Base R
Misc
Magrittr + base
mtcars %>% {plot(.$hp, .$mpg)} mtcars %$% plot(hp, mpg)- By wrapping the RHS in curly braces, we can override the rule where the LHS is passed to the first argument ## Options {#sec-baser-opts .unnumbered}
Remove scientific notation
options(scipen = 999)Wide and long printing tibbles
# in .Rprofile makeActiveBinding(".wide", function() { print(.Last.value, width = Inf) }, .GlobalEnv)- After printing a tibble, if you want to see it in wide, then just type .wide + ENTER.
- Can have similar bindings for `.long` and `.full`.
Heredocs - Powerful feature in various programming languages that allow you to define a block of text within the code, preserving line breaks, indentation, and other whitespace.
text <- r"( This is a multiline string in R)" cat(text)
User Defined Functions
Anonymous (aka lambda) functions:
\(x) {}(> R 4.1)function(x) { x[which.max(x$mpg), ] } # equivalent to the above \(x) { x[which.max(x$mpg), ] }Define and call an anonymous function at the same time
n <- c(1:10) moose <- (\(x) x+1)(n) moose #> [1] 2 3 4 5 6 7 8 9 10 11Dots (…)
Misc
User Defined Functions
moose <- function(...) { dots <- list(...) dots_names <- names(dots) if (is.null(dots_names) || "" %in% dots_names { stop("All arguments must be named") } }Nested Functions
f02 <- function(...){ vv <- list(...) print(vv) } f01 <- function(...){ f02(b = 2,...) } f01(a=1,c=3) #> $b #> [1] 2 #> #> $a #> [1] 1 #> #> $c #> [1] 3Subset dots values
add2 <- function(...) { ..1 + ..2 } add2(3, 0.14) # 3.14Subset dots dynamically:
...elt(n)- Set a value to n and get back the value of that argument
Number of arguments in … :
...length()
Functions
do.call- allows you to call other functions by constructing the function call as a listArgs
- what – Either a function or a non-empty character string naming the function to be called
- args – A list of arguments to the function call. The names attribute of args gives the argument names
- quote – A logical value indicating whether to quote the arguments
- envir – An environment within which to evaluate the call. This will be most useful if what is a character string and the arguments are symbols or quoted expressions
Example: Apply function to list of vectors
vectors <- list(c(1, 2, 3), c(4, 5, 6), c(7, 8, 9)) combined_matrix <- do.call(rbind, vectors) combined_matrix ## [,1] [,2] [,3] ## [1,] 1 2 3 ## [2,] 4 5 6 ## [3,] 7 8 9Example: Apply multiple functions
data_frames <- list( data.frame(a = 1:3), data.frame(a = 4:6), data.frame(a = 7:9) ) mean_results <- do.call( rbind, lapply(data_frames, function(df) mean(df$a)) ) mean_results ## [,1] ## [1,] 2 ## [2,] 5 ## [3,] 8- First the mean is calculated for column a of each df using
lapplylapplyis supplying the data fordo.callin the required format, which is a list or character vector.
- Second the results are combined into a matrix with
rbind
- First the mean is calculated for column a of each df using
sink- used to divert R output to an external connection.Use Cases: exporting data to a file, logging R output, or debugging R code.
Args
- file: The name of the file to which R output will be diverted. If file is NULL, then R output will be diverted to the console.
- append: A logical value indicating whether R output should be appended to the file (TRUE) or overwritten (FALSE). The default value is FALSE.
- type: A character string. Either the output stream or the messages stream. The name will be partially match so can be abbreviated.
- split: logical: if TRUE, output will be sent to the new sink and the current output stream, like the Unix program tee.
Example: Logging output of code to file
sink("r_output.log") # Redirect output to this file # Your R code goes here sink() # Turn off redirection- output file could also have an extension like “.txt”
Example: Debugging
sink("my_function.log") # Redirect output to this file my_function() sink() # Turn off redirectionExample: Appending output to a file
sink("output.txt", append = TRUE) # Append output to the existing file cat("Additional text\n") # Append custom text plain text sink() # Turn off redirection
pminandpmaxFind the element-wise maximum and minimum values across vectors in R
Example
vec1 <- c(3, 9, 2, 6) vec2 <- c(7, 1, 8, 4) pmax(vec1, vec2) #> [1] 7 9 8 6 pmin(vec1, vec2) #> [1] 3 1 2 4Example: With NAs
data1 <- c(7, 3, NA, 12) data2 <- c(9, NA, 5, 8) pmax(data1, data2, na.rm = TRUE) #> [1] 9 3 5 12
switchExample:
switch(parallel, windows = "snow" -> para_proc, other = "multicore" -> para_proc, no = "no" -> para_proc, stop(sprintf("%s is not one of the 3 possible parallel argument values. See documentation.", parallel)))parallel is the function argument. If it doesn’t match one of the 3 values, then an error is thrown.
If the argument value is matched, then the quoted value is stored in para_proc
dynGetLooks for objects in the environment of a function.
When an object from the outer function is an input for a function nested around 3 layers deep or more, it may not be found by that most inner function.
dynGetallows that function to find the object in the outer frameArguments
minframe: Integer specifying the minimal frame number to look into (i.e. how far back to look for the object)
inherits: Should the enclosing frames of the environment be searched?
Example:
1function(args) { if (method == "kj") { ncv_list <- purrr::map2(grid$dat, grid$repeats, function(dat, reps) { rsample::nested_cv(dat, outside = vfold_cv(v = 10, repeats = dynGet("reps")), inside = bootstraps(times = 25)) }) } } 2function(data) { if (chk::vld_used(...)) { dots <- list(...) init_boot_args <- list(data = dynGet("data"), stat_fun = cles_boot, # internal function group_variables = group_variables, paired = paired) get_boot_args <- append(init_boot_args, dots) } cles_booted <- do.call( get_boot_ci, get_boot_args ) }- 1
- Example from Nested Cross-Validation Comparison
- 2
- Example from {ebtools::cles}
match.argPartially matches a function’s argument values to list of choices. If the value doesn’t match the choices, then an error is thrown
Example:
keep_input <- "input_le" keep_input_val <- match.arg(keep_input, choices = c("input_lags", "input_leads", "both"), several.ok = FALSE) keep_input_val #> [1] "input_leads"- several.ok = FALSE says only 1 match is allowed otherwise an error is thrown.
- The error message is pretty informative btw.
match.funExample
f <- function(a,b) { a + b } g <- function(a,b,c) { (a + b) * c } h <- function(d,e) { d - e } yolo <- function(FUN, ...) { FUN <- match.fun(FUN) params <- list(...) FUN_formals <- formals(FUN) idx <- names(params) %in% names(FUN) do.call(FUN, params[idx]) } yolo(h, d = 2, e = 3) #> -1
Pipe
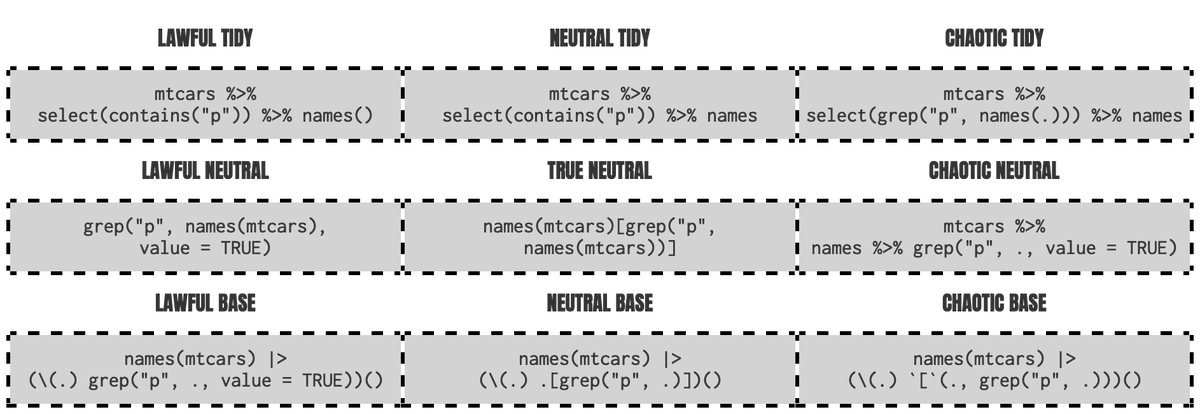
Benefits of base pipe
- Magrittr pipe is bloated with special features which may make it slower than the base pipe
- If not using tidyverse, it’s one less dependency (maybe one day it will be deprecated in tidyverse)
Base pipe with base and anonymous functions
# verbosely mtcars |> (function(.) plot(.$hp, .$mpg))() # using the anonymous function shortcut, emulating the dot syntax mtcars |> (\(.) plot(.$hp, .$mpg))() # or if you prefer x to . mtcars |> (\(x) plot(x$hp, x$mpg))() # or if you prefer to be explicit with argument names mtcars |> (\(data) plot(data$hp, data$mpg))()Using “_” placeholder:
mtcars |> lm(mpg ~ disp, data = _)mtcars |> lm(mpg ~ disp, data = _) |> _$coef
Base pipe .[ ] hack
wiki |> read_html() |> html_nodes("table") |> (\(.) .[[2]])() |> html_table(fill = TRUE) |> clean_names() # instead of djia <- wiki %>% read_html() %>% html_nodes("table") %>% .[[2]] %>% html_table(fill = TRUE) %>% clean_names()Magrittr, base pipe differences
- magrittr: %>% allows you change the placement with a . placeholder.
- base: R 4.2.0 added a _ placeholder to the base pipe, with one additional restriction: the argument has to be named
- magrittr: With %>% you can use . on the left-hand side of operators like “\(", \[\[, \[ and use in multiple arguments (e.g. df %>% {split(.\)x, .$y))
- base: can hack this by using anonymous function
- see Base pipe with base and anonymous functions above
- see Base pipe .[ ] hack above
- base: can hack this by using anonymous function
- magrittr: %>% allows you to drop the parentheses when calling a function with no other arguments (e.g. dat %>% distinct)
- base: |> always requires the parentheses. (e.g. dat |> distinct())
- magrittr: %>% allows you to start a pipe with . to create a function rather than immediately executing the pipe
- magrittr: %>% allows you change the placement with a . placeholder.
Purrr with base pipe
data_list |> map(\(x) clean_names(x)) # instead of data_list %>% map( ~.x %>% clean_names) # with split star |> split(~variable) |> map_df(\(.) hedg_g(., reading ~ value), .id = "variable") # instead of star %>% split(.$variable) %>% map_df(. %>% hedg_g(., reading ~ value), .id = "variable")
Strings
Resources
- From base R - base R equivalents to {stringr} functions
sprintfx <- 123.456 # Create example data sprintf("%f", x) # sprintf with default specification #> [1] "123.456000" sprintf("%.10f", x) # sprintf with ten decimal places #> [1] "123.4560000000" sprintf("%.2f", x) # sprintf with two rounded decimal places #> [1] "123.46" sprintf("%1.0f", x) # sprintf without decimal places #> [1] "123" sprintf("%10.0f", x) # sprintf with space before number #> [1] " 123" sprintf("%10.1f", x) # Space before number & decimal places #> [1] " 123.5" sprintf("%-15f", x) # Space on right side #> [1] "123.456000 " sprintf("%+f", x) # Print plus sign before number #> [1] "+123.456000" sprintf("%e", x) # Exponential notation #> [1] "1.234560e+02" sprintf("%E", x) # Exponential with upper case E #> [1] "1.234560E+02" sprintf("%g", x) # sprintf without decimal zeros #> [1] "123.456" sprintf("%g", 1e10 * x) # Scientific notation #> [1] "1.23456e+12" sprintf("%.13g", 1e10 * x) # Fixed decimal zeros #> [1] "1234560000000" paste0(sprintf("%f", x), # Print %-sign at the end of number "%") #> [1] "123.456000%" sprintf("Let's create %1.0f more complex example %1.0f you.", 1, 4) #> [1] "Let's create 1 more complex example 4 you."str2lang- Allows you to turn plain text into code.growth_rate <- "circumference / age" class(str2lang(growth_rate)) #> [1] "call"Example: Basic
eval(str2lang("2 + 2")) #> [1] 4 eval(str2lang("x <- 3")) x #> [1] 3Example: Run formula against a df
growth_rate <- "circumference / age" with(Orange, eval(str2lang(growth_rate))) #> [1] 0.25423729 0.11983471 0.13102410 0.11454183 0.09748172 0.10349854 #> [7] 0.09165613 0.27966102 0.14256198 0.16716867 0.15537849 0.13972380 #> [13] 0.14795918 0.12831858 0.25423729 0.10537190 0.11295181 0.10756972 #> [19] 0.09341998 0.10131195 0.08849558 0.27118644 0.12809917 0.16867470 #> [25] 0.16633466 0.14541024 0.15233236 0.13527181 0.25423729 0.10123967 #> [31] 0.12198795 0.12450199 0.11535337 0.12682216 0.11188369
Conditionals
&& and || are intended for use solely with scalars, they return a single logical value.
- Since they always return a scalar logical, you should use && and || in your if/while conditional expressions (when needed). If an & or | is used, you may end up with a non-scalar vector inside if (…) {} and R will throw an error.
& and | work with multivalued vectors, they return a vector whose length matches their input arguments.
Alternative way of negating a condition or set of conditions:
if (!(condition))Makes it less readable IMO, but maybe for a complicated set of conditions if makes more sense in your head to do it this way
Example
if (!(nr == nrow(iris) || (nr == nrow(iris) - 2))) {print("moose")}
Using
else ifif (condition1) { expr1 } else if (condition2) { expr2 } else { expr3 }stopifnotpred_fn <- function(steps_forward, newdata) { stopifnot(steps_forward >= 1) stopifnot(nrow(newdata) == 1) model_f = model_map[[steps_forward]] # apply the model to the last "before the test period" row to get # the k-steps_forward prediction as.numeric(predict(model_f, newdata = newdata)) }%||%Collapse operator which acts like:
`%||%` <- function(x, y) { if (is_null(x)) y else x }- Says if the first (left-hand) input
xisNULL, returny. Ifxis notNULL, return the input
- Says if the first (left-hand) input
Use Cases
Determine whether a function argument is NULL
github_remote <- function(repo, username = NULL, ...) { meta <- parse_git_repo(repo) meta$username <- username %||% getOption("github.user") %||% stop("Unknown username") }Within the
printargument collapselibrary(rlang) add_commas <- function(x) { if (length(x) <= 1) { collapse_arg <- NULL } else { collapse_arg <- ", " } print(paste0(x, collapse = collapse_arg %||% "")) } add_commas(c("apples")) [1] "apples" add_commas(c("apples", "bananas")) [1] "apples, bananas"
Ordering Columns and Sorting Rows
Ascending:
df[with(df, order(col2)), ] # or df[order(df$col2), ] # or sort_by(df, df$col2)- col2 is the column used to sort the df by
Descending:
df[with(df, order(-col2)), ]By Multiple Columns
- Sequentially:
sort_by(df, df$col1, df$col2, df$col3)- Says sort by col1 then col2 then col3
- Descending then Ascending:
df[with(df, order(-col2, id)), ]
- Sequentially:
Change position of columns
# Reorder column by index manually df2 <- df[, c(5, 1, 4, 2, 3)] df3 <- df[, c(1, 5, 2:4)] # Reorder column by name manually new_order = c("emp_id","name","superior_emp_id","dept_id","dept_branch_id") df2 <- df[, new_order]
Set Operations
Unique values in A that are not in B
a <- c("thing", "object") b <- c("thing", "gift") unique(a[!(a %in% b)]) #> [1] "object" setdiff(a, b)setdiffis slower
Unique values of the two vectors combined
unique(c(a, b)) #> [1] "thing" "object" "gift" union(a, b)unionis just a wrapper forunique
Subsetting
Lists and Vectors
Removing Rows
# Remove specific value from vector x[!x == 'A'] # Remove multiple values by list x[!x %in% c('A', 'D', 'E')] # Using setdiff setdiff(x, c('A','D','E')) # Remove elements by index x[-c(1,2,5)] # Using which x[-which(x %in% c('D','E') )] # Remove elements by name x <- c(C1='A',C2='B',C3='C',C4='E',C5='G') x[!names(x) %in% c('C1','C2')]
Dataframes
Remove specific Rows
df <- df[-c(25, 3, 62), ]Remove column by name
df <- df[, which(names(df) == "col_name")] df <- subset(df, select = -c(col_name)) df <- df[, !names(df) %in% c("col1", "col2"), drop = FALSE]Filter and Select
df <- subset(df, subset = col1 > 56, select = c(col2, col3))
Joins
- Inner join:
inner <- merge(flights, weather, by = mergeCols) - Left (outer) join:
left <- merge(flights, weather, by = mergeCols, all.x = TRUE) - Right (outer) join:
right <- merge(flights, weather, by = mergeCols, all.y = TRUE) - Full (outer) join:
full <- merge(flights, weather, by = mergeCols, all = TRUE) - Cross Join (Cartesian product):
cross <- merge(flights, weather, by = NULL) - Natural join:
natural <- merge(flights, weather)
Error Handling
stopExample:
switch(parallel, windows = "snow" -> para_proc, other = "multicore" -> para_proc, no = "no" -> para_proc, stop(sprintf("%s is not one of the 3 possible parallel argument values. See documentation.", parallel)))- parallel is the function argument. If it doesn’t match one of the 3 values, then an error is thrown.
tryIf something errors, then do something else
Example
current <- try(remDr$findElement(using = "xpath", '//*[contains(concat( " ", @class, " " ), concat( " ", "product-price-value", " " ))]'), silent = T) #If error : current price is NA if(class(current) =='try-error'){ currentp[i] <- NA } else { # do stuff }
tryCatchRun the main code, but if it “catches” an error, then the secondary code (the workaround) will run.
Example: Basic
for (r in 1:nrow(res)) { cat(r, "\n") tmp_wikitext <- get_wikitext(res$film[r], res$year[r]) # skip if get_wikitext fails if (is.na(tmp_wikitext)) next if (length(tmp_wikitext) == 0) next # give the text to openai tmp_chat <- tryCatch( get_results(client, tmp_wikitext), error = \(x) NA ) # if openai returned a dict of 2 if (length(tmp_chat) == 2) { res$writer[r] <- tmp_chat$writer res$producer[r] <- tmp_chat$producer } }get_resultsis called during each iteration, and if there’s an error a NA is returned.
Example
pct_difference_error_handling <- function(n1, n2) { # Try the main code tryCatch(pct_diff <- (n1-n2)/n1, # If you find an error, use this code instead error = return( cat( 'The difference between', as.integer(n1), 'and', as.integer(n2), 'is', (as.integer(n1)-as.integer(n2)), 'which is', 100*(as.integer(n1)-as.integer(n2))/as.integer(n1), '% of', n1 )#cat ), # finally = print('Code ended') # optional )#trycatch # If no error happens, return this statement return ( cat('The difference between', n1, 'and', n2, 'is', n1-n2, ', which is', pct_diff*100, '% of', n1) ) }- Assumes the error will be the user enters a string instead of a numeric. If errors, converts string to numeric and calcs.
- “finally” - This argument will always run, regardless if the try block raises an error or not. So it could be a completion message or a summary, for example.
Models
reformulate- Create formula sytax programmatically# Creating a formula using reformulate() formula <- reformulate(c("hp", "cyl"), response = "mpg") # Fitting a linear regression model model <- lm(formula, data = mtcars) formula ##> mpg ~ hp + cyl- Can also use
as.formula
- Can also use
DF2formula- Turns the column names from a data frame into a formula. The first column will become the outcome variable, and the rest will be used as predictorsDF2formula(Orange) #> Tree ~ age + circumferenceformula- Provides a way of extracting formulae which have been included in other objectsrec_obj |> prep() |> formula()- Where “rec_obj” is a tidymodels recipe object
Data from Model Object
model$modelreturn the data dataframedeparse(model$call$data)gives you that name of your data object as a string.model$call$datagives you the data as an unevaluated symbol;
eval(model$call$data)gives you back the original data object, if it is available in the current environment.