{ t }}'{% if not loop.last %}, {% endif %}{% endfor %}) THEN {{ k }}{% endfor %} ELSE NULL END AS region FROM {{ ref('my_table') }} {# Option 2 #} SELECT state, CASE {% for k, v in var("state_lookup").items() %} WHEN state in ({{ t|csl }}) THEN {{ k }}{% endfor %} ELSE NULL END AS region FROM {{ ref('my_table') }}
Models
Misc
- Tagging
- Allows you to run groups of models
- Example:
dbt run --models tag:daily
- Example:
- Allows you to run groups of models
YAML Options
- Contracts
- Enforces constraints on the materialization output from a model (emphemeral not supported)
- Data Tests differ from contracts since they are a more flexible mechanism for validating the content of your model after it’s built (contracts execute at build time)
- Contracts probably requires less compute (cost) in your data platform
- Docs
- Incremental materializations requires setting: on_schema_change: append_new_columns
- Set-Up
When enforced: true, name and data_type are required to be set for every column
Set alias_types: false to opt-out of letting dbt try to convert a specified type to one that conforms to a specific platform
- e.g. Specify string in your contract while on Postgres/Redshift, and dbt will convert it to text.
If a varchar size or numeric scale is not specified, then dbt relies on default values
Example
models: - name: dim_customers config: materialized: table contract: enforced: true columns: - name: customer_id data_type: int constraints: - type: not_null - name: customer_name data_type: string - name: non_integer data_type: numeric(38,3)- numeric(38,3) says non-integer is allowed to have 38 (precision) total digits (whole + decimal) and 3 decimal places (scale).
- Enforces constraints on the materialization output from a model (emphemeral not supported)
- Constraints
When specified, the platform (e.g. postgres, BigQuery, etc.) will perform additional validation on data as it is being populated in a new table or inserted into a preexisting table. If the validation fails, the table creation or update fails (or there’s a warning), the operation is rolled back, and you will see a clear error message.
Only table and incremental materializations supported
Can be set at the column level (recommended) or model level
Keys and Values
- type (required): one of not_null, unique, primary_key, foreign_key, check, custom
- expression: Free text input to qualify the constraint.
- Required for certain constraint types and optional for others.
- name (optional): Human-friendly name for this constraint. Supported by some data platforms.
- columns (model-level only): List of column names to apply the constraint over
Example
models: - name: <model_name> # required config: contract: enforced: true # model-level constraints constraints: - type: primary_key columns: [FIRST_COLUMN, SECOND_COLUMN, ...] - type: FOREIGN_KEY # multi_column columns: [FIRST_COLUMN, SECOND_COLUMN, ...] expression: "OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_FIRST_COLUMN, OTHER_MODEL_SECOND_COLUMN, ...)" - type: check columns: [FIRST_COLUMN, SECOND_COLUMN, ...] expression: "FIRST_COLUMN != SECOND_COLUMN" name: HUMAN_FRIENDLY_NAME - type: ... columns: - name: FIRST_COLUMN data_type: DATA_TYPE # column-level constraints constraints: - type: not_null - type: unique - type: foreign_key expression: OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_COLUMN) - type: ...
Best Practices
Modularity where possible
- Same as the functional mindset: “if there’s any code that’s continually repeated, then it should be a function(i.e. its own separate model in dbt).”
Readability
- Comment
- Use CTEs instead of subqueries
- Use descriptive names
- Example: if you are joining the tables “users” and “addresses” in a CTE, you would want to name it “users_joined_addresses” instead of “user_addresses”
Example: Comments, CTE, Descriptive Naming
WITH Active_users AS ( SELECT Name AS user_name, Email AS user_email, Phone AS user_phone, Subscription_id FROM users --- status of 1 means a subscription is active WHERE subscription_status = 1 ), Active_users_joined_subscriptions AS ( SELECT Active_users.user_name, active_users.user_email, Subscriptions.subscription_id, subscriptions.start_date , subscriptions.subscription_length FROM active_users LEFT JOIN subscriptions ON active_users.subscription_id = subscriptions.subscription_id ) SELECT * FROM Active_users_joined_subscriptions
Layers
Staging
- Subdirectories based on the data sources (not business entities)
- Naming Convention
- Syntax:
stg_[source]__[entity]s.sql- The double underscore between source system and entity helps visually distinguish the separate parts in the case of a source name having multiple words.
- Syntax:
- Contains all the individual components of your project that the other layers will use in order to craft more complex data models.
- Once you get a feel for these models, use the codegen package to automatically generate them. (See Packages)
- Data Sources
- Only layer where the
sourcemacro is used - Each model bears a one-to-one relationship with the source data table it represents (i.e. 1 staging model per source)
- Only layer where the
- Transformations
- Only transformations that are needed for every downstream model should be applied.
- Typical Transformations: recasting, column/view renaming, basic computations (e.g. cents to dollars), binning continuous fields, collapsing categoricals fields.
- Unions may also be applied if you have two sources with the same fields
- e.g. two tables that represent the same store except that perhaps they are in different regions or selling on two different platforms, and your project only wants to use aggregated calculations from both.
- Unions may also be applied if you have two sources with the same fields
- Aggregations and joins should be avoided. But, if joins are necessary, then create a subdirectory called base within the source directory.
- Within that subdirectory, create
base_models that perform the previously mentioned “Typical Transformations.” - Then, at the source directory level, create staging,
stg_, models that join those base models that are in the subdirectory. (See docs for examples)
- Within that subdirectory, create
- Base Models
- Basic transformations (e.g. cleaning up the names of the columns, casting to different data types)
- Other models use these models as data sources
- Prevents errors like accidentally casting your dates to two different types of timestamps, or giving the same column two different names.
- Two different timestamp castings can cause all of the dates to be improperly joined downstream, turning the model into a huge disaster
- Prevents errors like accidentally casting your dates to two different types of timestamps, or giving the same column two different names.
- Usually occuring in staging
- Read directly from a source, which is typically a schema in your data warehouse
- Source object:
{ source('campaigns', 'channel') }- campaigns is the name of the source in the .yml file
- channel is the name of a table from that source
- Source object:
- Materialized as views.
Allows any intermediate or mart models referencing the staging layer to get access to fresh data and at the same time it saves us space and reduces costs.
In
dbt_project.ymlmodels: jaffle_shop: staging: +materialized: view- View is the default materialization, but still good to set manually just for clarification purposes.
Intermediate
- Uses views from the staging layer to build more complex models
- Subdirectories based on business entities (e.g. marketing, finance, etc.)
- If you have fewer than 10 models and aren’t having problems developing and using them, then feel free to forego subdirectories completely.
- Naming Convention
- Syntax:
int_[entity]s_[verb]s.sql - Verb Examples: pivoted, aggregated_to_user, joined, fanned_out_by_quantity, funnel_created, etc.)
- No double underscores
- If for some reason you had to use a source macro in this layer, then you could use double underscores between entity(s) and verb(s)
- Example:
int_payments_pivoted_to_orders
- Syntax:
- Other models should reference the models within this stage as Common Table Expressions although there may be cases where it makes sense to materialize them as Views
- Macros called via
run-operationcannot reference ephemeral materizations (i.e. CTEs) - Recommended to start with ephemeral materializations unless this doesn’t work for the specific use case
- Macros called via
- Whenever you decide to materialize them as Views, it may be easier to to do so in a custom schema, that is a schema outside of the main schema defined in your dbt profile.
- If the same intermediate model is referenced by more than one model then it means your design has probably gone wrong.
- Usually indicates that you should consider turning your intermediate model into a macro. reference the base models rather than from a source
- Reference object
{ ref('base_campaign_types') }- base_campaign_types is a base model
Marts
- Where everything comes together in a way that business-defined entities and processes are constructed and made readily available to end users via dashboards or applications.
- Since this layer contains models that are being accessed by end users it means that performance matters. Therefore, it makes sense to materialize them as tables.
- If a table takes too much time to be created (or perhaps it costs too much), then you may also need to consider configuring it as an incremental model.
- A mart model should be relatively simple and therefore, too many joins should be avoided
- Example
- A monthly recurring revenue (MRR) model that classifies revenue per customer per month as new revenue, upgrades, downgrades, and churn, to understand how a business is performing over time.
- It may be useful to note whether the revenue was collected via Stripe or Braintree, but they are not fundamentally separate models.
- A monthly recurring revenue (MRR) model that classifies revenue per customer per month as new revenue, upgrades, downgrades, and churn, to understand how a business is performing over time.
Utilities
- Directory for any general purpose models that are generated from macros or based on seeds that provide tools to help modeling, rather than data to model itself.
- The most common use case is a date spine generated with the dbt utils package.
- Also see Packages, Databases, Engineering >> Terms >> Date Spine
Optimizations
- Runs parallelized
- Models that have dependencies aren’t run until their upstream models are completed but models that don’t depend on one another are run at the same time.
- The thread parameter in your
dbt_project.ymlspecifies how many models are permitted to run in parallel
- Incremental Materializations
- See Components >> Materializations
- Saves money by not rebuilding the entire table from scratch when records only need to be updated or added to a table (plus transformations to the new records).
- Useful for big data tables and expensive transformations
Packages
- Available Packages: link
- See Project Files >> packages.yml
- Packages
- dbt-athena - Adaptor for AWS Athena
- audit-helper
- Compares columns, queries; useful if refactoring code or migrating db
- codegen
- Generate base model, barebones model and source .ymls
- dbtplyr - Macros
- dplyr tidy selectors, across, etc.
- dbt-duckdb (Overview) - Adapter for duckdb
- elementary - Includes schema change alerts and anomaly detection tests. It is great for tracking trends in your data to see if anything falters from the usual
- dbt-expectations
- Data validation based on great expectations py lib
- external-tables
- Create or replace or refresh external tables
- Guessing this means any data source (e.g. s3, spark, google, another db like snowflake, etc.) that isn’t the primary db connected to the dbt project
- logging
- Provides out-of-the-box functionality to log events for all dbt invocations, including run start, run end, model start, and model end.
- Can slow down runs substantially
- profiler
- Implements dbt macros for profiling database relations and creating doc blocks and table schemas (schema.yml) containing said profiles
- re_data
- Dashboard for monitoring, macros, models
- dbt-score
- Linting of models and sources which have metadata associated with them: documentation, tests, types, etc.
- dbt_set_similarity
- Calculates similarity metrics between fields in your database
- Docs
- Measuring Cross-Product Adoption Using dbt_set_similarity
- Fields must be arrays.
- dbt-spark - If you’re using databricks, it’s recommended to use dbt-databricks
- spark-utils
- Enables use of (most of) the {dbt-utils} macros on spark
- dbt-utils
- Ton of stuff for tests, queries, etc.
Data Validation and Unit Tests
Misc
- Test both your raw data (sources) and transformed data (models). It’s important to test both to help you pinpoint where issues originate, helping in the debugging process.
- Source Tests: Confirms that you are transforming quality data, allowing you to be confident in the input of your data models. When you are confident in the input, data quality issues can then be attributed to transformation code.
- Model Tests: They come after source testing. When adding a test to a model, you are setting expectations on how the code you’ve written should transform your data.
- If the data produced by a model passed a test when it was first written, but now fails, its most likely due to something in the data changing that your code can no longer handle.
- Built-in support for CI/CD pipelines to test your “models” and stage them before committing to production
- Run test -
dbt test - See also
- Most of the tests are defined in a models-type .yml file in the models directory
- Can be applied to a model or a column
- Test that the primary key column is unique and not null
- Differences from Contracts
- Tests are more configurable, such as with custom severity thresholds.
- Tests are asier to debug after finding failures, because you can query the already-built model, or store the failing records in the data warehouse.
Macros
- Custom (aka Singular) tests should be located in a tests folder.
dbt will evaluate the SQL statement.
The test will pass if no row is returned and failed if at least one or more rows are returned.
Useful for testing for some obscurity in the data
Example: Check for duplicate rows when joining two tables
select a.id from {{ ref(‘table_a’) }} a left join {{ ref(‘table_b’) }} b on a.b_id = b.id group by a.id having count(b.id)>1- i.e. If I join table a with table b, there should only be one record for each unique id in table a
- Process
- Join the tables on their common field
- Group them by the id that should be distinct
- Count the number of duplicates created from the join.
- This tells me that something is wrong with the data.
- Add a having clause to filter out the non-dups
- Example: (source)
Definition
{% macro calculate_revenue(total_sales, cost_of_goods_sold) %} {{ total_sales }} - {{ cost_of_goods_sold }} {% endmacro %}Usage
SELECT order_id, {{ calculate_revenue('total_sales', 'cogs') }} AS revenue FROM {{ ref('orders') }}
Mock Data
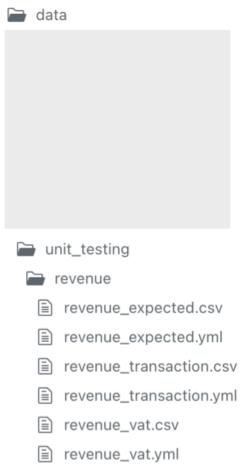
- Data used for unit testing SQL code
- To ensure completeness, it’s best if analysts or business stakeholders are the ones provide test cases or test data
- Store in the “data” folder (typically .csv files)
- each CSV file represents one source table
- should be stored in a separate schema (e.g. unit_testing) from production data
- dbt seed (see below, Other >> seeds) command is used to load mock data into the data warehouse
Tests
- Misc
- Notes from How to Test Your Data Models with dbt
- Packages
- dbt-expectations, dbt-utils, elementary
- Besides Freshness, Uniqueness, and Not NULL, only add more tests if there’s an actionable next step when they fail.
- Considerations
- Which source fields are used in downstream data models? Are there qualities you should be testing to ensure the transformations downstream turn out as expected?
- e.g. testing the datatype of an amount field that’s used in a SUM calculation downstream
- Are there id fields used in JOINs downstream? Would adding a relationships test prevent joining records that don’t exist?
- Are CASE statements used in your model code? Should there be an accepted_values test at the source to ensure all possible values are captured?
- Which source fields are used in downstream data models? Are there qualities you should be testing to ensure the transformations downstream turn out as expected?
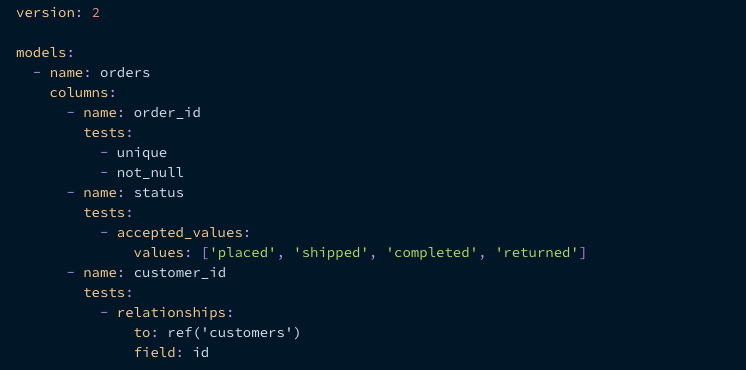
- Model Tests YAML
Example: (source)
version: 2 models: - name: orders columns: - name: order_id data_tests: - unique - not_null - name: status data_tests: - accepted_values: values: ['placed', 'shipped', 'completed', 'returned'] - name: customer_id data_tests: - relationships: to: ref('customers') field: id
- User-Defined Test
Example: Put into
data_testsdirectory (source)-- Refunds have a negative amount, so the total amount should always be >= 0. -- Therefore return records where total_amount < 0 to make the test fail. select order_id, sum(amount) as total_amount from {{ ref('fct_payments') }} group by 1 having total_amount < 0
- Freshness (docs) - Used to define the acceptable amount of time between the most recent record, and now, for a table
The built-in test only available for sources, but dbt_expectations has one for models
Freshness tests on sources should match the frequency of your ingestion syncs
- See Production, Tools >> Ingestion >> Concepts >> Sync Methods
- e.g. If you sync your data every hour because you expect new records in a source every hour, your freshness tests should reflect this.
Should only be configured for critical data sources. If you aren’t using a data source despite having it documented, freshness tests may only contribute to test bloat.
Identify the timestamp field that represents when your data was created or ingested.
- Examples
- A created_at field directly from the source itself
- An autogenerated field by your ingestion tool
- e.g. Airbyte’s _airbyte_extracted_at field which is automatically created in each data source
- Examples
Example
sources: - name: sales_pipeline freshness: warn_after: count: 2 period: hour error_after: count: 2 period: hour loaded_at_field: _airbyte_extracted_atExample: dbt_expectations
models: - name: sales_mrr - name: mrr_computed_at tests: - dbt_expectations.expect_row_values_to_have_recent_data: datepart: week interval: 1
- Uniqueness - Tests that the value in a field is unique across all records.
Important to apply to the primary key of every source and model to ensure this field accurately represents a unique record
Example
sources: - name: sales_pipeline columns: - name: opportunity_id tests: - unique
- Not NULL - Should be applied to every field where you expect there to be a value, particularly on the primary key.
Example
sources: - name: sales_pipeline columns: - name: opportunity_id tests: - unique - not_null
- Recency - Asserts that a timestamp column in the reference model contains data that is at least as recent as the defined date interval.
Can be useful for incremental models
Example: dbt-utils
version: 2 models: - name: model_name tests: - dbt_utils.recency: datepart: day field: created_at interval: 1
Examples
- Example:
project.yml
- Example: Unit Test
Add test to
dbt_project.ymlseeds: unit_testing: revenue: schema: unit_testing +tags: - unit_testing- Every file in the unit_testing/revenue folder will be loaded into unit_testing
- Executing
dbt build -s +tag:unit_testingwill run all the seeds/models/tests/snapshots with tag unit_testing and their upstreams
Create macro that switches the source data in the model being tested from production data (i.e. using
{ source() }) to mock data (i.e. usingref) when a unit test is being run{% macro select_table(source_table, test_table) %} {% if var('unit_testing', false) == true %} {{ return(test_table) }} {% else %} {{ return(source_table) }} {% endif %} {% endmacro %}- Article calls this file “select_table.sql”
- 2 inputs: “source_table” (production data) and “test_table” (mock data)
- macro returns the appropriate table based on the variable in the dbt command
- If the command doesn’t provide unit_testing variable or the value is false , then it returns source_table , otherwise it returns test_table.
Add macro code chunk to model
{{ config ( materialized='table', tags=['revenue'] ) }} {% set import_transaction = select_table(source('user_xiaoxu','transaction'), ref('revenue_transaction')) %} {% set import_vat = select_table(source('user_xiaoxu','vat'), ref('revenue_vat')) %} SELECT date , city_name , SUM(amount_net_booking) AS amount_net_booking , SUM(amount_net_booking * (1 - 1/(1 + vat_rate))) AS amount_vat FROM {{ import_transaction }} LEFT JOIN {{ import_vat }} USING (city_name) GROUP BY 1,2- Inside the
{%...%}, the macro “select_table” is called to set the local variables, “import_transaction” and “import_vat” which are later used in the model query - Model file is named “revenue2.sql”
- Inside the
Run model and test using mock data:
dbt build -s +tag:unit_testing --vars 'unit_testing: true'- Run model with production data (aka source data):
dbt build -s +tag:revenue --exclude tag:unit_testing
- Run model with production data (aka source data):
Compare output
version: 2 models: - name: revenue meta: owner: "@xiaoxu" tests: - dbt_utils.equality: compare_model: ref('revenue_expected') tags: ['unit_testing']- Model properties file that’s named
revenue.ymlin the models directory - By including tags: [‘unit_testing’] we can insure that we don’t run this test in production (see build code above with
--exclude tag:unit_testing
- Model properties file that’s named
Macro for comparing numeric output
{% test advanced_equality(model, compare_model, round_columns=None) %} {% set compare_columns = adapter.get_columns_in_relation(model) | map(attribute='quoted') %} {% set compare_cols_csv = compare_columns | join(', ') %} {% if round_columns %} {% set round_columns_enriched = [] %} {% for col in round_columns %} {% do round_columns_enriched.append('round('+col+')') %} {% endfor %} {% set selected_columns = '* except(' + round_columns|join(', ') + "), " + round_columns_enriched|join(', ') %} {% else %} {% set round_columns_csv = None %} {% set selected_columns = '*' %} {% endif %} with a as ( select {{compare_cols_csv}} from {{ model }} ), b as ( select {{compare_cols_csv}} from {{ compare_model }} ), a_minus_b as ( select {{ selected_columns }} from a {{ dbt_utils.except() }} select {{ selected_columns }} from b ), b_minus_a as ( select {{ selected_columns }} from b {{ dbt_utils.except() }} select {{ selected_columns }} from a ), unioned as ( select 'in_actual_not_in_expected' as which_diff, a_minus_b.* from a_minus_b union all select 'in_expected_not_in_actual' as which_diff, b_minus_a.* from b_minus_a ) select * from unioned {% endtest %}- File called “advanced_equality.sql”